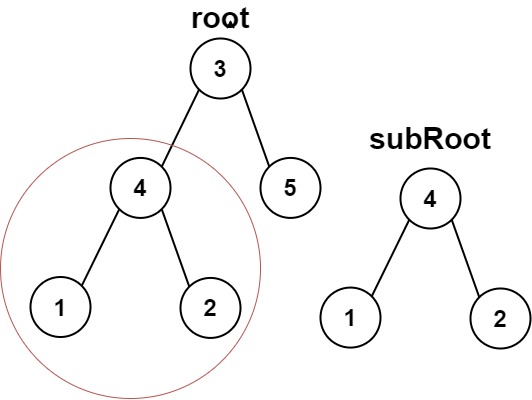
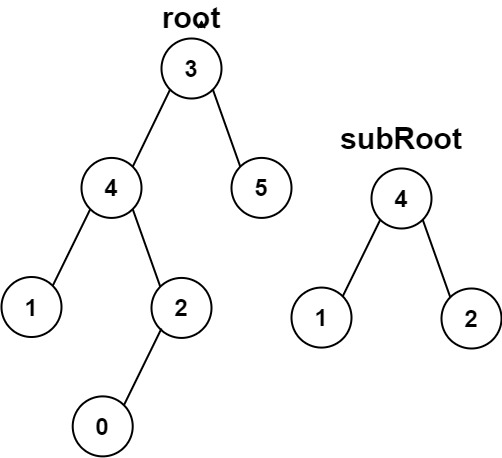
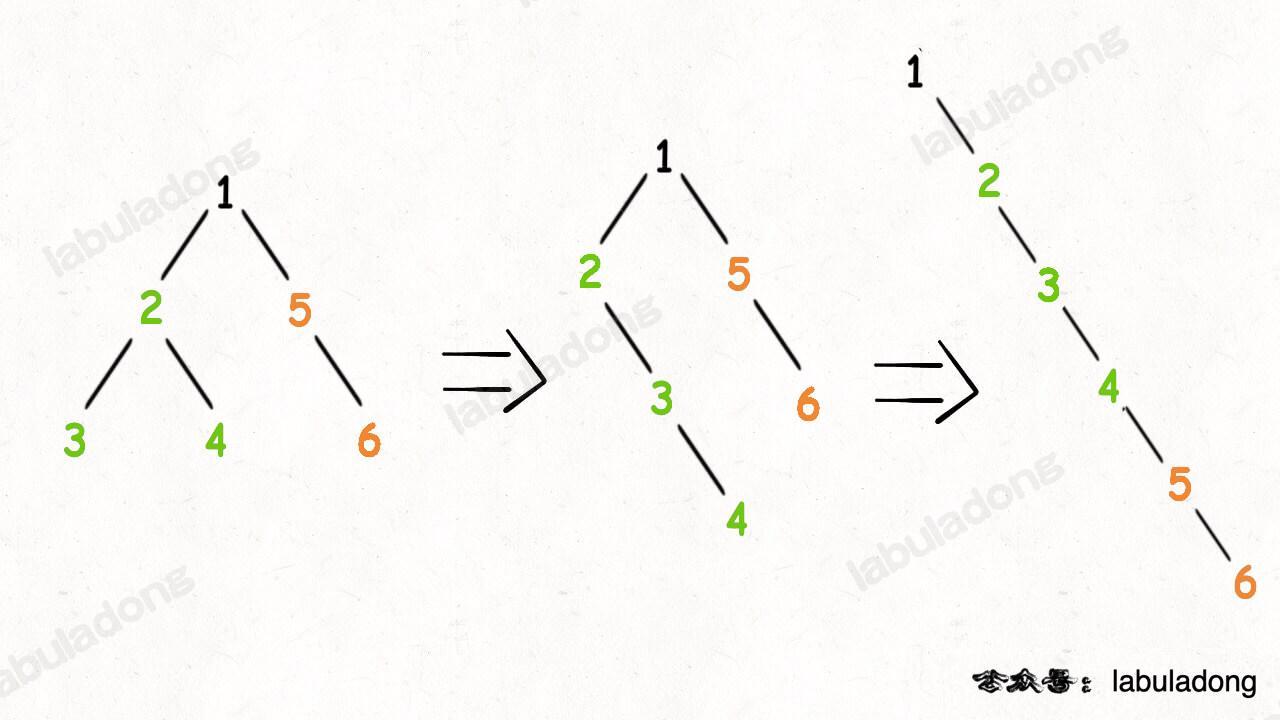
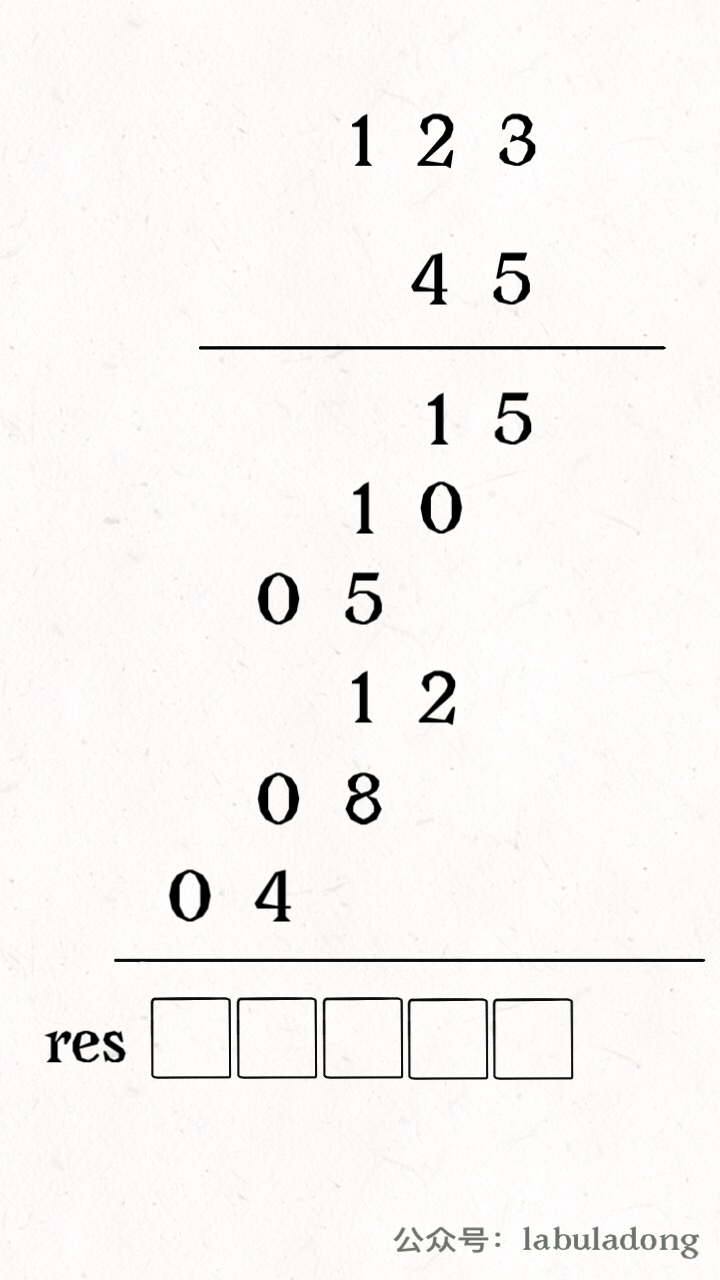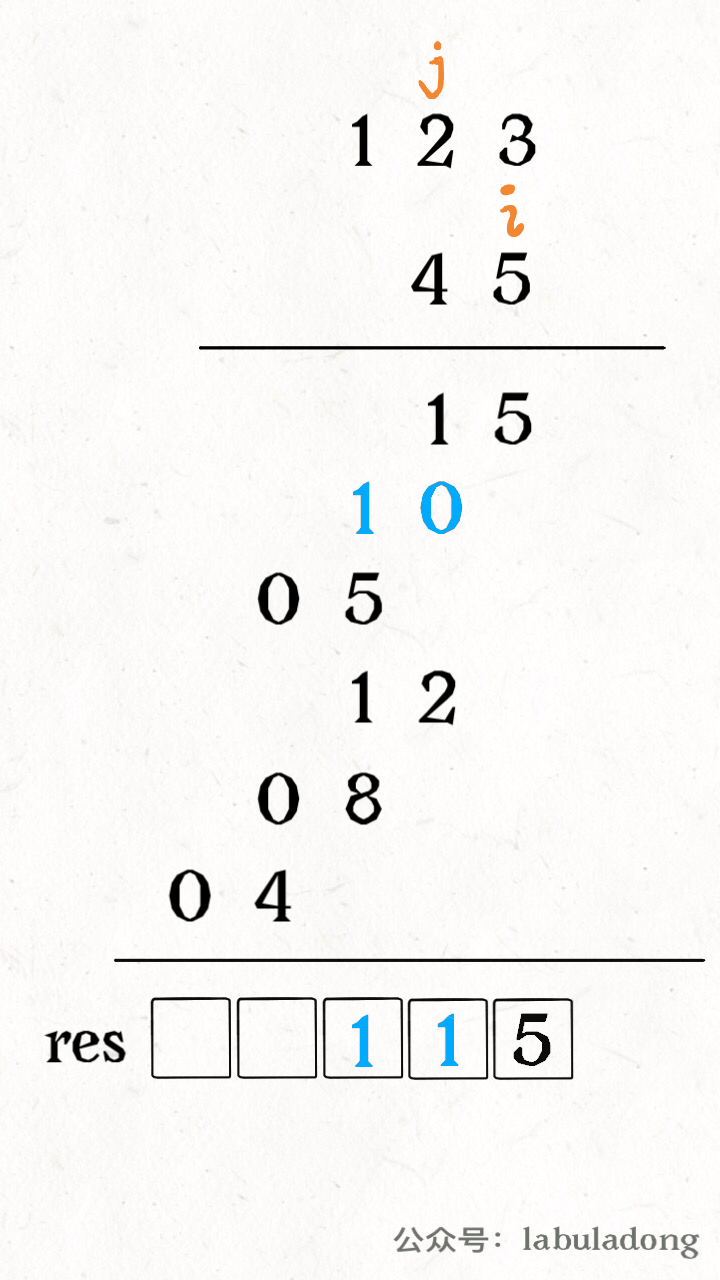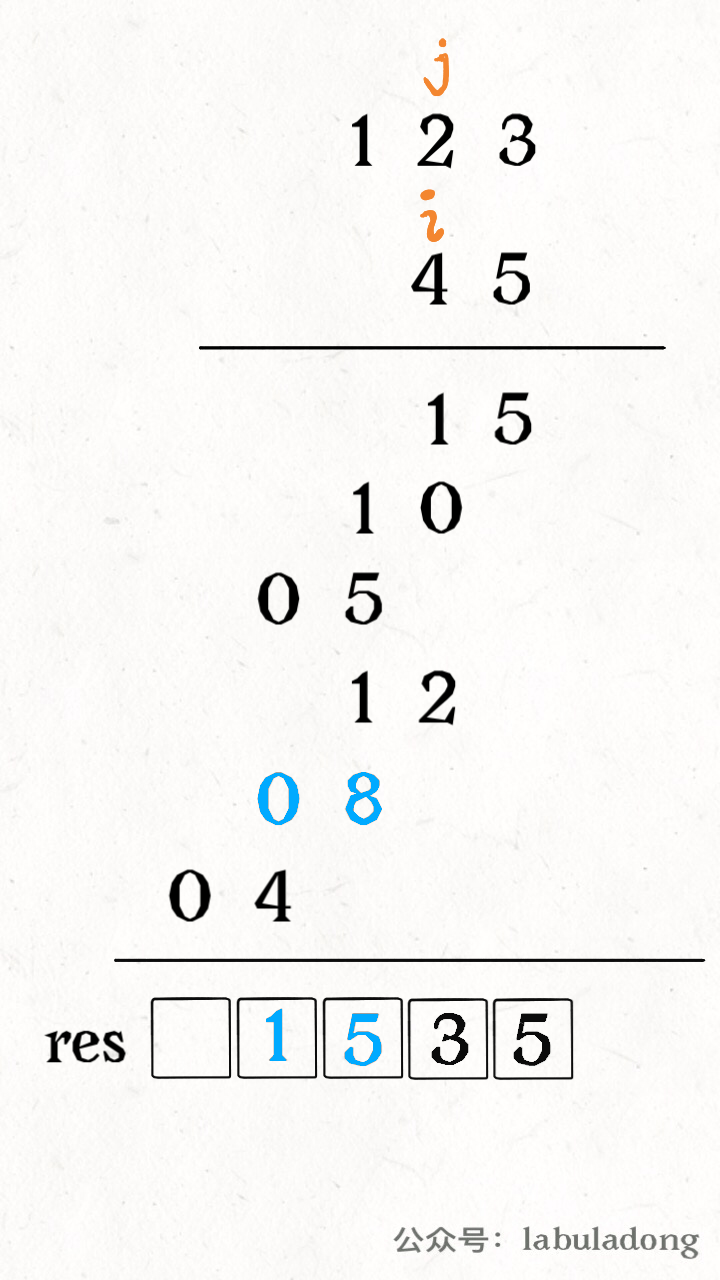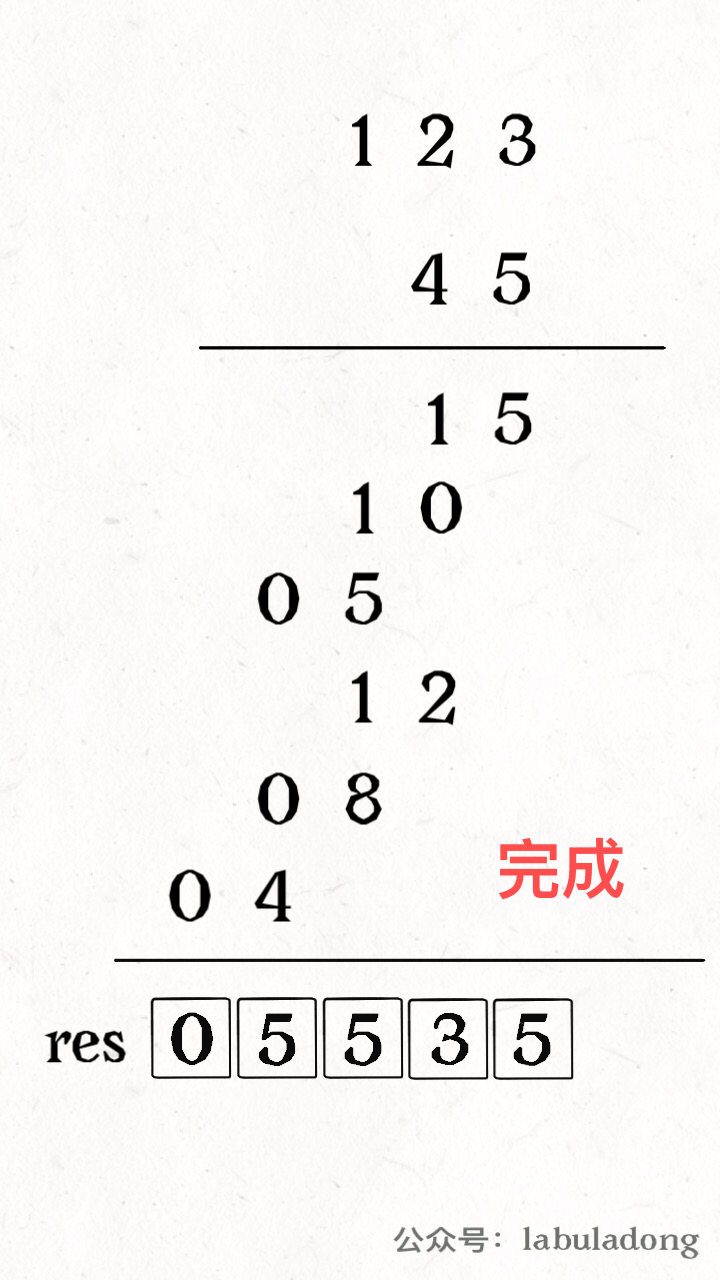数构&算法:数据结构
算法 数据结构
线性结构:数组、队列、链表、栈
非线性结构:二维数组、多维数组、广义表、树、图
必看:学习算法和刷题的框架思维 :: labuladong的算法小抄 、我的刷题心得 :: labuladong的算法小抄
①数组
❶稀疏数组
稀疏数组是一种用来压缩数据量的数据结构,简而言之,就是记录特殊值,然后剩下大量重复的数据可以消减。
例如下方是一个普通二维数组
1 2 3 4 5 6 0 0 0 0 0 0 0 0 1 0 0 0 0 0 0 2 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0
这么一个二维数组,化成稀疏数组可以表示为:
1 2 3 4 5 6 7 8 行 列 值 0 6 6 2 1 1 2 1 2 2 3 2 1. 稀疏数组第一行表示原数组有多少行,多少列,有多少个非零元素(有效值) 2. 稀疏数组是从0开始的 3. 稀疏数组的行数等于有效值+1,列数固定都为3
二维数组转稀疏数组的步骤:
遍历二维数组,得到有效值个数 sum
根据 sum 创建稀疏数组 sparseArr = int [sum+1][3]
将有效值存入稀疏数组
还原稀疏数组步骤:
创建一个新的数组,其行和列等于稀疏数组首行数据
遍历稀疏数组,将对应数值赋值给新的数组
最后可以验证一下原始的数组和还原后的数组是否相等
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 public class SparseArray { public static void main (String[] args) { int [][] chessArr = new int [6 ][6 ]; chessArr[1 ][2 ] = 1 ; chessArr[2 ][3 ] = 2 ; System.out.println("原始数组:" ); for (int [] row : chessArr) { for (int data : row) { System.out.print(data+"\t" ); } System.out.println(); } System.out.println("====================" ); int sum = 0 ; for (int i = 0 ; i < chessArr.length; i++) { for (int j = 0 ; j < chessArr[0 ].length; j++) { if (chessArr[i][j] != 0 ) { sum++; } } } int [][]sparseArr = new int [sum+1 ][3 ]; sparseArr[0 ][0 ] = chessArr.length; sparseArr[0 ][1 ] = chessArr[0 ].length; sparseArr[0 ][2 ] = sum; int count = 0 ; for (int i = 0 ; i < chessArr.length; i++) { for (int j = 0 ; j < chessArr[0 ].length; j++) { if (chessArr[i][j] != 0 ){ count++; sparseArr[count][0 ] = i; sparseArr[count][1 ] = j; sparseArr[count][2 ] = chessArr[i][j]; } } } System.out.println("稀疏数组:" ); for (int i = 0 ; i < sparseArr.length; i++) { System.out.println(sparseArr[i][0 ]+"\t" +sparseArr[i][1 ]+"\t" +sparseArr[i][2 ]+"\t" ); } int [][] ChessArr2 = new int [sparseArr[0 ][0 ]][sparseArr[0 ][1 ]]; for (int i = 1 ; i < sparseArr.length; i++) { ChessArr2[sparseArr[i][0 ]][sparseArr[i][1 ]] = sparseArr[i][2 ]; } System.out.println("=======================" ); System.out.println("输出还原后的数组:" ); for (int [] row : ChessArr2) { for (int data : row) { System.out.print(data+"\t" ); } System.out.println(); } int flag = 0 ; for (int i = 0 ; i < chessArr.length; i++) { if (!Arrays.equals(chessArr[i],ChessArr2[i])){ flag++; } } if (flag==0 ){ System.out.println("初始数组和还原后的数组相等" ); } } }
❷数组模拟队列
队列本身是有序列表,若使用数组的结构来存储队列的数据,则队列数组的声明如下图
maxSize 是该队列的最大容量,两个变量 front 及 rear 分别记录队列前后端的下标
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 class ArrayQueue { private int MaxSize; private int front; private int rear; private int [] arr; public ArrayQueue (int MaxSize) { this .MaxSize = MaxSize; arr = new int [this .MaxSize]; front = -1 ; rear = -1 ; } public boolean isFull () { return rear == MaxSize - 1 ; } public boolean isEmpty () { return rear == front; } public void addQueue (int num) { if (isFull()) { System.out.println("队列已满,无法在进行入队操作" ); return ; } arr[++rear] = num; } public int getQueue () { if (isEmpty()) { throw new RuntimeException ("队列为空,无法出队" ); } return arr[++front]; } public void showQueue () { if (isEmpty()) { throw new RuntimeException ("队列为空,无法遍历" ); } for (int i = front+1 ; i < arr.length; i++) { System.out.printf("arr[%d]=%d\n" , i, arr[i]); } } public int headQueue () { if (isEmpty()) { throw new RuntimeException ("队列为空,没有数据" ); } return arr[front + 1 ]; } }
测试
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 public class ArrayQueueDemo { public static void main (String[] args) { ArrayQueue queue = new ArrayQueue (5 ); queue.addQueue(1 ); queue.addQueue(2 ); queue.addQueue(3 ); queue.addQueue(4 ); queue.addQueue(5 ); System.out.println(queue.getQueue()); queue.showQueue(); System.out.println(queue.headQueue()); } }
❸LeetCode真题
给定一个 n 个元素有序的(升序)整型数组 nums 和一个目标值 target ,写一个函数搜索 nums 中的 target,如果目标值存在返回下标,否则返回 -1。
示例 1:
1 2 3 输入 : nums = [-1,0,3,5,9,12], target = 9 输出 : 4 解释 : 9 出现在 nums 中并且下标为 4
示例 2:
1 2 3 输入 : nums = [-1,0,3,5,9,12], target = 2 输出 : -1 解释 : 2 不存在 nums 中因此返回 -1
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 class Solution { public int search (int [] nums, int target) { if (target < nums[0 ] || target > nums[nums.length - 1 ]) { return -1 ; } int left = 0 ; int right = nums.length - 1 ; while (left <= right){ int mid = left + ((right - left) >> 1 ); if (nums[mid] == target){ return mid; } else if (nums[mid] < target){ left = mid + 1 ; } else { right = mid -1 ; } } return -1 ; } }
给你一个数组 nums 和一个值 val,你需要原地移除所有数值等于 val 的元素,并返回移除后数组的新长度。
不要使用额外的数组空间,你必须仅使用 O(1) 额外空间并原地修改输入数组。
元素的顺序可以改变。你不需要考虑数组中超出新长度后面的元素。
示例 1:
1 2 3 输入:nums = [3,2,2,3], val = 3 输出:2, nums = [2,2] 解释:函数应该返回新的长度 2, 并且 nums 中的前两个元素均为 2。你不需要考虑数组中超出新长度后面的元素。例如,函数返回的新长度为 2 ,而 nums = [2,2,3,3] 或 nums = [2,2,0,0],也会被视作正确答案。
示例 2:
1 2 3 输入:nums = [0,1,2,2,3,0,4,2], val = 2 输出:5, nums = [0,1,4,0,3] 解释:函数应该返回新的长度 5, 并且 nums 中的前五个元素为 0, 1, 3, 0, 4。注意这五个元素可为任意顺序。你不需要考虑数组中超出新长度后面的元素。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 class Solution { public int removeElement (int [] nums, int val) { int slow = 0 ; for (int fast = 0 ; fast < nums.length; fast++){ if (nums[fast] != val){ nums[slow] = nums[fast]; slow++; } } return slow; } } class Solution { public int removeElement (int [] nums, int val) { int idx = 0 ; for (int x : nums) { if (x != val) nums[idx++] = x; } return idx; } }
给你一个按 非递减顺序 排序的整数数组 nums,返回 每个数字的平方 组成的新数组,要求也按 非递减顺序 排序。
示例 1:
1 2 3 4 输入:nums = [-4,-1,0,3,10] 输出:[0,1,9,16,100] 解释:平方后,数组变为 [16,1,0,9,100] 排序后,数组变为 [0,1,9,16,100]
示例 2:
1 2 输入:nums = [-7,-3,2,3,11] 输出:[4,9,9,49,121]
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 class Solution { public int [] sortedSquares(int [] nums) { for (int i = 0 ; i < nums.length; i++){ nums[i] = nums[i] * nums[i]; } Arrays.sort(nums); return nums; } } class Solution { public int [] sortedSquares(int [] nums) { int [] res = new int [nums.length]; int i = 0 , j = nums.length - 1 , k = nums.length - 1 ; while (i <= j){ if (nums[i] * nums[i] > nums[j] * nums[j]){ res[k--] = nums[i] * nums[i]; i++; } else { res[k--] = nums[j] * nums[j]; j--; } } return res; } }
给你两个按 非递减顺序 排列的整数数组 nums1 和 nums2,另有两个整数 m 和 n ,分别表示 nums1 和 nums2 中的元素数目。
请你 合并 nums2 到 nums1 中,使合并后的数组同样按 非递减顺序 排列。
**注意:**最终,合并后数组不应由函数返回,而是存储在数组 nums1 中。为了应对这种情况,nums1 的初始长度为 m + n,其中前 m 个元素表示应合并的元素,后 n 个元素为 0 ,应忽略。nums2 的长度为 n 。
示例 1:
1 2 3 4 输入:nums1 = [1,2,3,0,0,0], m = 3, nums2 = [2,5,6], n = 3 输出:[1,2,2,3,5,6] 解释:需要合并 [1,2,3] 和 [2,5,6] 。 合并结果是 [1,2,2,3,5,6] ,其中斜体加粗标注的为 nums1 中的元素。
示例 2:
1 2 3 4 输入:nums1 = [1], m = 1, nums2 = [], n = 0 输出:[1] 解释:需要合并 [1] 和 [] 。 合并结果是 [1] 。
示例 3:
1 2 3 4 5 输入:nums1 = [0], m = 0, nums2 = [1], n = 1 输出:[1] 解释:需要合并的数组是 [] 和 [1] 。 合并结果是 [1] 。 注意,因为 m = 0 ,所以 nums1 中没有元素。nums1 中仅存的 0 仅仅是为了确保合并结果可以顺利存放到 nums1 中。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 class Solution { public void merge (int [] nums1, int m, int [] nums2, int n) { int i = m - 1 , j = n - 1 ; int t = nums1.length - 1 ; while (i >= 0 && j >= 0 ){ if (nums1[i] > nums2[j]){ nums1[t--] = nums1[i--]; } else { nums1[t--] = nums2[j--]; } } while (j >= 0 ){ nums1[t--] = nums2[j--]; } } }
给定一个含有 n 个正整数的数组和一个正整数 target 。
找出该数组中满足其和 ≥ target 的长度最小的 连续子数组 [numsl, numsl+1, …, numsr-1, numsr],并返回其长度**。**如果不存在符合条件的子数组,返回 0
示例 1:
1 2 3 输入:target = 7, nums = [2,3,1,2,4,3] 输出:2 解释:子数组 [4,3] 是该条件下的长度最小的子数组。
示例 2:
1 2 输入:target = 4, nums = [1,4,4] 输出:1
示例 3:
1 2 输入:target = 11, nums = [1,1,1,1,1,1,1,1] 输出:0
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 class Solution { public int minSubArrayLen (int target, int [] nums) { int res = Integer.MAX_VALUE; int sum = 0 ; int sumLen = 0 ; for (int i = 0 ; i < nums.length; i++){ sum = 0 ; for (int j = i; j < nums.length; j++){ sum += nums[j]; if (sum >= target){ sumLen = j - i + 1 ; res = res > sumLen ? sumLen : res; break ; } } } return res == Integer.MAX_VALUE ? 0 : res; } } class Solution { public int minSubArrayLen (int s, int [] nums) { int left = 0 ; int sum = 0 ; int result = Integer.MAX_VALUE; for (int right = 0 ; right < nums.length; right++) { sum += nums[right]; while (sum >= s) { result = Math.min(result, right - left + 1 ); sum -= nums[left]; left++; } } return result == Integer.MAX_VALUE ? 0 : result; } }
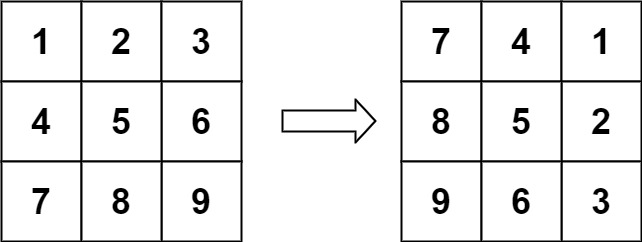
给定一个 n × n 的二维矩阵 matrix 表示一个图像。请你将图像顺时针旋转 90 度。
你必须在** 原地 ** 旋转图像,这意味着你需要直接修改输入的二维矩阵。请不要 使用另一个矩阵来旋转图像。
示例 1:
1 2 输入:matrix = [[1,2,3],[4,5,6],[7,8,9]] 输出:[[7,4,1],[8,5,2],[9,6,3]]
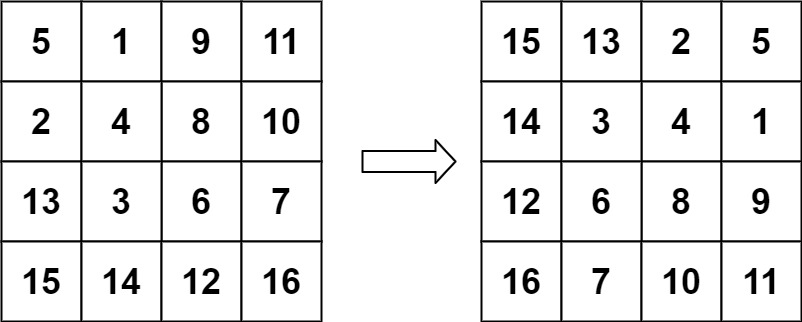
示例 2:
1 2 输入:matrix = [[5,1,9,11],[2,4,8,10],[13,3,6,7],[15,14,12,16]] 输出:[[15,13,2,5],[14,3,4,1],[12,6,8,9],[16,7,10,11]]
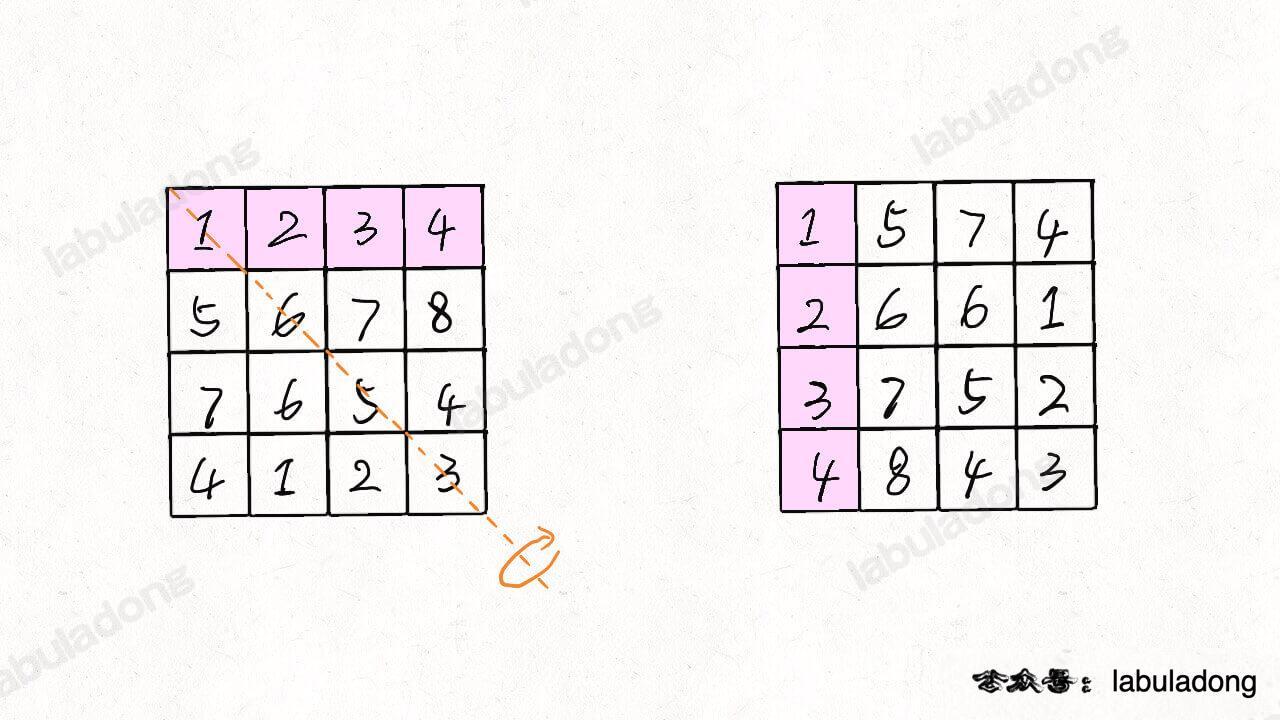
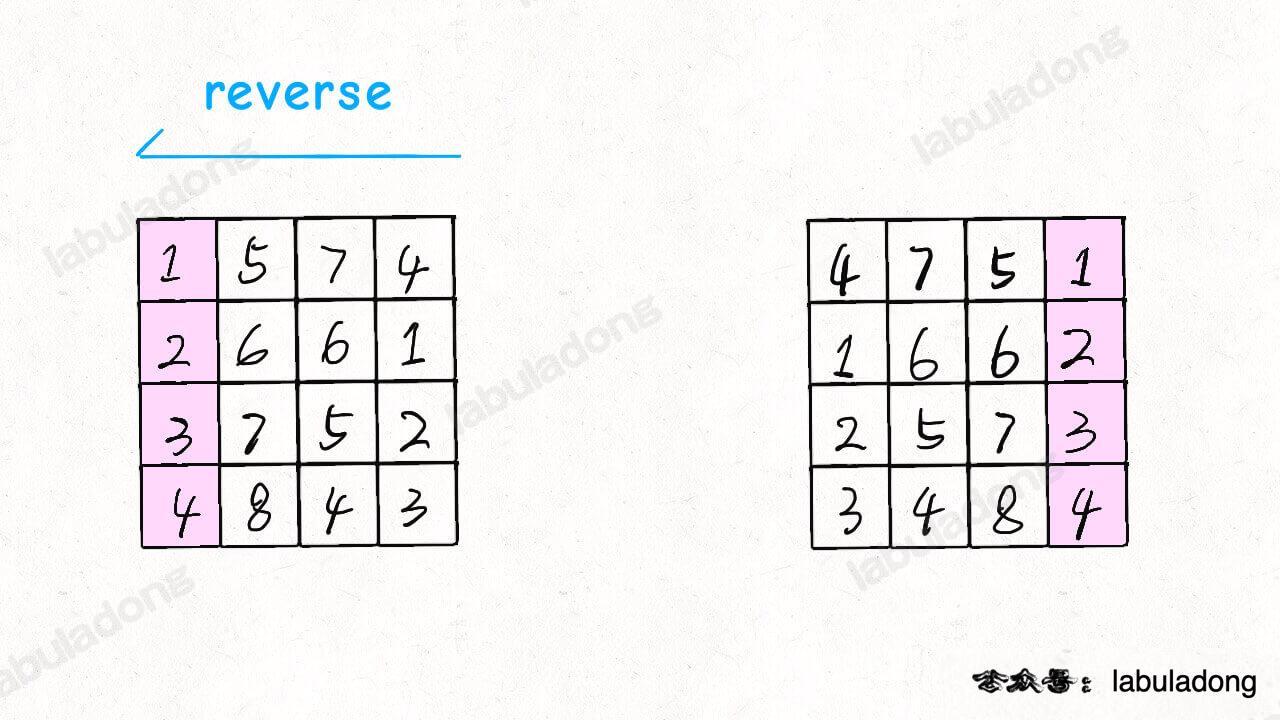
本题是顺时针旋转,逆时针旋转思路一样
**规律:**先把二维矩阵沿对角线反转,然后反转矩阵的每一行,结果就是顺时针反转整个矩阵。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 class Solution { public void rotate (int [][] matrix) { int n = matrix.length; for (int i = 0 ; i < n; i++) { for (int j = i; j < n; j++) { int temp = matrix[i][j]; matrix[i][j] = matrix[j][i]; matrix[j][i] = temp; } } for (int [] row : matrix) { reverse(row); } } void reverse (int [] arr) { int i = 0 , j = arr.length - 1 ; while (j > i) { int temp = arr[i]; arr[i] = arr[j]; arr[j] = temp; i++; j--; } } } class Solution { void rotate2 (int [][] matrix) { int n = matrix.length; for (int i = 0 ; i < n; i++) { for (int j = 0 ; j < n - i; j++) { int temp = matrix[i][j]; matrix[i][j] = matrix[n - j - 1 ][n - i - 1 ]; matrix[n - j - 1 ][n - i - 1 ] = temp; } } for (int [] row : matrix) { reverse(row); } } void reverse (int [] arr) { } }
剑指 Offer 29. 顺时针打印矩阵
给你一个 m 行 n 列的矩阵 matrix ,请按照 顺时针螺旋顺序 ,返回矩阵中的所有元素。
示例 1:
1 2 输入:matrix = [[1,2,3],[4,5,6],[7,8,9]] 输出:[1,2,3,6,9,8,7,4,5]
示例 2:
1 2 输入:matrix = [[1,2,3,4],[5,6,7,8],[9,10,11,12]] 输出:[1,2,3,4,8,12,11,10,9,5,6,7]
解题的核心思路是按照右、下、左、上的顺序遍历数组,并使用四个变量圈定未遍历元素的边界
打印方向
1. 根据边界打印
2. 边界向内收缩
3. 是否打印完毕
从左向右
左边界l ,右边界 r
上边界 t 加 1
是否 t > b
从上向下
上边界 t ,下边界b
右边界 r 减 1
是否 l > r
从右向左
右边界 r ,左边界l
下边界 b 减 1
是否 t > b
从下向上
下边界 b ,上边界t
左边界 l 加 1
是否 l > r
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 class Solution { public List<Integer> spiralOrder (int [][] matrix) { List<Integer> res = new ArrayList <>(); int n = matrix[0 ].length, m = matrix.length; int l = 0 , r = n - 1 , t = 0 , b = m - 1 ; while (res.size() < m * n){ if (t <= b){ for (int i = l; i <= r; i++) res.add(matrix[t][i]); t++; } if (l <= r){ for (int i = t; i <= b; i++) res.add(matrix[i][r]); r--; } if (t <= b){ for (int i = r; i >= l; i--) res.add(matrix[b][i]); b--; } if (l <= r){ for (int i = b; i >= t; i--) res.add(matrix[i][l]); l++; } } return res; } }
给你一个正整数 n ,生成一个包含 1 到 n^2 所有元素,且元素按顺时针顺序螺旋排列的 n x n 正方形矩阵 matrix 。
示例 1:
1 2 输入:n = 3 输出:[[1,2,3],[8,9,4],[7,6,5]]
示例 2:
思路:
生成一个
空矩阵
,随后模拟整个向内环绕的填入过程:
定义当前左右上下边界 l,r,t,b,初始值 num = 1,迭代终止值 end = n * n;
当
时,始终按照
填入顺序循环,每次填入后:
执行 num += 1:得到下一个需要填入的数字;
更新边界:例如从左到右填完后,上边界 t += 1,相当于上边界向内缩 1。
使用num <= end而不是l < r || t < b作为迭代条件,是为了解决当n为奇数时,矩阵中心数字无法在迭代过程中被填充的问题。
最终返回 res 即可。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 class Solution { public int [][] generateMatrix(int n) { int l = 0 , r = n - 1 , t = 0 , b = n - 1 ; int [][] res = new int [n][n]; int num = 1 ; while (num <= n * n){ if (t <= b){ for (int i = l; i <= r; i++) res[t][i] = num++; t++; } if (l <= r){ for (int i = t; i <= b; i++) res[i][r] = num++; r--; } if (t <= b){ for (int i = r; i >= l; i--) res[b][i] = num++; b--; } if (l <= r){ for (int i = b; i >= t; i--) res[i][l] = num++; l++; } } return res; } }
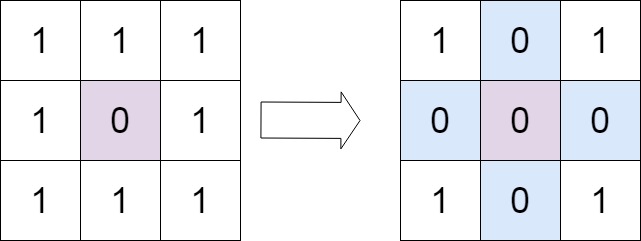
给定一个 m*n 的矩阵,如果一个元素为 0 ,则将其所在行和列的所有元素都设为 0 。请使用 原地
示例 1:
1 2 输入:matrix = [[1,1,1],[1,0,1],[1,1,1]] 输出:[[1,0,1],[0,0,0],[1,0,1]]
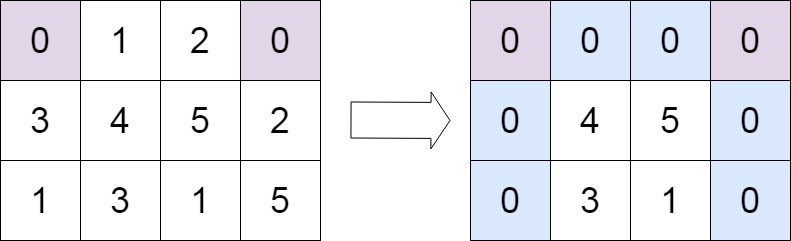
示例 2:
1 2 输入:matrix = [[0,1,2,0],[3,4,5,2],[1,3,1,5]] 输出:[[0,0,0,0],[0,4,5,0],[0,3,1,0]]
思路一: 用 O(m+n)额外空间
两遍扫matrix,第一遍用集合记录哪些行,哪些列有0;第二遍置0
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 class Solution { public void setZeroes (int [][] matrix) { int m = matrix.length, n = matrix[0 ].length; boolean [] row = new boolean [m]; boolean [] col = new boolean [n]; for (int i = 0 ; i < m; i++) { for (int j = 0 ; j < n; j++) { if (matrix[i][j] == 0 ) { row[i] = col[j] = true ; } } } for (int i = 0 ; i < m; i++) { for (int j = 0 ; j < n; j++) { if (row[i] || col[j]) { matrix[i][j] = 0 ; } } } } } class Solution { public void setZeroes (int [][] matrix) { Set<Integer> row_zero = new HashSet <>(); Set<Integer> col_zero = new HashSet <>(); int row = matrix.length; int col = matrix[0 ].length; for (int i = 0 ; i < row; i++) { for (int j = 0 ; j < col; j++) { if (matrix[i][j] == 0 ) { row_zero.add(i); col_zero.add(j); } } } for (int i = 0 ; i < row; i++) { for (int j = 0 ; j < col; j++) { if (row_zero.contains(i) || col_zero.contains(j)) matrix[i][j] = 0 ; } } } }
给定一个数组 nums ,将其划分为两个连续子数组 left 和 right, 使得:
left 中的每个元素都小于或等于 right 中的每个元素。left 和 right 都是非空的。left 的长度要尽可能小。
在完成这样的分组后返回 left 的 长度 。
用例可以保证存在这样的划分方法。
示例 1:
1 2 3 输入:nums = [5,0,3,8,6] 输出:3 解释:left = [5,0,3],right = [8,6]
示例 2:
1 2 3 输入:nums = [1,1,1,0,6,12] 输出:4 解释:left = [1,1,1,0],right = [6,12]
两次遍历:O(n)
先通过一次遍历(从后往前)统计出所有后缀的最小值 minRight(使用数组进行维护)
然后再通过第二次遍历(从前往后)统计每个前缀的最大值 maxLeft(使用单变量进行维护)
第一个满足 maxLeft ≤ minRight[i + 1] 的 i 即为答案,此时 left 的长度为 i+1,因此答案需返回 i+1。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 class Solution { public int partitionDisjoint (int [] nums) { int [] minRight = new int [nums.length]; minRight[nums.length - 1 ] = nums[nums.length - 1 ]; for (int i = nums.length - 2 ; i >= 0 ; i--){ minRight[i] = Math.min(nums[i], minRight[i + 1 ]); } int maxLeft = 0 ; for (int i = 0 ; i < nums.length - 1 ; i++){ maxLeft = Math.max(maxLeft, nums[i]); if (maxLeft <= minRight[i + 1 ]){ return i + 1 ; } } return 0 ; } }
给定一个整数数组 nums 和一个整数目标值 target,请你在该数组中找出 和为目标值 target两个 整数,并返回它们的数组下标。
你可以假设每种输入只会对应一个答案。但是,数组中同一个元素在答案里不能重复出现。
你可以按任意顺序返回答案。
示例 1:
1 2 3 输入:nums = [2,7,11,15], target = 9 输出:[0,1] 解释:因为 nums[0] + nums[1] == 9 ,返回 [0, 1] 。
示例 2:
1 2 输入:nums = [3,2,4], target = 6 输出:[1,2]
示例 3:
1 2 输入:nums = [3,3], target = 6 输出:[0,1]
**进阶:**你可以想出一个时间复杂度小于 O(n2) 的算法吗?
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 class Solution { public int [] twoSum(int [] nums, int target) { for (int i = 0 ; i < nums.length; i++){ for (int j = i + 1 ; j < nums.length; j++){ if (nums[i] + nums[j] == target){ return new int []{i,j}; } } } return new int [0 ]; } } class Solution { public int [] twoSum(int [] nums, int target) { HashMap<Integer,Integer> map = new HashMap <>(); for (int i = 0 ; i < nums.length; i++){ if (map.containsKey(target - nums[i])){ return new int []{map.get(target - nums[i]),i}; } map.put(nums[i],i); } return new int [0 ]; } }
给定一个大小为 n 的数组 nums ,返回其中的多数元素。多数元素是指在数组中出现次数 大于 ⌊ n/2 ⌋ 的元素。
你可以假设数组是非空的,并且给定的数组总是存在多数元素。
示例 1:
示例 2:
1 2 输入:nums = [2,2,1,1,1,2,2] 输出:2
**进阶:**尝试设计时间复杂度为 O(n)、空间复杂度为 O(1) 的算法解决此问题。
方法一:哈希法Map
遍历整个数组,对记录每个数值出现的次数(利用 HashMap,其中 key 为数值,value 为出现次数); 接着遍历 HashMap ,寻找 value > nums.length / 2 的 key 即可。
1 2 3 4 5 6 7 8 9 10 11 12 13 class Solution { public int majorityElement (int [] nums) { Map<Integer, Integer> map = new HashMap <>(); for (int num : nums){ map.put(num, map.getOrDefault(num, 0 ) + 1 ); if (map.get(num) > nums.length / 2 ){ return num; } } return 0 ; } }
方法二:排序法
既然是寻找数组中出现次数 > ⌊ n/2 ⌋ 的元素,那排好序之后的数组中,这个元素占一半还多,则nums[nums.length / 2] 必是要找元素
1 2 3 4 5 6 class Solution { public int majorityElement (int [] nums) { Arrays.sort(nums); return nums[nums.length / 2 ]; } }
方法三:摩尔投票法
我们维护一个候选众数 target 和它出现的次数 count。初始时 target 可以为任意值,count 为 0;
我们遍历数组 nums 中的所有元素,对于每个元素 num,在判断 num 之前,如果 count 的值为 0,我们先将 num 的值赋予 target,随后我们判断 num:
如果 num 与 target 相等,那么计数器 count 的值增加 1;
如果 num 与 target 不等,那么计数器 count 的值减少 1。
在遍历完成后,target 即为整个数组的众数。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 class Solution { public int majorityElement (int [] nums) { int target = 0 ; int count = 0 ; for (int num : nums) { if (count == 0 ) { target = num; count = 1 ; } else if (num == target) { count++; } else { count--; } } return target; } }
给定一个大小为 n 的整数数组,找出其中所有出现超过 ⌊ n/3 ⌋ 次的元素。
示例 1:
1 2 输入:nums = [3,2,3] 输出:[3]
示例 2:
示例 3:
1 2 输入:nums = [1,2] 输出:[1,2]
方法一:哈希法Map
1 2 3 4 5 6 7 8 9 10 11 12 class Solution { public List<Integer> majorityElement (int [] nums) { int n = nums.length; Map<Integer, Integer> map = new HashMap <>(); for (int i : nums) map.put(i, map.getOrDefault(i, 0 ) + 1 ); List<Integer> ans = new ArrayList <>(); for (int i : map.keySet()) { if (map.get(i) > n / 3 ) ans.add(i); } return ans; } }
方法二:摩尔投票法
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 class Solution { public List<Integer> majorityElement (int [] nums) { int target1 = 0 , count1 = 0 ; int target2 = 0 , count2 = 0 ; for (int num : nums) { if (num == target1) { count1++; } else if (num == target2) { count2++; } else if (count1 == 0 ) { target1 = num; count1++; } else if (count2 == 0 ) { target2 = num; count2++; } else { count1--; count2--; } } count1 = 0 ; count2 = 0 ; for (int num : nums) { if (num == target1) { count1++; } else if (num == target2) { count2++; } } List<Integer> list = new ArrayList <> (); if (count1 > nums.length / 3 ) list.add(target1); if (count2 > nums.length / 3 ) list.add(target2); return list; } }
给你一个含 n 个整数的数组 nums ,其中 nums[i] 在区间 [1, n] 内。请你找出所有在 [1, n] 范围内但没有出现在 nums 中的数字,并以数组的形式返回结果。
示例 1:
1 2 输入:nums = [4,3,2,7,8,2,3,1] 输出:[5,6]
示例 2:
**进阶:**你能在不使用额外空间且时间复杂度为 O(n) 的情况下解决这个问题吗? 你可以假定返回的数组不算在额外空间内。
模拟哈希表
拿一个哈希表去记录每个出现过的num,然后遍历一遍哈希表,这样没出现过的num就可以直接保存下来。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 class Solution { public List<Integer> findDisappearedNumbers (int [] nums) { int count[] = new int [nums.length + 1 ]; for (int num : nums){ count[num]++; } List<Integer> list = new ArrayList <>(); for (int i = 1 ; i < count.length; i++){ if (count[i] == 0 ){ list.add(i); } } return list; } }
原地哈希
把对应的值放到正确的位置上,所以,「值不配位」的情况即缺失的位置索引和重复的值数字 。
给你一个整数数组 citations ,其中 citations[i] 表示研究者的第 i 篇论文被引用的次数。计算并返回该研究者的 h 指数
根据维基百科上 h 指数的定义 :h 代表“高引用次数”,一名科研人员的 h指数 是指他(她)的 (n 篇论文中)总共 有 h 篇论文分别被引用了至少 h 次。且其余的 n - h不超过 h
如果 h 有多种可能的值,h 指数
示例 1:
1 2 3 4 输入:citations = [3,0,6,1,5] 输出:3 解释:给定数组表示研究者总共有 5 篇论文,每篇论文相应的被引用了 3, 0, 6, 1, 5 次。 由于研究者有 3 篇论文每篇 至少 被引用了 3 次,其余两篇论文每篇被引用 不多于 3 次,所以她的 h 指数是 3。
示例 2:
1 2 输入:citations = [1,3,1] 输出:1
1 2 3 4 5 6 7 8 9 10 11 12 class Solution { public int hIndex (int [] citations) { Arrays.sort(citations); int h = 0 ; for (int i = citations.length - 1 ; i >= 0 ; i--){ if (citations[i] > h){ h++; } } return h; } }
假设有一个很长的花坛,一部分地块种植了花,另一部分却没有。可是,花不能种植在相邻的地块上,它们会争夺水源,两者都会死去。
给你一个整数数组 flowerbed 表示花坛,由若干 0 和 1 组成,其中 0 表示没种植花,1 表示种植了花。另有一个数 n ,能否在不打破种植规则的情况下种入 n 朵花?能则返回 true ,不能则返回 false 。
示例 1:
1 2 输入:flowerbed = [1,0,0,0,1], n = 1 输出:true
示例 2:
1 2 输入:flowerbed = [1,0,0,0,1], n = 2 输出:false
防御式编程思想:在 flowerbed 数组两端各增加一个 0, 这样处理的好处在于不用考虑边界条件,任意位置处只要连续出现三个 0 就可以栽上一棵花。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 class Solution { public boolean canPlaceFlowers (int [] flowerbed, int n) int [] arr = new int [flowerbed.length + 2 ]; System.arraycopy(flowerbed, 0 , arr, 1 , flowerbed.length); for (int i = 1 ; i < arr.length - 1 ; i++){ if (arr[i - 1 ] == 0 && arr[i] == 0 && arr[i + 1 ] == 0 ){ arr[i] = 1 ; n--; } } return n <= 0 ; } }
给你一个整数数组 nums ,判断这个数组中是否存在长度为 3 的递增子序列。
如果存在这样的三元组下标 (i, j, k) 且满足 i < j < k ,使得 nums[i] < nums[j] < nums[k] ,返回 true ;否则,返回 false 。
示例 1:
1 2 3 输入:nums = [1,2,3,4,5] 输出:true 解释:任何 i < j < k 的三元组都满足题意
示例 2:
1 2 3 输入:nums = [5,4,3,2,1] 输出:false 解释:不存在满足题意的三元组
示例 3:
1 2 3 输入:nums = [2,1,5,0,4,6] 输出:true 解释:三元组 (3, 4, 5) 满足题意,因为 nums[3] == 0 < nums[4] == 4 < nums[5] == 6
假设 first 和 second 是有序的,且开始 first < second,依次遍历,获得 third
如果 third 大于 second,说明满足条件 first < second < third,直接返回
否则看 third 落在哪个区间
first < third,则对 second 进行赋值为 third,这样后续遍历 third > second 就会满足条件first > third,则将 first 进行赋值为 third,因为在数组中肯定有比 second 小的数
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 class Solution { public boolean increasingTriplet (int [] nums) { if (nums.length < 3 ) { return false ; } int first = nums[0 ]; int second = Integer.MAX_VALUE; for (int i = 1 ; i < nums.length; i++) { int third = nums[i]; if (third > second) { return true ; } if (first < third) { second = third; } else { first = third; } } return false ; } }
给你一个字符数组 chars ,请使用下述算法压缩:
从一个空字符串 s 开始。对于 chars 中的每组 连续重复字符 :
如果这一组长度为 1 ,则将字符追加到 s 中。
否则,需要向 s 追加字符,后跟这一组的长度。
压缩后得到的字符串 s 不应该直接返回 ,需要转储到字符数组 chars 中。需要注意的是,如果组长度为 10 或 10 以上,则在 chars 数组中会被拆分为多个字符。
请在 修改完输入数组后 ,返回该数组的新长度。
你必须设计并实现一个只使用常量额外空间的算法来解决此问题。
示例 1:
1 2 3 输入:chars = ["a" ,"a" ,"b" ,"b" ,"c" ,"c" ,"c" ] 输出:返回 6 ,输入数组的前 6 个字符应该是:["a" ,"2" ,"b" ,"2" ,"c" ,"3" ] 解释:"aa" 被 "a2" 替代。"bb" 被 "b2" 替代。"ccc" 被 "c3" 替代。
示例 2:
1 2 3 输入:chars = ["a" ] 输出:返回 1 ,输入数组的前 1 个字符应该是:["a" ] 解释:唯一的组是“a ”,它保持未压缩,因为它是一个字符。
示例 3:
1 2 3 输入:chars = ["a" ,"b" ,"b" ,"b" ,"b" ,"b" ,"b" ,"b" ,"b" ,"b" ,"b" ,"b" ,"b" ] 输出:返回 4 ,输入数组的前 4 个字符应该是:["a" ,"b" ,"1" ,"2" ]。 解释:由于字符 "a" 不重复,所以不会被压缩。"bbbbbbbbbbbb" 被 “b12” 替代。
使用两个指针 i 和 j 分别指向「当前处理到的位置」和「答案待插入的位置」:
i 指针一直往后处理,每次找到字符相同的连续一段 [i,idx),令长度为 len;将当前字符插入到答案,并让 j 指针后移:chars[j++] = chars[i];
检查长度 len 是否大于 1,如果大于 1,需要填入字符数量。
处理 len, 依次将个位数、十位数 。。。 填入chars数组,并更新 j 指针;
更新 i 和 len,代表循环处理下一字符。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 class Solution { public int compress (char [] chars) { int n = chars.length; int i = 0 ; int j = 0 ; while (i < n){ int idx = i; while (idx < n && chars[i] == chars[idx]) idx++; chars[j++] = chars[i]; int len = idx - i; if (len > 1 ) { int count = len; int lenCount = 0 ; while (count != 0 ) { lenCount++; count /= 10 ; } int t = j + lenCount - 1 ; while (len != 0 ) { int num = len % 10 ; len /= 10 ; chars[t--] = (char )(num + '0' ); } j += lenCount; } i = idx; len = 0 ; } return j; } }
给定一个整数数组 nums,将数组中的元素向右轮转 k 个位置,其中 k 是非负数。
示例 1:
1 2 3 4 5 6 输入 : nums = [1,2,3,4,5,6,7], k = 3 输出 : [5,6,7,1,2,3,4] 解释 :向右轮转 1 步: [7,1,2,3,4,5,6] 向右轮转 2 步: [6,7,1,2,3,4,5] 向右轮转 3 步: [5,6,7,1,2,3,4]
示例 2:
1 2 3 4 5 输入:nums = [-1,-100,3,99], k = 2 输出:[3,99,-1,-100] 解释 : 向右轮转 1 步: [99,-1,-100,3] 向右轮转 2 步: [3,99,-1,-100]
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 class Solution { public void rotate (int [] nums, int k) { int n = nums.length; int [] arr = new int [n]; for (int i = 0 ; i < n; i++){ arr[(i + k) % n] = nums[i]; } System.arraycopy(arr, 0 , nums, 0 , n); } } class Solution { public void rotate (int [] nums, int k) { k %= nums.length; reverse(nums, 0 , nums.length - 1 ); reverse(nums, 0 , k - 1 ); reverse(nums, k, nums.length - 1 ); } public void reverse (int [] nums, int start, int end) { while (start < end) { int temp = nums[start]; nums[start] = nums[end]; nums[end] = temp; start++; end--; } } }
剑指 Offer 66. 构建乘积数组 - 力扣(Leetcode)
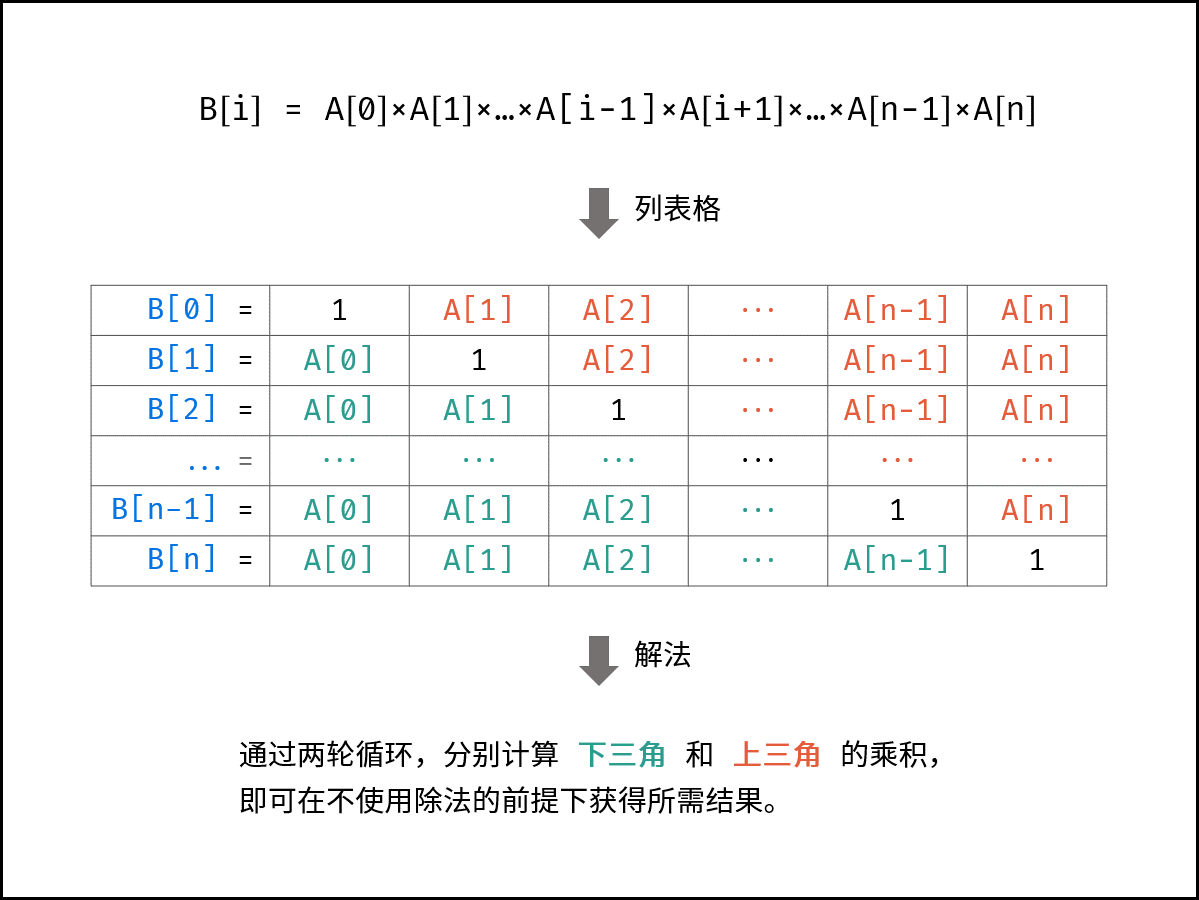
给你一个整数数组 nums,返回 数组 answer ,其中 answer[i] 等于 nums 中除 nums[i] 之外其余各元素的乘积 。
题目数据 保证 数组 nums之中任意元素的全部前缀元素和后缀的乘积都在 32 位 整数范围内。
请**不要使用除法,**且在 O(n) 时间复杂度内完成此题。
示例 1:
1 2 输入 : nums = [1,2,3,4] 输出 : [24,12,8,6]
示例 2:
1 2 输入 : nums = [-1,1,0,-3,3] 输出 : [0,0,9,0,0]
进阶:你可以在 O(1) 的额外空间复杂度内完成这个题目吗?( 出于对空间复杂度分析的目的,输出数组 不被视为 额外空间。)
巧妙记录每个元素的左右乘积
1 2 输入 : nums = [1,2,3,4] 输出 : [24,12,8,6]
当前元素的所有左边元素乘积
左边元素
结果
res[0]
p=1
1
res[1]
nums[0]
1
res[2]
nums[0]*nums[1]
1*2
res[3]
nums[0]*nums[1]*nums[2]
6
当前元素的所有右边元素乘积
右边元素乘积
结果
res[0]
nums[1]*nums[2]*nums[3]
24*1=24
res[1]
nums[2]*nums[3]
12*1=12
res[2]
nums[3]
4*2=8
res[3]
q=1
1*6=6
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 class Solution { public int [] productExceptSelf(int [] nums) { int [] res = new int [nums.length]; int p = 1 , q = 1 ; for (int i = 0 ; i < nums.length; i++) { res[i] = p; p *= nums[i]; } for (int i = nums.length - 1 ; i > 0 ; i--) { q *= nums[i]; res[i - 1 ] *= q; } return res; } }
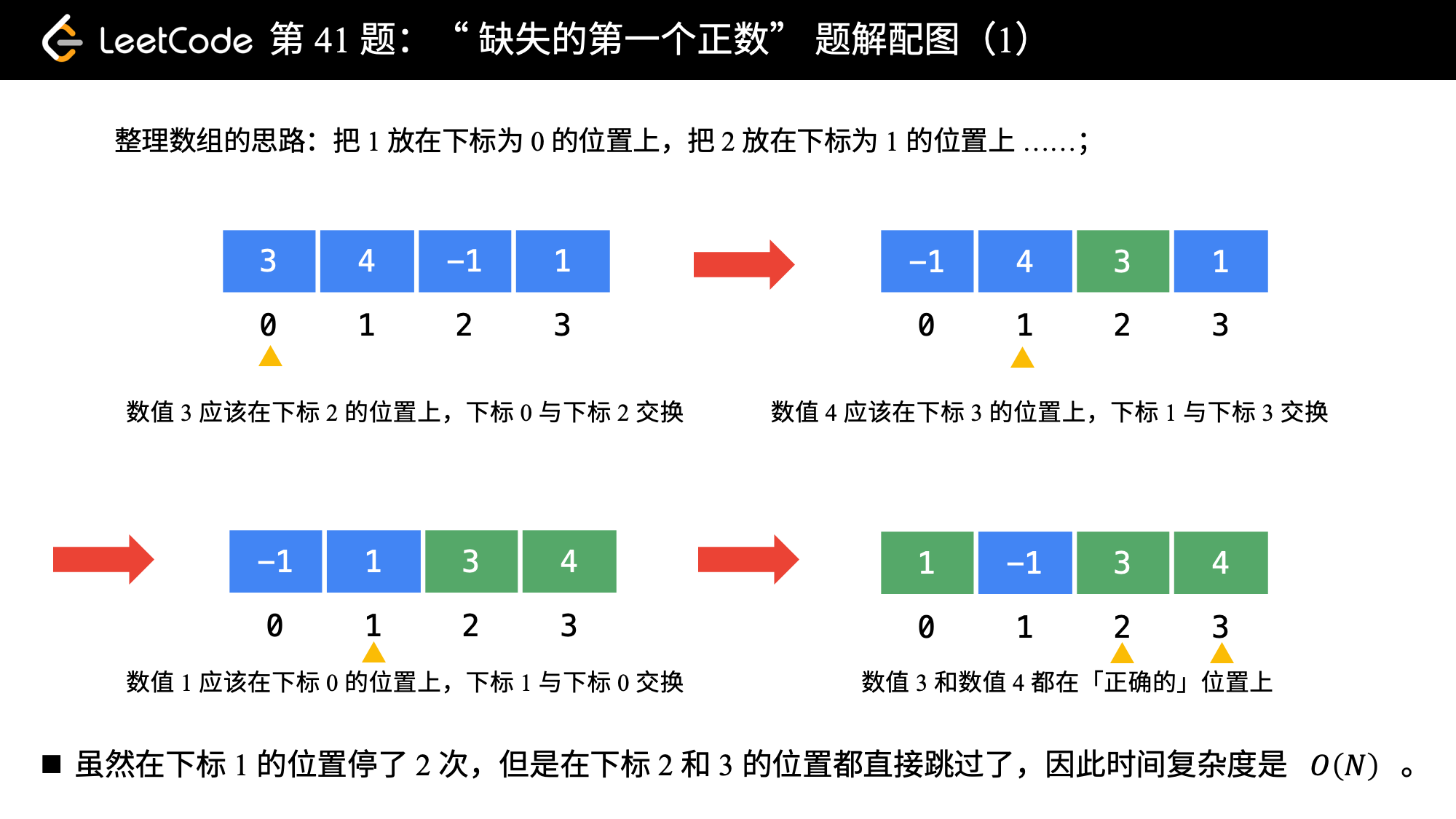
给你一个未排序的整数数组 nums ,请你找出其中没有出现的最小的正整数。
请你实现时间复杂度为 O(n) 并且只使用常数级别额外空间的解决方案。
示例 1:
示例 2:
1 2 输入:nums = [3,4,-1,1] 输出:2
示例 3:
1 2 输入:nums = [7,8,9,11,12] 输出:1
哈希表
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 class Solution { public int firstMissingPositive (int [] nums) { int len = nums.length; Set<Integer> set = new HashSet <>(); for (int num : nums) { set.add(num); } for (int i = 1 ; i <= len ; i++) { if (!set.contains(i)){ return i; } } return len + 1 ; } }
原地交换
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 public class Solution { public int firstMissingPositive (int [] nums) { int len = nums.length; for (int i = 0 ; i < len; i++) { while (nums[i] > 0 && nums[i] <= len && nums[nums[i] - 1 ] != nums[i]) { swap(nums, nums[i] - 1 , i); } } for (int i = 0 ; i < len; i++) { if (nums[i] != i + 1 ) { return i + 1 ; } } return len + 1 ; } private void swap (int [] nums, int index1, int index2) { int temp = nums[index1]; nums[index1] = nums[index2]; nums[index2] = temp; } }
找出数组中重复的数字。
示例 1:
1 2 3 输入: [2, 3, 1, 0, 2, 5, 3] 输出:2 或 3
哈希表
1 2 3 4 5 6 7 8 9 10 class Solution { public int findRepeatNumber (int [] nums) { Set<Integer> set = new HashSet <>(); for (int num : nums) { if (set.contains(num)) return num; set.add(num); } return -1 ; } }
原地交换
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 class Solution { public int findRepeatNumber (int [] nums) { for (int i = 0 ; i < nums.length; i++){ while (nums[i] != nums[nums[i]]) { swap(nums, i, nums[i]); } } for (int i = 0 ; i < nums.length; ++i) { if (nums[i] != i) { return nums[i]; } } return -1 ; } private void swap (int [] nums, int index1, int index2) { int temp = nums[index1]; nums[index1] = nums[index2]; nums[index2] = temp; } }
给你一个长度为 n 的整数数组 nums ,其中 nums 的所有整数都在范围 [1, n] 内,且每个整数出现 一次 或 两次 。请你找出所有出现 两次 的整数,并以数组形式返回。
你必须设计并实现一个时间复杂度为 O(n) 且仅使用常量额外空间的算法解决此问题。
示例 1:
1 2 输入:nums = [4,3,2,7,8,2,3,1] 输出:[2,3]
示例 2:
1 2 输入:nums = [1,1,2] 输出:[1]
示例 3:
原地交换
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 class Solution { public List<Integer> findDuplicates (int [] nums) { int n = nums.length; List<Integer> res = new ArrayList <Integer>(); for (int i = 0 ; i < n; ++i) { while (nums[i] != nums[nums[i] - 1 ]) { swap(nums, i, nums[i] - 1 ); } } for (int i = 0 ; i < n; ++i) { if (nums[i] != i + 1 ) { res.add(nums[i]); } } return res; } private void swap (int [] nums, int index1, int index2) { int temp = nums[index1]; nums[index1] = nums[index2]; nums[index2] = temp; } }
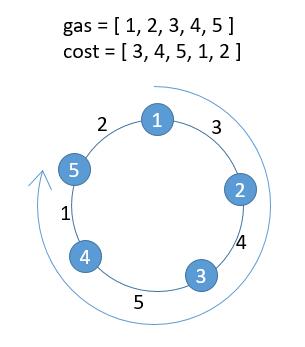
在一条环路上有 n 个加油站,其中第 i 个加油站有汽油 gas[i] 升。
你有一辆油箱容量无限的的汽车,从第 i 个加油站开往第 i+1 个加油站需要消耗汽油 cost[i] 升。你从其中的一个加油站出发,开始时油箱为空。
给定两个整数数组 gas 和 cost ,如果你可以按顺序绕环路行驶一周,则返回出发时加油站的编号,否则返回 -1 。如果存在解,则 保证 它是 唯一 的。
示例 1:
1 2 3 4 5 6 7 8 9 10 输入 : gas = [1,2,3,4,5], cost = [3,4,5,1,2] 输出 : 3 解释 :从 3 号加油站(索引为 3 处)出发,可获得 4 升汽油。此时油箱有 = 0 + 4 = 4 升汽油 开往 4 号加油站,此时油箱有 4 - 1 + 5 = 8 升汽油 开往 0 号加油站,此时油箱有 8 - 2 + 1 = 7 升汽油 开往 1 号加油站,此时油箱有 7 - 3 + 2 = 6 升汽油 开往 2 号加油站,此时油箱有 6 - 4 + 3 = 5 升汽油 开往 3 号加油站,你需要消耗 5 升汽油,正好足够你返回到 3 号加油站。 因此,3 可为起始索引。
示例 2:
1 2 3 4 5 6 7 8 9 输入 : gas = [2,3,4], cost = [3,4,3] 输出 : -1 解释 :你不能从 0 号或 1 号加油站出发,因为没有足够的汽油可以让你行驶到下一个加油站。 我们从 2 号加油站出发,可以获得 4 升汽油。 此时油箱有 = 0 + 4 = 4 升汽油 开往 0 号加油站,此时油箱有 4 - 3 + 2 = 3 升汽油 开往 1 号加油站,此时油箱有 3 - 3 + 3 = 3 升汽油 你无法返回 2 号加油站,因为返程需要消耗 4 升汽油,但是你的油箱只有 3 升汽油。 因此,无论怎样,你都不可能绕环路行驶一周。
把这个题理解成下边的图就可以。
每个节点表示添加的油量,每条边表示消耗的油量。题目的意思就是问我们从哪个节点出发,还可以回到该节点。只能顺时针方向走。
考虑暴力破解。
考虑从第 0 个点出发,能否回到第 0 个点。
考虑从第 1 个点出发,能否回到第 1 个点。
考虑从第 2 个点出发,能否回到第 2 个点。
… …
考虑从第 n 个点出发,能否回到第 n 个点。
由于是个圆,得到下一个点的时候我们需要取余数。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 class Solution { public int canCompleteCircuit (int [] gas, int [] cost) { int n = gas.length; for (int i = 0 ; i < n; i++) { int j = i; int remain = gas[i]; while (remain - cost[j] >= 0 ) { remain = remain - cost[j] + gas[(j + 1 ) % n]; j = (j + 1 ) % n; if (j == i) { return i; } } } return -1 ; } }
②链表
❶单向链表
特点
链表是以节点的方式来存储,是链式存储
每个节点包含 data 域 (存储数据),next 域(指向下一个节点)
链表的各个节点不一定是连续存储的
链表分带头节点的链表 和没有头节点的链表 ,根据实际的需求来确定
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 92 93 94 95 96 97 98 99 100 101 102 103 104 105 106 107 108 109 110 111 112 113 114 115 116 117 118 119 120 121 122 123 124 125 126 127 128 129 130 131 132 133 134 135 136 137 138 139 140 141 142 143 144 145 146 147 148 149 150 151 152 153 154 155 156 157 158 159 160 161 162 163 164 165 166 167 168 169 170 171 172 173 174 175 176 177 178 179 180 181 182 183 184 185 186 187 188 189 190 191 192 193 194 195 class StudentNode { int id; String name; StudentNode next; public StudentNode (int id, String name) { this .id = id; this .name = name; } @Override public String toString () { return "StudentNode{" + "id=" + id + ", name='" + name + '\'' + '}' ; } } class singleLinkedList { private StudentNode head = new StudentNode (0 , "" ); public void addNode (StudentNode node) { StudentNode temp = head; while (temp.next != null ) { temp = temp.next; } temp.next = node; } public void addByOrder (StudentNode node) { if (head.next == null ) { head.next = node; return ; } StudentNode temp = head; while (temp.next != null && temp.next.id < node.id) { temp = temp.next; } if (temp.next != null ) { node.next = temp.next; } temp.next = node; } public void traverseNode () { if (head.next == null ) { System.out.println("链表为空" ); } StudentNode temp = head; while (temp.next != null ) { System.out.println(temp.next); temp = temp.next; } } public void changeNode (StudentNode node) { if (head == null ) { System.out.println("链表为空,请先加入该学生信息" ); return ; } StudentNode temp = head; while (temp.next != null && temp.id != node.id) { temp = temp.next; } if (temp.id != node.id) { System.out.println("未找到该学生的信息,请先创建该学生的信息" ); return ; } temp.name = node.name; } public void deleteNode (StudentNode node) { if (head.next == null ) { System.out.println("链表为空" ); return ; } StudentNode temp = head; while (temp.next != null && temp.next.id != node.id) { temp = temp.next; } if (temp.next == null ){ System.out.println("要删除的节点不存在" ); return ; } temp.next = temp.next.next; } public StudentNode getNodeByIndex (int index) { if (head.next == null ) { System.out.println("链表为空!" ); } StudentNode temp = head; int length = 0 ; while (temp.next != null ) { temp = temp.next; length++; } if (index > length) { throw new RuntimeException ("链表越界" ); } temp = head; for (int i = 0 ; i < index; i++) { temp = temp.next; } return temp; } public void reverseTraverse () { if (head == null ) { System.out.println("链表为空" ); } StudentNode temp = head; Stack<StudentNode> stack = new Stack <>(); while (temp.next != null ) { stack.push(temp.next); temp = temp.next; } while (!stack.isEmpty()) { System.out.println(stack.pop()); } } } public class SingleLinkedListDemo { public static void main (String[] args) { singleLinkedList linkedList = new singleLinkedList (); System.out.println("插入节点1和3:" ); StudentNode student1 = new StudentNode (1 , "Jack" ); StudentNode student3 = new StudentNode (3 , "Tom" ); linkedList.addNode(student1); linkedList.addNode(student3); linkedList.traverseNode(); System.out.println("有序插入节点2:" ); StudentNode student2 = new StudentNode (2 , "Jerry" ); linkedList.addByOrder(student2); linkedList.traverseNode(); System.out.println("修改节点1信息:" ); student2 = new StudentNode (1 , "Jack2" ); linkedList.changeNode(student2); linkedList.traverseNode(); System.out.println("获得第2个节点:" ); System.out.println(linkedList.getNodeByIndex(2 )); System.out.println("删除学生信息:" ); student2 = new StudentNode (1 , "Jack2" ); linkedList.deleteNode(student2); linkedList.traverseNode(); System.out.println("倒序遍历链表:" ); linkedList.reverseTraverse(); } }
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 链表为空 插入节点1和3: StudentNode{id =1, name ='Jack' } StudentNode{id =3, name ='Tom' } 有序插入节点2: StudentNode{id =1, name ='Jack' } StudentNode{id =2, name ='Jerry' } StudentNode{id =3, name ='Tom' } 修改节点1信息: StudentNode{id =1, name ='Jack2' } StudentNode{id =2, name ='Jerry' } StudentNode{id =3, name ='Tom' } 获得第2个节点: StudentNode{id =2, name ='Jerry' } 删除学生信息: StudentNode{id =2, name ='Jerry' } StudentNode{id =3, name ='Tom' } 倒序遍历链表: StudentNode{id =3, name ='Tom' } StudentNode{id =2, name ='Jerry' }
❷双向链表
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 92 93 94 95 96 97 98 99 100 101 102 103 104 105 106 107 108 109 110 111 112 113 114 115 116 117 118 119 120 121 122 123 124 125 126 127 128 129 130 131 132 133 134 135 136 137 138 139 140 141 142 143 144 145 146 147 148 149 150 151 152 153 154 155 156 157 158 159 160 161 162 163 164 165 166 167 168 169 170 171 172 173 174 175 176 177 178 179 180 class HeroNode { int id; String name; HeroNode next; HeroNode pre; public HeroNode (int id, String name) { this .id = id; this .name = name; } @Override public String toString () { return "HeroNode{id=" + id + ", name=" + name + "}" ; } } class DoubleLinkedList { HeroNode head = new HeroNode (0 , "" ); HeroNode tail = head; public void list () { if (head.next == null ) { System.out.println("链表为空" ); return ; } HeroNode temp = head.next; while (temp != null ) { System.out.println(temp); temp = temp.next; } } public void add (HeroNode heroNode) { tail.next = heroNode; heroNode.pre = tail; tail = heroNode; } public void addByOrder (HeroNode heroNode) { HeroNode temp = head; boolean flag = false ; while (temp.next != null && temp.next.id <= heroNode.id) { if (temp.next.id == heroNode.id) { flag = true ; } temp = temp.next; } if (flag) { System.out.printf("英雄编号【%d】已经存在了\n" , heroNode.id); } else { heroNode.next = temp.next; if (temp.next != null ) { temp.next.pre = heroNode; } temp.next = heroNode; heroNode.pre = temp; } } public void update (HeroNode heroNode) { if (head.next == null ) { System.out.println("链表为空~~" ); return ; } HeroNode temp = head.next; boolean flag = false ; while (temp != null ) { if (temp.id == heroNode.id) { flag = true ; break ; } temp = temp.next; } if (flag) { temp.name = heroNode.name; } else { System.out.printf("没有找到编号为 %d 的节点,不能修改\n" , heroNode.id); } } public void delete (int id) { if (head.next == null ) { System.out.println("链表为空,无法删除" ); return ; } HeroNode temp = head; boolean flag = false ; while (temp.next != null ) { if (temp.id == id) { flag = true ; break ; } temp = temp.next; } if (flag) { temp.pre.next = temp.next; if (temp.next != null ) { temp.next.pre = temp.pre; } } } } public class DoubleLinkedListDemo { public static void main (String[] args) { System.out.println("双向链表:" ); HeroNode her1 = new HeroNode (1 , "宋江" ); HeroNode her2 = new HeroNode (2 , "卢俊义" ); HeroNode her3 = new HeroNode (3 , "吴用" ); HeroNode her4 = new HeroNode (4 , "林冲" ); DoubleLinkedList doubleLinkedList = new DoubleLinkedList (); doubleLinkedList.add(her1); doubleLinkedList.add(her2); doubleLinkedList.add(her3); doubleLinkedList.add(her4); doubleLinkedList.list(); HeroNode newHeroNode = new HeroNode (4 , "公孙胜" ); doubleLinkedList.update(newHeroNode); System.out.println("修改节点4:" ); doubleLinkedList.list(); doubleLinkedList.delete(3 ); System.out.println("删除节点3" ); doubleLinkedList.list(); System.out.println("测试有序增加链表:" ); DoubleLinkedList doubleLinkedList1 = new DoubleLinkedList (); doubleLinkedList1.addByOrder(her3); doubleLinkedList1.addByOrder(her2); doubleLinkedList1.addByOrder(her2); doubleLinkedList1.addByOrder(her4); doubleLinkedList1.addByOrder(her4); doubleLinkedList1.addByOrder(her2); doubleLinkedList1.addByOrder(her1); doubleLinkedList1.list(); } }
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 双向链表: HeroNode{id =1, name =宋江} HeroNode{id =2, name =卢俊义} HeroNode{id =3, name =吴用} HeroNode{id =4, name =林冲} 修改节点4: HeroNode{id =1, name =宋江} HeroNode{id =2, name =卢俊义} HeroNode{id =3, name =吴用} HeroNode{id =4, name =公孙胜} 删除节点3 HeroNode{id =1, name =宋江} HeroNode{id =2, name =卢俊义} HeroNode{id =4, name =公孙胜} 测试有序增加链表: 英雄编号【2】已经存在了 英雄编号【4】已经存在了 英雄编号【2】已经存在了 HeroNode{id =1, name =宋江} HeroNode{id =2, name =卢俊义} HeroNode{id =3, name =吴用} HeroNode{id =4, name =公孙胜}
❸循环链表
❹LeetCode真题
给你一个链表的头节点 head 和一个整数 val ,请你删除链表中所有满足 Node.val == val 的节点,并返回 新的头节点 。
示例 1:
1 2 输入:head = [1,2,6,3,4,5,6], val = 6 输出:[1,2,3,4,5]
示例 2:
1 2 输入:head = [], val = 1 输出:[]
示例 3:
1 2 输入:head = [7,7,7,7], val = 7 输出:[]
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 public ListNode removeElements (ListNode head, int val) { if (head == null ) { return head; } ListNode dummy = new ListNode (-1 , head); ListNode pre = dummy; ListNode cur = head; while (cur != null ) { if (cur.val == val) { pre.next = cur.next; } else { pre = cur; } cur = cur.next; } return dummy.next; } class Solution { public ListNode removeElements (ListNode head, int val) { while (head != null && head.val == val){ head = head.next; } ListNode cur = head; while (cur != null ){ while (cur.next != null && cur.next.val == val){ cur.next = cur.next.next; } cur = cur.next; } return head; } }
设计链表的实现。您可以选择使用单链表或双链表。单链表中的节点应该具有两个属性:val 和 next。val 是当前节点的值,next 是指向下一个节点的指针/引用。如果要使用双向链表,则还需要一个属性 prev 以指示链表中的上一个节点。假设链表中的所有节点都是 0-index 的。
在链表类中实现这些功能:
get(index):获取链表中第 index 个节点的值。如果索引无效,则返回-1。
addAtHead(val):在链表的第一个元素之前添加一个值为 val 的节点。插入后,新节点将成为链表的第一个节点。
addAtTail(val):将值为 val 的节点追加到链表的最后一个元素。
addAtIndex(index,val):在链表中的第 index 个节点之前添加值为 val 的节点。如果 index 等于链表的长度,则该节点将附加到链表的末尾。如果 index 大于链表长度,则不会插入节点。如果index小于0,则在头部插入节点。
deleteAtIndex(index):如果索引 index 有效,则删除链表中的第 index 个节点。
示例:
1 2 3 4 5 6 7 MyLinkedList linkedList = new MyLinkedList(); linkedList.addAtHead(1); linkedList.addAtTail(3); linkedList.addAtIndex(1,2); //链表变为1-> 2-> 3 linkedList.get(1); //返回2 linkedList.deleteAtIndex(1); //现在链表是1-> 3 linkedList.get(1); //返回3
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 92 93 94 95 96 97 98 99 100 101 102 103 104 105 106 107 108 109 110 111 112 113 114 115 116 117 118 119 120 121 122 123 124 125 126 127 128 129 130 131 132 133 134 135 136 137 138 139 140 141 142 143 144 145 146 147 148 149 150 151 152 153 154 155 156 157 158 159 class ListNode { int val; ListNode next; ListNode(){} ListNode(int val) { this .val=val; } } class MyLinkedList { int size; ListNode head; public MyLinkedList () { size = 0 ; head = new ListNode (0 ); } public int get (int index) { if (index < 0 || index >= size) return -1 ; ListNode cur = head; for (int i = 0 ; i <= index; i++){ cur = cur.next; } return cur.val; } public void addAtHead (int val) { addAtIndex(0 , val); } public void addAtTail (int val) { addAtIndex(size, val); } public void addAtIndex (int index, int val) { if (index > size) return ; if (index < 0 ) index = 0 ; ListNode pre = head; ListNode addNode = new ListNode (val); for (int i = 0 ; i < index; i++){ pre = pre.next; } addNode.next = pre.next; pre.next = addNode; size++; } public void deleteAtIndex (int index) { if (index < 0 || index >= size) return ; ListNode pre = head; for (int i = 0 ; i < index; i++){ pre = pre.next; } pre.next = pre.next.next; size--; } } class ListNode { int val; ListNode prev, next; ListNode(){} ListNode(int val) { this .val=val; } } class MyLinkedList { int size; ListNode head, tail; public MyLinkedList () { size = 0 ; head = new ListNode (0 ); tail = new ListNode (0 ); head.next=tail; tail.prev=head; } public int get (int index) { if (index < 0 || index >= size) return -1 ; ListNode cur = head; if (index > size / 2 ) { cur = tail; for (int i = size; i > index; i--){ cur = cur.prev; } } else { for (int i = 0 ; i <= index; i++){ cur = cur.next; } } return cur.val; } public void addAtHead (int val) { addAtIndex(0 , val); } public void addAtTail (int val) { addAtIndex(size, val); } public void addAtIndex (int index, int val) { if (index > size) return ; if (index < 0 ) index = 0 ; ListNode pre = head; for (int i = 0 ; i < index; i++){ pre = pre.next; } ListNode newNode = new ListNode (val); newNode.next = pre.next; pre.next.prev = newNode; newNode.prev = pre; pre.next = newNode; size++; } public void deleteAtIndex (int index) { if (index < 0 || index >= size) { return ; } ListNode pre = head; for (int i = 0 ; i < index; i++){ pre = pre.next; } pre.next.next.prev = pre; pre.next = pre.next.next; size--; } }
剑指 Offer 24. 反转链表 - 力扣(Leetcode)
剑指 Offer II 024. 反转链表 - 力扣(Leetcode)
给你单链表的头节点 head ,请你反转链表,并返回反转后的链表。
示例 1:
1 2 输入:head = [1,2,3,4,5] 输出:[5,4,3,2,1]
示例 2:
1 2 输入:head = [1,2] 输出:[2,1]
示例 3:
**进阶:**链表可以选用迭代或递归方式完成反转。你能否用两种方法解决这道题?
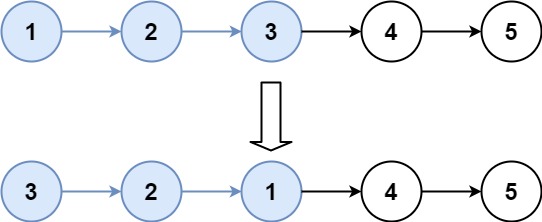
迭代法
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 class Solution { public ListNode reverseList (ListNode head) { if (head == null || head.next == null ) { return head; } ListNode pre = null ; ListNode cur = head; while (cur != null ){ ListNode tmp = cur.next; cur.next = pre; pre = cur; cur = tmp; } return pre; } }
递归法
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 class Solution { public ListNode reverseList (ListNode head) { return reverse(null ,head); } public ListNode reverse (ListNode pre, ListNode cur) { if (cur == null ) { return pre; } ListNode tmp = cur.next; cur.next = pre; return reverse(cur, tmp); } } class Solution { public ListNode reverseList (ListNode head) { if (head == null || head.next == null ) { return head; } ListNode last = reverseList(head.next); head.next.next = head; head.next = null ; return last; } }
栈实现
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 class Solution { public ListNode reverseList (ListNode head) { Deque<ListNode> stack = new ArrayDeque <>(); while (head != null ){ stack.push(head); head = head.next; } ListNode dummy = new ListNode (0 ); ListNode temp = dummy; while (!stack.isEmpty()){ temp.next = stack.pop(); temp = temp.next; } temp.next = null ; return dummy.next; } } class Solution { public ListNode reverseList (ListNode head) { Deque<ListNode> stack = new ArrayDeque <>(); while (head != null ){ stack.add(head); head = head.next; } ListNode dummy = new ListNode (0 ), ListNode temp = dummy; while (stack.size() != 0 ){ temp.next = new ListNode (stack.pop()); temp = temp.next; } return dummy.next; } }
给你一个链表,两两交换其中相邻的节点,并返回交换后链表的头节点。你必须在不修改节点内部的值的情况下完成本题(即,只能进行节点交换)。
示例 1:
1 2 输入:head = [1,2,3,4] 输出:[2,1,4,3]
示例 2:
示例 3:
递归法:O(n)
1.返回值:交换完成的子链表
2.调换:设需要交换的两个点为 first 和 second,first 连接后面交换完成的子链表,second 连接 first
3.终止条件:head 为空指针或者 next 为空指针,也就是当前无节点或者只有一个节点,无法进行交换
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 class Solution { public ListNode swapPairs (ListNode head) { if (head == null || head.next == null ){ return head; } ListNode first = head; ListNode second = head.next; first.next = swapPairs(second.next); second.next = first; return second; } } class Solution { public ListNode swapPairs (ListNode head) { if (head == null || head.next == null ) { return head; } ListNode a = head; ListNode b = head; for (int i = 0 ; i < 2 ; i++){ if (b == null ) { return head; } b = b.next; } ListNode newhead = reverse(a, b); a.next = swapPairs(b); return newhead; } ListNode reverse (ListNode a, ListNode b) { ListNode prev = null ; ListNode curr = a; ListNode next = null ; while (curr != b){ next = curr.next; curr.next = prev; prev = curr; curr = next; } return prev; } }
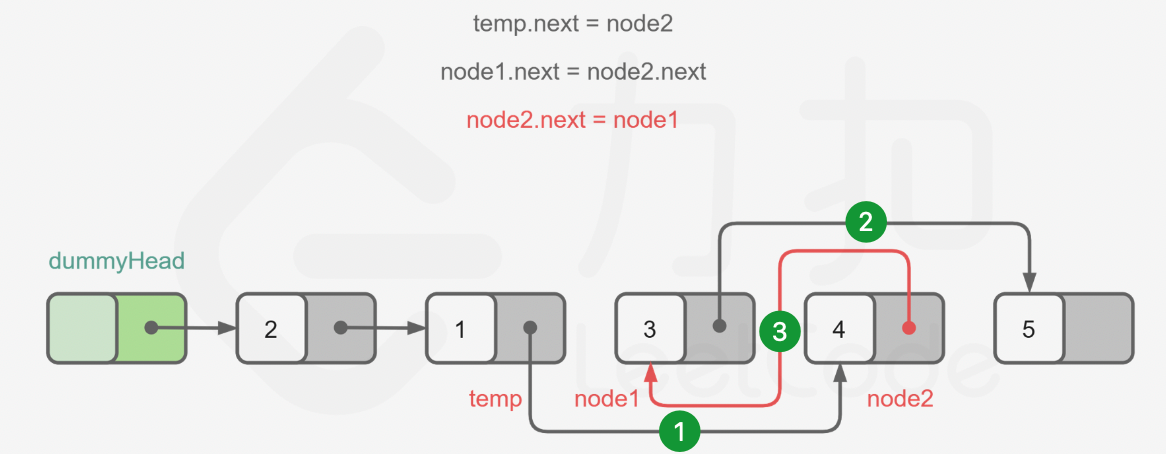
迭代法:O(n)
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 class Solution { public ListNode swapPairs (ListNode head) { ListNode dummyHead = new ListNode (0 , head); ListNode temp = dummyHead; while (temp.next != null && temp.next.next != null ) { ListNode node1 = temp.next; ListNode node2 = temp.next.next; temp.next = node2; node1.next = node2.next; node2.next = node1; temp = node1; } return dummyHead.next; } }
给你链表的头节点 head ,每 k 个节点一组进行翻转,请你返回修改后的链表。
k 是一个正整数,它的值小于或等于链表的长度。如果节点总数不是 k 的整数倍,那么请将最后剩余的节点保持原有顺序。你不能只是单纯的改变节点内部的值,而是需要实际进行节点交换。
示例 1:
1 2 输入:head = [1,2,3,4,5], k = 2 输出:[2,1,4,3,5]
示例 2:
1 2 输入:head = [1,2,3,4,5], k = 3 输出:[3,2,1,4,5]
先翻转k个,再翻转k个,再拼接这2k个,以此类推
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 class Solution { public ListNode reverseKGroup (ListNode head, int k) { if (head == null || head.next == null ) { return head; } ListNode a = head; ListNode b = head; for (int i = 0 ; i < k; i++){ if (b == null ) { return head; } b = b.next; } ListNode newhead = reverse(a, b); a.next = reverseKGroup(b, k); return newhead; } ListNode reverse (ListNode a, ListNode b) { ListNode prev = null ; ListNode curr = a; ListNode temp = null ; while (curr != b){ temp = curr.next; curr.next = prev; prev = curr; curr = temp; } return prev; } } class Solution { public static ListNode reverseKGroup (ListNode head, int k) { ListNode cur = head; int count = 0 ; while (cur != null && count != k) { cur = cur.next; count++; } if (count == k) { cur = reverseKGroup(cur, k); while (count-- > 0 ) { ListNode tmp = head.next; head.next = cur; cur = head; head = tmp; } head = cur; } return head; } }
变形题:k组链表整体翻转
给你一个链表,每 k 个节点一组进行翻转,请你返回翻转后的链表。k 是一个正整数,它的值小于或等于链表的长度。如果节点总数不是 k 的整数倍,那么请将最后剩余的节点保持原有顺序。
示例:
1 2 输入:head = [1,2,3,4,5], k = 2 输出:[3,4,1,2,5]
1 2 输入:head = [1,2,3,4,5], k = 3 输出:[1,2,3,4,5]
这道题可以使用递归的方法来解决,具体步骤如下:
首先,我们需要找到每一组需要翻转的链表的起始节点和结束节点。
然后,我们需要对这一组链表进行翻转操作。
最后,我们需要将翻转后的链表与下一组翻转后的链表连接起来。
给你一个链表,删除链表的倒数第 n 个结点,并且返回链表的头结点。
示例 1:
1 2 输入:head = [1,2,3,4,5], n = 2 输出:[1,2,3,5]
示例 2:
1 2 输入:head = [1], n = 1 输出:[]
示例 3:
1 2 输入:head = [1,2], n = 1 输出:[1]
暴力法:O(n)
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 class Solution { public ListNode removeNthFromEnd (ListNode head, int n) { int length = 0 ; ListNode temp = head; while (temp != null ) { ++length; temp = temp.next; } ListNode dummy = new ListNode (0 , head); ListNode cur = dummy; for (int i = 0 ; i < length - n; i++) { cur = cur.next; } cur.next = cur.next.next; return dummy.next; } }
双指针法:O(n)
由于我们需要找到倒数第 n 个节点,因此我们可以使用两个指针 first 和 second 同时对链表进行遍历,并且 first比 second超前 n 个节点。当 first 遍历到链表的末尾时,second 就恰好处于倒数第 n 个节点。
具体地,初始时 first和 second 均指向头节点。我们首先使用 first 对链表进行遍历,遍历的次数为 n。此时 first 比 second 超前了 n 个节点。在这之后,同时使用 first 和 second 对链表进行遍历。当 first 遍历到链表的末尾(即 first为空指针)时,second 恰好指向倒数第 n 个节点。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 class Solution { public ListNode removeNthFromEnd (ListNode head, int n) { ListNode dummy = new ListNode (0 , head); ListNode first = head; ListNode second = dummy; for (int i = 0 ; i < n; i++) { first = first.next; } while (first != null ) { first = first.next; second = second.next; } second.next = second.next.next; return dummy.next; } }
给你一个链表的头节点 head 。删除 链表的 中间节点 ,并返回修改后的链表的头节点 head 。
长度为 n 链表的中间节点是从头数起第 ⌊n / 2⌋ 个节点(下标从 0 开始),其中 ⌊x⌋ 表示小于或等于 x 的最大整数。
对于 n = 1、2、3、4 和 5 的情况,中间节点的下标分别是 0、1、1、2 和 2 。
示例 1:
1 2 3 4 5 6 输入:head = [1,3,4,7,1,2,6] 输出:[1,3,4,1,2,6] 解释: 上图表示给出的链表。节点的下标分别标注在每个节点的下方。 由于 n = 7 ,值为 7 的节点 3 是中间节点,用红色标注。 返回结果为移除节点后的新链表。
示例 2:
1 2 3 4 5 输入:head = [1,2,3,4] 输出:[1,2,4] 解释: 上图表示给出的链表。 对于 n = 4 ,值为 3 的节点 2 是中间节点,用红色标注。
示例 3:
1 2 3 4 5 6 输入:head = [2,1] 输出:[2] 解释: 上图表示给出的链表。 对于 n = 2 ,值为 1 的节点 1 是中间节点,用红色标注。 值为 2 的节点 0 是移除节点 1 后剩下的唯一一个节点。
使用slow记录慢指针,fast记录快指针。 当fast的再一次移动就结束时,说明slow的再一次移动也将到达中间点,那么这个时候就可以直接用slow.next = slow.next.next来去掉中间节点。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 class Solution { public ListNode deleteMiddle (ListNode head) { if (head == null || head.next == null ){ return null ; } ListNode slow = head; ListNode fast = head.next; while (fast.next != null && fast.next.next != null ){ slow = slow.next; fast = fast.next.next; } slow.next = slow.next.next; return head; } } class Solution { public ListNode deleteMiddle (ListNode head) { ListNode dummy = new ListNode (-1 , head); ListNode slow = dummy; ListNode fast = dummy.next; while (fast != null && fast.next != null ) { slow = slow.next; fast = fast.next.next; } slow.next = slow.next.next; return dummy.next; } }
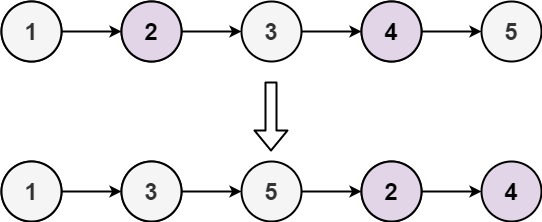
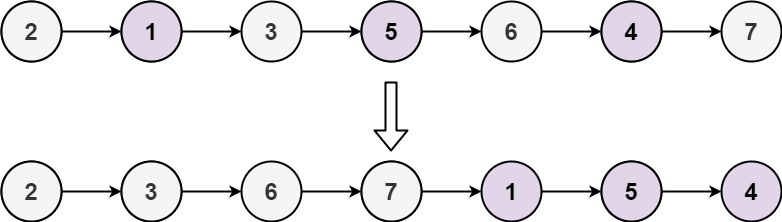
给定单链表的头节点 head ,将所有索引为奇数的节点和索引为偶数的节点分别组合在一起,然后返回重新排序的列表。
第一个 节点的索引被认为是 奇数 , 第二个 节点的索引为 偶数 ,以此类推。
请注意,偶数组和奇数组内部的相对顺序应该与输入时保持一致。
你必须在 O(1) 的额外空间复杂度和 O(n) 的时间复杂度下解决这个问题。
示例 1:
1 2 输入 : head = [1,2,3,4,5] 输出 : [1,3,5,2,4]
示例 2:
1 2 输入 : head = [2,1,3,5,6,4,7] 输出 : [2,3,6,7,1,5,4]
用odd记录奇数节点的链表,even记录偶数节点的链表, 最后把odd尾部节点指向even的头结点,返回head即可。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 class Solution { public ListNode oddEvenList (ListNode head) { if (head == null || head.next == null ) { return head; } ListNode odd = head; ListNode even = head.next; ListNode evenHead = even; while (even != null && even.next != null ) { odd.next = even.next; odd = odd.next; even.next = odd.next; even = even.next; } odd.next = evenHead; return head; } }
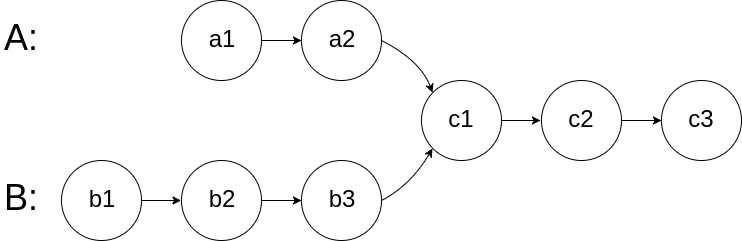
给你两个单链表的头节点 headA 和 headB ,请你找出并返回两个单链表相交的起始节点。如果两个链表不存在相交节点,返回 null 。
图示两个链表在节点 c1 开始相交**:**
题目数据 保证 整个链式结构中不存在环。
注意 ,函数返回结果后,链表必须 保持其原始结构 。
示例 1:
1 2 3 4 5 6 输入:intersectVal = 8, listA = [4,1,8,4,5], listB = [5,6,1,8,4,5], skipA = 2, skipB = 3 输出:Intersected at '8' 解释:相交节点的值为 8 (注意,如果两个链表相交则不能为 0)。 从各自的表头开始算起,链表 A 为 [4,1,8,4,5],链表 B 为 [5,6,1,8,4,5]。 在 A 中,相交节点前有 2 个节点;在 B 中,相交节点前有 3 个节点。 — 请注意相交节点的值不为 1,因为在链表 A 和链表 B 之中值为 1 的节点 (A 中第二个节点和 B 中第三个节点) 是不同的节点。换句话说,它们在内存中指向两个不同的位置,而链表 A 和链表 B 中值为 8 的节点 (A 中第三个节点,B 中第四个节点) 在内存中指向相同的位置。
示例 2:
1 2 3 4 5 输入:intersectVal = 2, listA = [1,9,1,2,4], listB = [3,2,4], skipA = 3, skipB = 1 输出:Intersected at '2' 解释:相交节点的值为 2 (注意,如果两个链表相交则不能为 0)。 从各自的表头开始算起,链表 A 为 [1,9,1,2,4],链表 B 为 [3,2,4]。 在 A 中,相交节点前有 3 个节点;在 B 中,相交节点前有 1 个节点。
示例 3:
1 2 3 4 5 输入:intersectVal = 0, listA = [2,6,4], listB = [1,5], skipA = 3, skipB = 2 输出:null 解释:从各自的表头开始算起,链表 A 为 [2,6,4],链表 B 为 [1,5]。 由于这两个链表不相交,所以 intersectVal 必须为 0,而 skipA 和 skipB 可以是任意值。 这两个链表不相交,因此返回 null 。
**进阶:**你能否设计一个时间复杂度 O(m + n) 、仅用 O(1) 内存的解决方案?
考虑构建两个节点指针 A , B 分别指向两链表头节点 headA , headB ,做如下操作:
指针 A 先遍历完链表 headA ,再开始遍历链表 headB ,当走到 node 时,共走步数为:a+(b−c)
指针 B 先遍历完链表 headB ,再开始遍历链表 headA ,当走到 node 时,共走步数为:b+(a−c)
a+(b−c) = b+(a−c),此时指针 A , B 重合 ,并有两种情况:
若两链表 有 公共尾部 (即 c>0 ) :指针 A , B 同时指向「第一个公共节点」node 。
若两链表 无 公共尾部 (即 c=0) :指针 A , B 同时指向 null 。
因此返回 A 即可。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 public class Solution { public ListNode getIntersectionNode (ListNode headA, ListNode headB) { ListNode A = headA; ListNode B = headB; while (A != B){ if (A != null ) A = A.next; else A = headB; if (B != null ) B = B.next; else B = headA; } return A; } } public class Solution { public ListNode getIntersectionNode (ListNode headA, ListNode headB) { ListNode A = headA; ListNode B = headB; while (A != B){ A = A != null ? A.next : headB; B = B != null ? B.next : headA; } return A; } }
快慢指针法
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 public class Solution { public boolean hasCycle (ListNode head) { ListNode slow = head; ListNode fast = head; while (fast != null && fast.next != null ){ slow = slow.next; fast = fast.next.next; if (fast == slow) return true ; } return false ; } }
给定一个链表的头节点 head ,返回链表开始入环的第一个节点。 如果链表无环,则返回 null。
如果链表中有某个节点,可以通过连续跟踪 next 指针再次到达,则链表中存在环。 为了表示给定链表中的环,评测系统内部使用整数 pos 来表示链表尾连接到链表中的位置(索引从 0 开始 )。如果 pos 是 -1,则在该链表中没有环。注意:pos 不作为参数进行传递 ,仅仅是为了标识链表的实际情况。
不允许修改 链表。
示例 1:
1 2 3 输入:head = [3,2,0,-4], pos = 1 输出:返回索引为 1 的链表节点 解释:链表中有一个环,其尾部连接到第二个节点。
示例 2:
1 2 3 输入:head = [1,2], pos = 0 输出:返回索引为 0 的链表节点 解释:链表中有一个环,其尾部连接到第一个节点。
示例 3:
1 2 3 输入:head = [1], pos = -1 输出:返回 null 解释:链表中没有环。
**进阶:**你是否可以使用 O(1) 空间解决此题?
方法一:哈希表
遍历链表中的每个节点,并将它记录下来;一旦遇到了此前遍历过的节点,就可以判定链表中存在环。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 public class Solution { public ListNode detectCycle (ListNode head) { Set<ListNode> set = new HashSet <>(); ListNode temp = head; while (temp != null ){ if (set.contains(temp)){ return temp; } set.add(temp); temp = temp.next; } return null ; } }
时间复杂度:O(N),其中 N 为链表中节点的数目。我们恰好需要访问链表中的每一个节点。
空间复杂度:O(N),其中 N 为链表中节点的数目。我们需要将链表中的每个节点都保存在哈希表当中。
方法二:快慢指针
当快慢指针相遇时,让其中任一个指针指向头节点,然后让它俩以相同速度前进,再次相遇时所在的节点位置就是环开始的位置。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 public class Solution { public ListNode detectCycle (ListNode head) { ListNode slow = head; ListNode fast = head; while (fast != null && fast.next != null ) { fast = fast.next.next; slow = slow.next; if (fast == slow) { slow = head; while (slow != fast) { fast = fast.next; slow = slow.next; } return slow; } } return null ; } }
时间复杂度:O(N),其中 N 为链表中节点的数目。我们恰好需要访问链表中的每一个节点。
空间复杂度:O(1)
将两个升序链表合并为一个新的 升序 链表并返回。新链表是通过拼接给定的两个链表的所有节点组成的。
示例 1:
1 2 输入:l1 = [1,2,4], l2 = [1,3,4] 输出:[1,1,2,3,4,4]
示例 2:
1 2 输入:l1 = [], l2 = [] 输出:[]
示例 3:
1 2 输入:l1 = [], l2 = [0] 输出:[0]
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 class Solution { public ListNode mergeTwoLists (ListNode list1, ListNode list2) { ListNode dummy = new ListNode (-1 ); ListNode list = dummy; while (list1 != null && list2 != null ){ if (list1.val < list2.val){ list.next = list1; list1 = list1.next; } else { list.next = list2; list2 = list2.next; } list = list.next; } if (list1 != null ){ list.next = list1; } if (list2 != null ){ list.next = list2; } return dummy.next; } }
给你一个链表数组,每个链表都已经按升序排列。
请你将所有链表合并到一个升序链表中,返回合并后的链表。
示例 1:
1 2 3 4 5 6 7 8 9 10 输入:lists = [[1,4,5],[1,3,4],[2,6]] 输出:[1,1,2,3,4,4,5,6] 解释:链表数组如下: [ 1->4->5, 1->3->4, 2->6 ] 将它们合并到一个有序链表中得到。 1->1->2->3->4->4->5->6
示例 2:
示例 3:
逐一合并两条链表
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 class Solution { public ListNode mergeKLists (ListNode[] lists) { ListNode res = null ; for (ListNode list: lists) { res = mergeTwoLists(res, list); } return res; } public ListNode mergeTwoLists (ListNode list1, ListNode list2) { ListNode dummy = new ListNode (-1 ); ListNode list = dummy; while (list1 != null && list2 != null ){ if (list1.val < list2.val){ list.next = list1; list1 = list1.next; } else { list.next = list2; list2 = list2.next; } list = list.next; } if (list1 != null ){ list.next = list1; } if (list2 != null ){ list.next = list2; } return dummy.next; } }
优先队列
维护一个小顶堆,存放k个节点中的最小节点,再把最小节点接到新链表中
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 class Solution { public ListNode mergeKLists (ListNode[] lists) { if (lists.length == 0 ) return null ; ListNode dummy = new ListNode (-1 ); ListNode list = dummy; PriorityQueue<ListNode> pq = new PriorityQueue <>(lists.length, (a, b)->(a.val - b.val)); for (ListNode head : lists){ if (head != null ) { pq.offer(head); } } while (!pq.isEmpty()){ ListNode node = pq.poll(); list.next = node; if (node.next != null ){ pq.offer(node.next); } list = list.next; } return dummy.next; } }
给你一个链表的头节点 head 和一个特定值 x ,请你对链表进行分隔,使得所有 小于 x 的节点都出现在 大于或等于 x 的节点之前。
你应当 保留 两个分区中每个节点的初始相对位置。
示例 1:
1 2 输入:head = [1,4,3,2,5,2], x = 3 输出:[1,2,2,4,3,5]
示例 2:
1 2 输入:head = [2,1], x = 2 输出:[1,2]
在合并两个有序链表时让你合二为一,而这里需要分解让你把原链表一分为二。具体来说,我们可以把原链表分成两个小链表,一个链表中的元素大小都小于 x,另一个链表中的元素都大于等于 x,最后再把这两条链表接到一起,就得到了题目想要的结果。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 class Solution { ListNode partition (ListNode head, int x) { ListNode dummy1 = new ListNode (-1 ); ListNode dummy2 = new ListNode (-1 ); ListNode p1 = dummy1, p2 = dummy2; ListNode p = head; while (p != null ) { if (p.val >= x) { p2.next = p; p2 = p2.next; } else { p1.next = p; p1 = p1.next; } ListNode temp = p.next; p.next = null ; p = temp; } p1.next = dummy2.next; return dummy1.next; } }
剑指 Offer II 027. 回文链表 - 力扣(Leetcode)
给你一个单链表的头节点 head ,请你判断该链表是否为回文链表。如果是,返回 true ;否则,返回 false
示例 1:
1 2 输入:head = [1,2,2,1] 输出:true
示例 2:
1 2 输入:head = [1,2] 输出:false
**进阶:**你能否用 O(n) 时间复杂度和 O(1) 空间复杂度解决此题?
快慢指针法
首先通过快慢指针找到链表中间节点,再配合链表长度的奇偶找到后半部分链表,然后把链表后半部分反转,最后再用反转的后半部分和前半部分一个个比较即可,如果二者一直相等则True,如果找到一个不相等就直接False。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 class Solution { public boolean isPalindrome (ListNode head) { ListNode fast = head; ListNode slow = head; while (fast != null && fast.next != null ){ fast = fast.next.next; slow = slow.next; } if (fast != null ) { slow = slow.next; } slow = reverse(slow); fast = head; while (slow != null ){ if (slow.val != fast.val){ return false ; } slow = slow.next; fast = fast.next; } return true ; } ListNode reverse (ListNode head) { ListNode pre = null ; ListNode cur = head; while (cur != null ){ ListNode tmp = cur.next; cur.next = pre; pre = cur; cur = tmp; } return pre; } }
将值复制到列表中后用双指针法
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 class Solution { public boolean isPalindrome (ListNode head) { List<Integer> list = new ArrayList <>(); ListNode cur = head; while (cur != null ){ list.add(cur.val); cur = cur.next; } int left = 0 ; int right = list.size() - 1 ; while (left < right){ if (!list.get(left).equals(list.get(right))){ return false ; } left++; right--; } return true ; } }
给你两个 非空 的链表,表示两个非负的整数。它们每位数字都是按照 逆序 的方式存储的,并且每个节点只能存储 一位 数字。
请你将两个数相加,并以相同形式返回一个表示和的链表。
你可以假设除了数字 0 之外,这两个数都不会以 0 开头。
示例 1:
1 2 3 输入:l1 = [2,4,3], l2 = [5,6,4] 输出:[7,0,8] 解释:342 + 465 = 807.
示例 2:
1 2 输入:l1 = [0], l2 = [0] 输出:[0]
示例 3:
1 2 输入:l1 = [9,9,9,9,9,9,9], l2 = [9,9,9,9] 输出:[8,9,9,9,0,0,0,1]
双指针法
这道题主要考察链表双指针技巧 和加法运算过程中对进位的处理 。注意这个 carry 变量的处理 ,在我们手动模拟加法过程的时候会经常用到。代码中还用到一个链表的算法题中是很常见的「虚拟头结点」技巧,也就是 dummy 节点。
我们同时遍历两个链表,逐位计算它们的和,并与当前位置的进位值相加。
具体而言,如果当前两个链表处相应位置的数字为 n1,n2,进位值为 carry,则它们的和为 n1+n2+carry;其中,答案链表处相应位置的数字为 (n1+n2+carry) % 10,而新的进位值为 ⌊(n1+n2+carry)/10⌋。
此外,如果链表遍历结束后,有 carry > 0,还需要在答案链表的后面附加一个节点,节点的值为 carry。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 class Solution { public ListNode addTwoNumbers (ListNode l1, ListNode l2) { ListNode p1 = l1, p2 = l2; ListNode dummy = new ListNode (-1 ); ListNode p = dummy; int carry = 0 ; while (p1 != null || p2 != null ) { int val = carry; if (p1 != null ) { val += p1.val; p1 = p1.next; } if (p2 != null ) { val += p2.val; p2 = p2.next; } carry = val / 10 ; val = val % 10 ; p.next = new ListNode (val); p = p.next; } if (carry > 0 ) { p.next = new ListNode (carry); } return dummy.next; } }
给你链表的头结点 head ,请将其按 升序 排列并返回 排序后的链表 。
示例 1:
1 2 输入:head = [4,2,1,3] 输出:[1,2,3,4]
示例 2:
1 2 输入:head = [-1,5,3,4,0] 输出:[-1,0,3,4,5]
示例 3:
题目的进阶问题要求达到 O(nlogn) 的时间复杂度和 O(1)的空间复杂度,时间复杂度是 O(nlogn)的排序算法包括归并排序、堆排序和快速排序 ,快速排序的最差时间复杂度是 O(n^2),其中最适合链表的排序算法是归并排序 。
归并排序基于分治算法。最容易想到的实现方式是自顶向下的递归实现,考虑到递归调用的栈空间,自顶向下归并排序的空间复杂度是 O(logn)。如果要达到O(1)的空间复杂度,则需要使用自底向上的实现方式。
对数组做归并排序的空间复杂度为 O(n),分别由新开辟数组 O(n)和递归函数调用 O(logn)组成,而根据链表特性:
数组额外空间:链表可以通过修改引用来更改节点顺序,无需像数组一样开辟额外空间 ;
递归额外空间:递归调用将带来O(logn)的空间复杂度,因此若希望达到 O(1)空间复杂度,则不能使用递归。
方法一:自顶向下归并排序
找到链表的中点,以中点为分界,将链表拆分成两个子链表。寻找链表的中点可以使用快慢指针的做法,快指针每次移动 2 步,慢指针每次移动 1 步,当快指针到达链表末尾时,慢指针指向的链表节点即为链表的中点。
对两个子链表分别排序。
将两个排序后的子链表合并,得到完整的排序后的链表。可以使用「21. 合并两个有序链表 」的做法,将两个有序的子链表进行合并。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 class Solution { public ListNode sortList (ListNode head) { return mergeSort(head); } private ListNode mergeSort (ListNode head) { if (head == null || head.next == null ) return head; ListNode fast = head.next, slow = head; while (fast != null && fast.next != null ) { slow = slow.next; fast = fast.next.next; } ListNode right = mergeSort(slow.next); slow.next = null ; ListNode left = mergeSort(head); return mergeList(left, right); } private ListNode mergeList (ListNode left, ListNode right) { ListNode tmpHead = new ListNode (-1 ); ListNode res = tmpHead; while (left != null && right != null ){ if (left.val < right.val){ res.next = left; left = left.next; } else { res.next = right; right = right.next; } res = res.next; } res.next = (left == null ? right : left); return tmpHead.next; } }
复杂度分析
时间复杂度:O(nlogn),其中 n 是链表的长度。
空间复杂度:O(logn),空间复杂度主要取决于递归调用的栈空间。
方法二:自底向上归并排序
将方法1改为迭代,节省递归占用的栈空间,每轮从链表上分别取1、2、4、8。。。。长度的子链表,两两依次合并模拟递归中的自底向上
用自底向上的方法实现归并排序,则可以达到 O(1) 的空间复杂度。
首先求得链表的长度 length,然后将链表拆分成子链表进行合并。
用 subLength表示每次需要排序的子链表的长度,初始时 subLength=1。
每次将链表拆分成若干个长度为 subLength 的子链表(最后一个子链表的长度可以小于 subLength),按照每两个子链表一组进行合并,合并后即可得到若干个长度为 subLength×2的有序子链表(最后一个子链表的长度可以小于 subLength×2)。合并两个子链表仍然使用「21. 合并两个有序链表 」的做法。
将 subLength 的值加倍,重复第 2 步,对更长的有序子链表进行合并操作,直到有序子链表的长度大于或等于 length,整个链表排序完毕。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 class Solution { public ListNode sortList (ListNode head) { if (head == null || head.next == null ) return head; int len = 0 ; ListNode curr = head; while (curr != null ) { len++; curr = curr.next; } ListNode dummy = new ListNode (-1 , head); for (int subLength = 1 ; subLength < len; subLength <<= 1 ) { ListNode tail = dummy; curr = dummy.next; while (curr != null ) { ListNode left = curr; ListNode right = cut(left, subLength); curr = cut(right, subLength); tail.next = merge(left, right); while (tail.next != null ) { tail = tail.next; } } } return dummy.next; } public ListNode cut (ListNode from, int step) { step--; while (from != null && step > 0 ) { from = from.next; step--; } if (from == null ) { return null ; } else { ListNode next = from.next; from.next = null ; return next; } } private ListNode merge (ListNode left, ListNode right) { ListNode dummy = new ListNode (0 ); ListNode res = dummy; while (left != null && right != null ){ if (left.val < right.val){ res.next = left; left = left.next; } else { res.next = right; right = right.next; } res = res.next; } res.next = (left == null ? right : left); return dummy.next; } }
方法三:快速排序
快排的partition操作变成了将单链表分割为<pivot 和 pivot以及 >=pivo t三个部分
递推对分割得到的两个单链表进行快排
回归时将pivot和排序后的两个单链表连接,并返回排序好的链表头尾节点
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 class Solution { public ListNode sortList (ListNode head) { if (head == null || head.next == null ) return head; ListNode newHead = new ListNode (-1 ); newHead.next = head; return quickSort(newHead, null ); } private ListNode quickSort (ListNode head, ListNode end) { if (head == end || head.next == end || head.next.next == end) return head; ListNode tmpHead = new ListNode (-1 ); ListNode partition = head.next; ListNode p = partition; ListNode tp = tmpHead; while (p.next != end){ if (p.next.val < partition.val){ tp.next = p.next; tp = tp.next; p.next = p.next.next; }else { p = p.next; } } tp.next = head.next; head.next = tmpHead.next; quickSort(head, partition); quickSort(partition, end); return head.next; } }
给定一个已排序的链表的头 head , 删除所有重复的元素,使每个元素只出现一次 。返回 已排序的链表 。
示例 1:
1 2 输入:head = [1,1,2] 输出:[1,2]
示例 2:
1 2 输入:head = [1,1,2,3,3] 输出:[1,2,3]
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 class Solution { public ListNode deleteDuplicates (ListNode head) { if (head == null || head.next == null ){ return head; } ListNode cur = head; while (cur != null && cur.next != null ){ if (cur.val == cur.next.val){ cur.next = cur.next.next; }else { cur = cur.next; } } return head; } } class Solution { public ListNode deleteDuplicates (ListNode head) { if (head == null ) return null ; ListNode slow = head, fast = head; while (fast != null ) { if (fast.val != slow.val) { slow.next = fast; slow = slow.next; } fast = fast.next; } slow.next = null ; return head; } } class Solution { public ListNode deleteDuplicates (ListNode head) { if (head == null || head.next == null ){ return head; } head.next = deleteDuplicates(head.next); if (head.val == head.next.val) { return head.next; } else { return head; } } } class Solution { public ListNode deleteDuplicates (ListNode head) { ListNode pre = null , cur = head; Set<Integer> set = new HashSet <Integer>(); while (cur != null ){ if (set.contains(cur.val)){ pre.next = cur.next; } else { set.add(cur.val); pre = cur; } cur = cur.next; } return head; } }
给定一个已排序的链表的头 head , 删除原始链表中所有重复数字的节点,只留下不同的数字 。返回 已排序的链表 。
示例 1:
1 2 输入:head = [1,2,3,3,4,4,5] 输出:[1,2,5]
示例 2:
1 2 输入:head = [1,1,1,2,3] 输出:[2,3]
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 class Solution { public ListNode deleteDuplicates (ListNode head) { if (head == null || head.next == null ){ return head; } ListNode dummy = new ListNode (-1 ); dummy.next = head; ListNode pre = dummy; ListNode cur = head; while (cur != null && cur.next != null ){ if (cur.val == cur.next.val){ int val = cur.val; while (cur != null && cur.val == val){ cur = cur.next; } pre.next = cur; } else { pre = cur; cur = cur.next; } } return dummy.next; } } class Solution { public ListNode deleteDuplicates (ListNode head) { if (head == null || head.next == null ) { return head; } if (head.val != head.next.val) { head.next = deleteDuplicates(head.next); return head; } else { ListNode notDup = head.next.next; while (notDup != null && notDup.val == head.val) { notDup = notDup.next; } return deleteDuplicates(notDup); } } }
编写代码,移除未排序链表中的重复节点。保留最开始出现的节点。
示例1:
1 2 输入:[1, 2, 3, 3, 2, 1] 输出:[1, 2, 3]
示例2:
1 2 输入:[1, 1, 1, 1, 2] 输出:[1, 2]
提示:
链表长度在[0, 20000]范围内。
链表元素在[0, 20000]范围内。
进阶:
如果不得使用临时缓冲区,该怎么解决?
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 class Solution { public ListNode removeDuplicateNodes (ListNode head) { ListNode pre = null , cur = head; Set<Integer> set = new HashSet <Integer>(); while (cur != null ){ if (set.contains(cur.val)){ pre.next = cur.next; } else { set.add(cur.val); pre = cur; } cur = cur.next; } return head; } }
剑指 Offer 35. 复杂链表的复制 - 力扣(Leetcode)
给你一个长度为 n 的链表,每个节点包含一个额外增加的随机指针 random ,该指针可以指向链表中的任何节点或空节点。
构造这个链表的 *深拷贝 **。 深拷贝应该正好由 n 个 **全新** 节点组成,其中每个新节点的值都设为其对应的原节点的值。新节点的 next 指针和 random 指针也都应指向复制链表中的新节点,并使原链表和复制链表中的这些指针能够表示相同的链表状态。*复制链表中的指针都不应指向原链表中的节点
例如,如果原链表中有 X 和 Y 两个节点,其中 X.random --> Y 。那么在复制链表中对应的两个节点 x 和 y ,同样有 x.random --> y 。
返回复制链表的头节点。
用一个由 n 个节点组成的链表来表示输入/输出中的链表。每个节点用一个 [val, random_index] 表示:
val:一个表示 Node.val 的整数。random_index:随机指针指向的节点索引(范围从 0 到 n-1);如果不指向任何节点,则为 null 。
你的代码 只 接受原链表的头节点 head 作为传入参数。
示例 1:
1 2 输入:head = [[7,null],[13,0],[11,4],[10,2],[1,0]] 输出:[[7,null],[13,0],[11,4],[10,2],[1,0]]
示例 2:
1 2 输入:head = [[1,1],[2,1]] 输出:[[1,1],[2,1]]
示例 3:
1 2 输入:head = [[3,null],[3,0],[3,null]] 输出:[[3,null],[3,0],[3,null]]
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 class Solution { public Node copyRandomList (Node head) { if (head == null ) return null ; Node cur = head; Map<Node, Node> map = new HashMap <>(); while (cur != null ) { map.put(cur, new Node (cur.val)); cur = cur.next; } cur = head; while (cur != null ) { map.get(cur).next = map.get(cur.next); map.get(cur).random = map.get(cur.random); cur = cur.next; } return map.get(head); } }
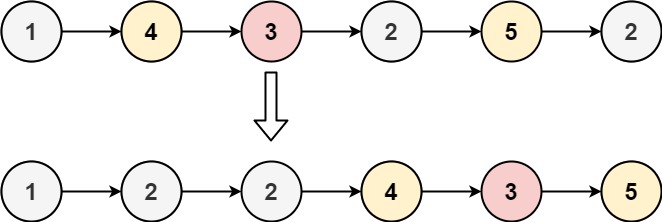
在一个大小为 n 且 n 为 偶数 的链表中,对于 0 <= i <= (n / 2) - 1 的 i ,第 i 个节点(下标从 0 开始)的孪生节点为第 (n-1-i) 个节点 。
比方说,n = 4 那么节点 0 是节点 3 的孪生节点,节点 1 是节点 2 的孪生节点。这是长度为 n = 4 的链表中所有的孪生节点。
孪生和 定义为一个节点和它孪生节点两者值之和。
给你一个长度为偶数的链表的头节点 head ,请你返回链表的 最大孪生和 。
示例 1:
1 2 3 4 5 6 输入:head = [5,4,2,1] 输出:6 解释: 节点 0 和节点 1 分别是节点 3 和 2 的孪生节点。孪生和都为 6 。 链表中没有其他孪生节点。 所以,链表的最大孪生和是 6 。
示例 2:
1 2 3 4 5 6 7 输入:head = [4,2,2,3] 输出:7 解释: 链表中的孪生节点为: - 节点 0 是节点 3 的孪生节点,孪生和为 4 + 3 = 7 。 - 节点 1 是节点 2 的孪生节点,孪生和为 2 + 2 = 4 。 所以,最大孪生和为 max(7, 4) = 7 。
示例 3:
1 2 3 4 输入:head = [1,100000] 输出:100001 解释: 链表中只有一对孪生节点,孪生和为 1 + 100000 = 100001 。
方法 1:栈
1、遍历链表,计算总结点数。
2、遍历链表的前一半节点,并入栈。
3、遍历链表后一半节点,并和出栈的节点求和,维护求和过程中的最大值即可。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 class Solution { public int pairSum (ListNode head) { int n = 0 ; ListNode tmp = head; while (tmp != null ){ n++; tmp = tmp.next; } Stack<Integer> stack = new Stack <>(); for (int i = 0 ; i < n / 2 ; i++){ stack.push(head.val); head = head.next; } int max = 0 ; for (int i = 0 ; i < n / 2 ; i++){ max = Math.max(max, stack.pop() + head.val); head = head.next; } return max; } }
方法 2:快慢指针 + 反转链表
1、快慢指针求后一半节点的首节点。
2、反转后一半链表节点。
3、同时遍历前一半节点和反转后的节点,并求和,维护求和过程中的最大值即可。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 class Solution { public int pairSum (ListNode head) { ListNode slow = head; ListNode fast = head.next; while (fast != null && fast.next != null ) { slow = slow.next; fast = fast.next.next; } slow = slow.next; ListNode cur = slow; ListNode pre = null ; while (cur != null ) { ListNode temp = cur.next; cur.next = pre; pre = cur; cur = temp; } int max = 0 ; while (head != null && pre != null ) { max = Math.max(max, head.val + pre.val); head = head.next; pre = pre.next; } return max; } }
③栈&队列&堆
❶普通队列-Queue
队列是一种先进先出的数据结构,元素从后端入队,然后从前端出队。
1 Queue<> queue = new LinkedList <>();
常用方法
函数
功能
add(E e)/offer(E e)
压入元素
remove()/poll()
弹出元素
element()/peek()
获取队头元素
isEmpty()
用于检查此队列是“空”还是“非空”
size()
获取队列长度
❷双端队列-Deque
Java集合提供了接口Deque来实现一个双端队列,它的功能是:
既可以添加到队尾,也可以添加到队首;
既可以从队首获取,又可以从队尾获取。
Deque有三种用途
1 2 3 Deque<> queue = new LinkedList <>(); Queue<> queue = new LinkedList <>();
Queue方法 等效Deque方法
add(e)
addLast(e)
offer(e)
offerLast(e)
remove()
removeFirst()
poll()
pollFirst()
element()
getFirst()
peek()
peekFirst()
1 2 3 Deque<Integer> deque = new ArrayDeque <>(); Deque<Integer> deque = new LinkedList <>();
第一个元素 (头部) 最后一个元素 (尾部)
插入 addFirst(e)/offerFirst(e)
addLast(e)/offerLast(e)
删除 removeFirst()/pollFirst()
removeLast()/pollLast()
获取 getFirst()/peekFirst()
getLast()/peekLast()
1 2 3 4 5 Deque<Integer> stack = new LinkedList <>(); Deque<Integer> stack = new ArrayDeque <>(); Stack<String> stack=new Stack <>();
堆栈方法 等效Deque方法
push(e)
addFirst(e)
pop()
removeFirst()
peek()
peekFirst()
Deque所有方法
方法
描述
添加功能
push (E)向队列头部插入一个元素,失败时抛出异常
addFirst (E)向队列头部插入一个元素,失败时抛出异常
addLast (E)向队列尾部插入一个元素,失败时抛出异常
offerFirst (E)向队列头部加入一个元素,失败时返回false
offerLast (E)向队列尾部加入一个元素,失败时返回false
获取功能
peek() 获取队列头部元素,队列为空时抛出异常
getFirst ()获取队列头部元素,队列为空时抛出异常
getLast ()获取队列尾部元素,队列为空时抛出异常
peekFirst ()获取队列头部元素,队列为空时返回null
peekLast ()获取队列尾部元素,队列为空时返回null
删除功能
removeFirstOccurrence (Object)删除第一次出现的指定元素,不存在时返回false
removeLastOccurrence (Object)删除最后一次出现的指定元素,不存在时返回false
弹出功能
pop ()弹出队列头部元素,队列为空时抛出异常
removeFirst ()弹出队列头部元素,队列为空时抛出异常
removeLast ()弹出队列尾部元素,队列为空时抛出异常
pollFirst ()弹出队列头部元素,队列为空时返回null
pollLast ()弹出队列尾部元素,队列为空时返回null
❸优先队列-PriorityQueue
优先级队列其实就是一个披着队列外衣的堆 ,因为优先队列对外接口只是从队头取元素,从队尾添加元素,再无其他取元素的方式,看起来就是一个队列。
PriorityQueue 是具有优先级别的队列,优先级队列的元素按照它们的自然顺序排序,或者由队列构造时提供的 Comparator 进行排序,这取决于使用的是哪个构造函数
构造函数
描述
PriorityQueue()
使用默认的容量(11)创建一个优队列,元素的顺序规则采用的是自然顺序
PriorityQueue(int initialCapacity)
使用默认指定的容量创建一个优队列,元素的顺序规则采用的是自然顺序
PriorityQueue(Comparator<? super E> comparator)
使用默认的容量队列,元素的顺序规则采用的是 comparator
1 2 3 4 5 6 7 8 9 10 PriorityQueue<Integer> numbers = new PriorityQueue <>(); PriorityQueue<Integer> numbers = new PriorityQueue <>(3 ); PriorityQueue<int []> queue = new PriorityQueue <int []>(new Comparator <int []>() { public int compare (int [] m, int [] n) { return m[1 ] - n[1 ]; } });
常用方法
1 2 3 4 5 peek() poll() add() size() isEmpty()
❹栈-Stack/Deque
栈是一种后进先出的数据结构,元素从顶端入栈,然后从顶端出栈。
注意:Java 堆栈 Stack 类已经过时,Java 官方推荐使用 Deque 替代 Stack 使用。Deque 堆栈操作方法:push()、pop()、peek()。
创建栈
1 2 3 4 5 6 7 8 9 10 11 12 13 Stack<E> stack=new Stack <>(); Stack<String> stack=new Stack <>(); Deque stack = new ArrayDeque <String>();Deque stack = new LinkedList <String>();stack.push("a" ); stack.pop(); stack.push("b" ); System.out.println(stack);
常用方法
函数
功能
push(T t)
压栈(向栈顶放入元素)
pop()
出栈(拿出栈顶元素,并得到它的值)
peek()
将栈顶元素返回,但是不从栈中移除它
search(Object o)
返回对象在此堆栈上的从1开始的位置。
isEmpty()
判断栈是否为空
size()
获取栈长度
❺堆-Heap
堆通常可以被看做是一棵完全二叉树的数组对象 。
堆的特性:
1.堆是完全二叉树 ,除了树的最后一层结点不需要是满的,其它的每一层从左到右都是满的,如果最后一层结点不是满的,那么要求左满右不满。
2.堆通常用数组来实现 。将二叉树的结点按照层级顺序放入数组中,根结点在位置1,它的子结点在位置2和3,而子结点的子结点则分别在位置4,5,6和7,以此类推。(0被废弃)
如果一个结点的位置为k,则它的父结点的位置为[k/2],而它的两个子结点的位置则分别为2k和2k+1。
这样,在不使用指针的情况下,我们也可以通过计算数组的索引在树中上下移动:从a[k]向上一层,就令k等于k/2,向下一层就令k等于2k或2k+1。
3.每个结点都大于等于它的两个子结点 。这里要注意堆中仅仅规定了每个结点大于等于它的两个子结点,但这两个子结点的顺序并没有做规定,跟我们之前学习的二叉查找树是有区别的。
堆的API设计
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 92 93 94 95 96 97 98 public class Heap <T extends Comparable <T>> { private T[] items; private int N; public Heap (int capacity) { this .items = (T[]) new Comparable [capacity + 1 ]; this .N = 0 ; } private boolean less (int i, int j) { return items[i].compareTo(items[j]) < 0 ; } private void exch (int i, int j) { T temp = items[i]; items[i] = items[j]; items[j] = temp; } public void insert (T t) { items[++N] = t; swim(N); } private void swim (int k) { while (k > 1 ) { if (less(k / 2 , k)) { exch(k / 2 , k); } k = k / 2 ; } } public T delMax () { T max = items[1 ]; exch(1 , N); items[N] = null ; N--; sink(1 ); return max; } private void sink (int k) { while (2 * k <= N) { int max; if (2 * k + 1 <= N) { if (less(2 * k, 2 * k + 1 )) { max = 2 * k + 1 ; } else { max = 2 * k; } } else { max = 2 * k; } if (!less(k, max)) { break ; } exch(k, max); k = max; } } public static void main (String[] args) { Heap<String> heap = new Heap <String>(20 ); heap.insert("A" ); heap.insert("B" ); heap.insert("C" ); heap.insert("D" ); heap.insert("E" ); heap.insert("F" ); heap.insert("G" ); String del; while ((del = heap.delMax()) != null ) { System.out.print(del + "," ); } } }
❻LeetCode真题
请你仅使用两个栈实现先入先出队列。队列应当支持一般队列支持的所有操作(push、pop、peek、empty):
实现 MyQueue 类:
void push(int x) 将元素 x 推到队列的末尾int pop() 从队列的开头移除并返回元素int peek() 返回队列开头的元素boolean empty() 如果队列为空,返回 true ;否则,返回 false
说明:
你 只能 使用标准的栈操作 —— 也就是只有 push to top, peek/pop from top, size, 和 is empty 操作是合法的。
你所使用的语言也许不支持栈。你可以使用 list 或者 deque(双端队列)来模拟一个栈,只要是标准的栈操作即可。
示例 1:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 输入: ["MyQueue", "push", "push", "peek", "pop", "empty"] [[], [1], [2], [], [], []] 输出: [null, null, null, 1, 1, false] 解释: MyQueue myQueue = new MyQueue(); myQueue.push(1); // queue is: [1] myQueue.push(2); // queue is: [1, 2] (leftmost is front of the queue) myQueue.peek(); // return 1 myQueue.pop(); // return 1, queue is [2] myQueue.empty(); // return false
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 class MyQueue { Deque<Integer> inStack; Deque<Integer> outStack; public MyQueue () { inStack = new ArrayDeque <>(); outStack = new ArrayDeque <>(); } public void push (int x) { inStack.push(x); } public int pop () { if (outStack.isEmpty()){ while (!inStack.isEmpty()){ outStack.push(inStack.pop()); } } return outStack.pop(); } public int peek () { if (outStack.isEmpty()){ while (!inStack.isEmpty()){ outStack.push(inStack.pop()); } } return outStack.peek(); } public boolean empty () { return inStack.isEmpty() && outStack.isEmpty(); } }
请你仅使用两个队列实现一个后入先出(LIFO)的栈,并支持普通栈的全部四种操作(push、top、pop 和 empty)。
实现 MyStack 类:
void push(int x) 将元素 x 压入栈顶。int pop() 移除并返回栈顶元素。int top() 返回栈顶元素。boolean empty() 如果栈是空的,返回 true ;否则,返回 false 。
注意:
你只能使用队列的基本操作 —— 也就是 push to back、peek/pop from front、size 和 is empty 这些操作。
你所使用的语言也许不支持队列。 你可以使用 list (列表)或者 deque(双端队列)来模拟一个队列 , 只要是标准的队列操作即可。
示例:
1 2 3 4 5 6 7 8 9 10 11 12 13 输入: ["MyStack", "push", "push", "top", "pop", "empty"] [[], [1], [2], [], [], []] 输出: [null, null, null, 2, 2, false] 解释: MyStack myStack = new MyStack(); myStack.push(1); myStack.push(2); myStack.top(); // 返回 2 myStack.pop(); // 返回 2 myStack.empty(); // 返回 False
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 class MyStack { Queue<Integer> queue1; Queue<Integer> queue2; public MyStack () { queue1 = new LinkedList (); queue2 = new LinkedList (); } public void push (int x) { queue2.offer(x); while (!queue1.isEmpty()){ queue2.offer(queue1.poll()); } Queue<Integer> temp = queue1; queue1 = queue2; queue2 = temp; } public int pop () { return queue1.poll(); } public int top () { return queue1.peek(); } public boolean empty () { return queue1.isEmpty(); } }
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 class MyStack { Queue<Integer> queue; public MyStack () { queue = new LinkedList <Integer>(); } public void push (int x) { int n = queue.size(); queue.offer(x); for (int i = 0 ; i < n; i++) { queue.offer(queue.poll()); } } public int pop () { return queue.poll(); } public int top () { return queue.peek(); } public boolean empty () { return queue.isEmpty(); } }
设计一个支持 push ,pop ,top 操作,并能在常数时间内检索到最小元素的栈。
实现 MinStack 类:
MinStack() 初始化堆栈对象。void push(int val) 将元素val推入堆栈。void pop() 删除堆栈顶部的元素。int top() 获取堆栈顶部的元素。int getMin() 获取堆栈中的最小元素。
示例 1:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 输入: ["MinStack","push","push","push","getMin","pop","top","getMin"] [[],[-2],[0],[-3],[],[],[],[]] 输出: [null,null,null,null,-3,null,0,-2] 解释: MinStack minStack = new MinStack(); minStack.push(-2); minStack.push(0); minStack.push(-3); minStack.getMin(); --> 返回 -3. minStack.pop(); minStack.top(); --> 返回 0. minStack.getMin(); --> 返回 -2.
辅助栈
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 class MinStack { Deque<Integer> stack; Deque<Integer> minStk; public MinStack () { stack = new ArrayDeque <>(); minStk = new ArrayDeque <>(); } public void push (int val) { stack.push(val); if (minStk.isEmpty() || val <= minStk.peek()){ minStk.push(val); } } public void pop () { if (stack.peek().equals(minStk.peek())) { minStk.pop(); } stack.pop(); } public int top () { return stack.peek(); } public int getMin () { return minStk.peek(); } }
一个栈实现
可以用一个栈,这个栈同时保存的是每个数字 val 进栈的时候的值 与 插入该值后的栈内最小值 。即每次新元素 val 入栈的时候保存一个元组:(当前值 val,栈内最小值) 。
这个元组是一个整体,同时进栈和出栈。即栈顶同时有值和栈内最小值,
push()当栈为空,保存元组 (val, val);当栈不空,保存元组 (val, min(此前栈内最小值,val)))pop()删除栈顶的元组。top()函数是获取栈顶的当前值 ,即栈顶元组的第一个值;getMin() 函数是获取栈内最小值 ,即栈顶元组的第二个值;pop() 函数时删除栈顶的元组。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 class MinStack { Deque<int []> stack; public MinStack () { stack = new ArrayDeque <>(); } public void push (int val) { if (stack.isEmpty()){ stack.push(new int []{val, val}); } else { stack.push(new int []{val, Math.min(val, stack.peek()[1 ])}); } } public void pop () { stack.pop(); } public int top () { return stack.peek()[0 ]; } public int getMin () { return stack.peek()[1 ]; } }
给定一个只包括 '(',')','{','}','[',']' 的字符串 s ,判断字符串是否有效。
有效字符串需满足:
左括号必须用相同类型的右括号闭合。
左括号必须以正确的顺序闭合。
每个右括号都有一个对应的相同类型的左括号。
示例 1:
示例 2:
示例 3:
栈是一种先进后出的数据结构,处理括号问题的时候尤其有用。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 class Solution { public boolean isValid (String s) { Deque<Character> stack = new ArrayDeque <>(); for (char c : s.toCharArray()){ if (c == '(' ) stack.push(')' ); else if (c == '{' ) stack.push('}' ); else if (c == '[' ) stack.push(']' ); else if (stack.isEmpty() || c != stack.pop()) return false ; } return stack.isEmpty(); } } class Solution { public boolean isValid (String s) { int n = s.length(); if (n % 2 == 1 ) return false ; Map<Character, Character> map = new HashMap <>() {{ put(')' , '(' ); put(']' , '[' ); put('}' , '{' ); }}; Deque<Character> stack = new LinkedList <>(); for (char c : s.toCharArray()){ if (map.containsKey(c)){ if (!stack.isEmpty() && stack.peek() == map.get(c)) { stack.pop(); } else { return false ; } } else { stack.push(c); } } return stack.isEmpty(); } }
给出由小写字母组成的字符串 S,重复项删除操作 会选择两个相邻且相同的字母,并删除它们。
在 S 上反复执行重复项删除操作,直到无法继续删除。
在完成所有重复项删除操作后返回最终的字符串。答案保证唯一。
示例:
1 2 3 4 输入:"abbaca" 输出:"ca" 解释: 例如,在 "abbaca" 中,我们可以删除 "bb" 由于两字母相邻且相同,这是此时唯一可以执行删除操作的重复项。之后我们得到字符串 "aaca",其中又只有 "aa" 可以执行重复项删除操作,所以最后的字符串为 "ca"。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 class Solution { public String removeDuplicates (String s) { Deque<Character> stack = new ArrayDeque <>(); for (char ch : s.toCharArray()){ if (stack.isEmpty() || stack.peek() != ch){ stack.push(ch); } else { stack.pop(); } } String str = "" ; while (!stack.isEmpty()){ str = stack.pop() + str; } return str; } } class Solution { public String removeDuplicates (String s) { char [] str = s.toCharArray(); int top = -1 ; for (int i = 0 ; i < s.length(); i++) { if (top == -1 || str[top] != str[i]) { str[++top] = str[i]; } else { top--; } } return String.valueOf(str, 0 , top + 1 ); } }
根据 逆波兰表示法 ,求表达式的值。
有效的算符包括 +、-、*、/ 。每个运算对象可以是整数,也可以是另一个逆波兰表达式。
注意 两个整数之间的除法只保留整数部分。
可以保证给定的逆波兰表达式总是有效的。换句话说,表达式总会得出有效数值且不存在除数为 0 的情况。
示例 1:
1 2 3 输入:tokens = ["2","1","+","3","*"] 输出:9 解释:该算式转化为常见的中缀算术表达式为:((2 + 1) * 3) = 9
示例 2:
1 2 3 输入:tokens = ["4","13","5","/","+"] 输出:6 解释:该算式转化为常见的中缀算术表达式为:(4 + (13 / 5)) = 6
示例 3:
1 2 3 4 5 6 7 8 9 10 输入:tokens = ["10","6","9","3","+","-11","*","/","*","17","+","5","+"] 输出:22 解释:该算式转化为常见的中缀算术表达式为: ((10 * (6 / ((9 + 3) * -11))) + 17) + 5 = ((10 * (6 / (12 * -11))) + 17) + 5 = ((10 * (6 / -132)) + 17) + 5 = ((10 * 0) + 17) + 5 = (0 + 17) + 5 = 17 + 5 = 22
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 class Solution { public int evalRPN (String[] tokens) { Deque<Integer> stack = new ArrayDeque <>(); for (String s : tokens){ if ("+-*/" .contains(s)) { int a = stack.pop(); int b = stack.pop(); if ("+" .equals(s)) stack.push(b + a); else if ("-" .equals(s)) stack.push(b - a); else if ("*" .equals(s)) stack.push(b * a); else if ("/" .equals(s)) stack.push(b / a); } else { stack.push(Integer.valueOf(s)); } } return stack.pop(); } } class Solution { public int evalRPN (String[] tokens) { Deque<Integer> stack = new ArrayDeque <>(); for (String s : tokens){ if ("+-*/" .contains(s)) { int a = stack.pop(); int b = stack.pop(); switch (s){ case "+" : stack.push(b + a); break ; case "-" : stack.push(b - a); break ; case "*" : stack.push(b * a); break ; case "/" : stack.push(b / a); break ; } } else { stack.push(Integer.valueOf(s)); } } return stack.pop(); } }
给你一个包含若干星号 * 的字符串 s 。
在一步操作中,你可以:
选中 s 中的一个星号。
移除星号 左侧 最近的那个 非星号 字符,并移除该星号自身。
返回移除 所有 星号之后的字符串**。**
示例 1:
1 2 3 4 5 6 7 输入:s = "leet**cod*e" 输出:"lecoe" 解释:从左到右执行移除操作: - 距离第 1 个星号最近的字符是 "leet**cod*e" 中的 't' ,s 变为 "lee*cod*e" 。 - 距离第 2 个星号最近的字符是 "lee*cod*e" 中的 'e' ,s 变为 "lecod*e" 。 - 距离第 3 个星号最近的字符是 "lecod*e" 中的 'd' ,s 变为 "lecoe" 。 不存在其他星号,返回 "lecoe" 。
示例 2:
1 2 3 输入:s = "erase*****" 输出:"" 解释:整个字符串都会被移除,所以返回空字符串。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 class Solution { public String removeStars (String s) { Deque<Character> stack = new ArrayDeque <>(); for (char c : s.toCharArray()){ if (c == '*' ){ stack.pop(); } else { stack.push(c); } } StringBuilder sb = new StringBuilder (); for (char c : stack){ sb.append(c); } return sb.reverse().toString(); } } class Solution { public String removeStars (String s) { StringBuilder sb = new StringBuilder (); for (char c : s.toCharArray()) { if (c != '*' ) { sb.append(c); } else { sb.deleteCharAt(sb.length() - 1 ); } } return sb.toString(); } }
给定一个整数数组 asteroids,表示在同一行的行星。
对于数组中的每一个元素,其绝对值表示行星的大小,正负表示行星的移动方向(正表示向右移动,负表示向左移动)。每一颗行星以相同的速度移动。
找出碰撞后剩下的所有行星。碰撞规则:两个行星相互碰撞,较小的行星会爆炸。如果两颗行星大小相同,则两颗行星都会爆炸。两颗移动方向相同的行星,永远不会发生碰撞。
示例 1:
1 2 3 输入:asteroids = [5,10,-5] 输出:[5,10] 解释:10 和 -5 碰撞后只剩下 10 。 5 和 10 永远不会发生碰撞。
示例 2:
1 2 3 输入:asteroids = [8,-8] 输出:[] 解释:8 和 -8 碰撞后,两者都发生爆炸。
示例 3:
1 2 3 输入:asteroids = [10,2,-5] 输出:[10] 解释:2 和 -5 发生碰撞后剩下 -5 。10 和 -5 发生碰撞后剩下 10 。
用栈保存当前存在的行星。
1、如果行星大于0,则不管左边行星的方向如何,都不会碰撞。
2、如果行星小于0,则判断左边行星,如果左边行星大于0,那么则会碰撞,否则不碰撞。
主要就是处理行星小于0,并且左边行星大于0的情况: 如果当前行星小于0,那么依次遍历栈顶元素,看是否会被销毁,并且记录当前行星的存活情况,最后再判断当前行星是否入栈。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 class Solution { public int [] asteroidCollision(int [] asteroids) { Deque<Integer> stack = new ArrayDeque <Integer>(); for (int aster : asteroids) { boolean alive = true ; while (alive && aster < 0 && !stack.isEmpty() && stack.peek() > 0 ) { if (stack.peek() < -aster){ alive = true ; } else { alive = false ; } if (stack.peek() <= -aster) { stack.pop(); } } if (alive) { stack.push(aster); } } int size = stack.size(); int [] ans = new int [size]; for (int i = size - 1 ; i >= 0 ; i--) { ans[i] = stack.pop(); } return ans; } }
给定一个经过编码的字符串,返回它解码后的字符串。
编码规则为: k[encoded_string],表示其中方括号内部的 encoded_string 正好重复 k 次。注意 k 保证为正整数。
你可以认为输入字符串总是有效的;输入字符串中没有额外的空格,且输入的方括号总是符合格式要求的。
此外,你可以认为原始数据不包含数字,所有的数字只表示重复的次数 k ,例如不会出现像 3a 或 2[4] 的输入。
示例 1:
1 2 输入:s = "3[a]2[bc]" 输出:"aaabcbc"
示例 2:
1 2 输入:s = "3[a2[c]]" 输出:"accaccacc"
示例 3:
1 2 输入:s = "2[abc]3[cd]ef" 输出:"abcabccdcdcdef"
示例 4:
1 2 输入:s = "abc3[cd]xyz" 输出:"abccdcdcdxyz"
构建辅助栈
, 遍历字符串
中每个字符
;
返回字符串 res。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 class Solution { public String decodeString (String s) { int k = 0 ; StringBuilder res = new StringBuilder (); ArrayDeque<Integer> kstack = new ArrayDeque <>(); ArrayDeque<StringBuilder> restack = new ArrayDeque <>(); for (char c : s.toCharArray()){ if (c == '[' ) { kstack.push(k); restack.push(res); k = 0 ; res = new StringBuilder (); } else if (c ==']' ){ int curk = kstack.pop(); StringBuilder temp = new StringBuilder (); for (int i = 0 ; i < curk; i++) temp.append(res); res = restack.pop().append(temp); } else if (c >= '0' && c <= '9' ){ k = c - '0' + k * 10 ; } else { res.append(c); } } return res.toString(); } }
给定一个整数数组 temperatures ,表示每天的温度,返回一个数组 answer ,其中 answer[i] 是指对于第 i 天,下一个更高温度出现在几天后。如果气温在这之后都不会升高,请在该位置用 0 来代替。
示例 1:
1 2 输入 : temperatures = [73,74,75,71,69,72,76,73] 输出 : [1,1,4,2,1,1,0,0]
示例 2:
1 2 输入 : temperatures = [30,40,50,60] 输出 : [1,1,1,0]
示例 3:
1 2 输入 : temperatures = [30,60,90] 输出 : [1,1,0]
暴力
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 class Solution { public int [] dailyTemperatures(int [] temperatures) { int n = temperatures.length; int [] res = new int [n]; for (int i = 0 ; i < n; i++){ int count = 0 ; for (int j = i + 1 ; j < n; j++){ if (temperatures[j] > temperatures[i]){ count = j - i; break ; } } res[i] = count; } return res; } }
单调栈
维护一个单调递减栈。
遍历整个数组,如果栈不空,且当前数字大于栈顶元素,取出栈顶元素,直接求出下标差就是二者的距离(由于当前数字大于栈顶元素的数字,所以一定是第一个大于栈顶元素的数)。
继续看新的栈顶元素,直到当前数字小于等于栈顶元素停止,然后将数字入栈,这样就可以一直保持递减栈,且每个数字和第一个大于它的数的距离也可以算出来。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 class Solution { public int [] dailyTemperatures(int [] temperatures) { int n = temperatures.length; int [] res = new int [n]; Deque<Integer> stack = new ArrayDeque <>(); for (int i = 0 ; i < n; i++){ while (!stack.isEmpty() && temperatures[i] > temperatures[stack.peek()]){ int x = stack.pop(); res[x] = i - x; } stack.push(i); } return res; } }
设计一个算法收集某些股票的每日报价,并返回该股票当日价格的 跨度 。
当日股票价格的 跨度 被定义为股票价格小于或等于今天价格的最大连续日数(从今天开始往回数,包括今天)。
例如,如果未来 7 天股票的价格是 [100,80,60,70,60,75,85],那么股票跨度将是 [1,1,1,2,1,4,6] 。
实现 StockSpanner 类:
StockSpanner() 初始化类对象。int next(int price) 给出今天的股价 price ,返回该股票当日价格的 跨度 。
示例:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 输入: ["StockSpanner", "next", "next", "next", "next", "next", "next", "next"] [[], [100], [80], [60], [70], [60], [75], [85]] 输出: [null, 1, 1, 1, 2, 1, 4, 6] 解释: StockSpanner stockSpanner = new StockSpanner(); stockSpanner.next(100); // 返回 1 stockSpanner.next(80); // 返回 1 stockSpanner.next(60); // 返回 1 stockSpanner.next(70); // 返回 2 stockSpanner.next(60); // 返回 1 stockSpanner.next(75); // 返回 4 ,因为截至今天的最后 4 个股价 (包括今天的股价 75) 都小于或等于今天的股价。 stockSpanner.next(85); // 返回 6
维护一个价格单调递减的栈使用「单调栈」,栈中每个元素存放的是 (price, cnt) 数据对,其中 price 表示价格,cnt 表示当前价格的跨度。
每次调用 next(price),我们将其与栈顶元素进行比较,如果栈顶元素的价格小于等于 price,则将当日价格的跨度 cnt 加上栈顶元素的跨度,然后将栈顶元素出栈,直到栈顶元素的价格大于 price,或者栈为空为止。
最后将 (price, cnt) 入栈,返回 cnt 即可。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 class StockSpanner { Deque<int []> stack; public StockSpanner () { stack = new LinkedList <int []>(); } public int next (int price) { int cnt = 1 ; while (!stack.isEmpty() && stack.peek()[0 ] <= price){ cnt += stack.pop()[1 ]; } stack.push(new int []{price, cnt}); return cnt; } }
给定 n 个非负整数,用来表示柱状图中各个柱子的高度。每个柱子彼此相邻,且宽度为 1 。
求在该柱状图中,能够勾勒出来的矩形的最大面积。
示例 1:
1 2 3 输入:heights = [2,1,5,6,2,3] 输出:10 解释:最大的矩形为图中红色区域,面积为 10
示例 2:
1 2 输入: heights = [2,4] 输出: 4
暴力
可以枚举以每个柱形为高度的最大矩形的面积。具体来说是:依次遍历柱形的高度,对于每一个高度分别向两边扩散,求出以当前高度为矩形的最大宽度多少。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 class Solution { public int largestRectangleArea (int [] heights) { int n = heights.length; int res = 0 ; for (int i = 0 ; i < n; i++){ int curHeight = heights[i]; int left = i; while (left > 0 && heights[left - 1 ] >= heights[i]){ left--; } int right = i; while (right < n - 1 && heights[right + 1 ] >= heights[i]){ right++; } int width = right - left + 1 ; res = Math.max(res, width * curHeight); } return res; } }
单调栈
上述写法中,我们需要再嵌套一层 while 循环来向左找到第一个比柱体 i 高度小的柱体,这个过程是 O(N) 的;
那么我们可以 O(1) 的获取柱体 i 左边第一个比它小的柱体吗?答案就是单调增栈,因为对于栈中的柱体来说,栈中下一个柱体就是左边第一个高度小于自身的柱体。
因此做法就很简单了,我们遍历每个柱体,若当前的柱体高度大于等于栈顶柱体的高度,就直接将当前柱体入栈,否则若当前的柱体高度小于栈顶柱体的高度,说明当前栈顶柱体找到了右边的第一个小于自身的柱体,那么就可以将栈顶柱体出栈来计算以其为高的矩形的面积了。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 class Solution { public int largestRectangleArea (int [] heights) { int [] arr = new int [heights.length + 2 ]; for (int i = 1 ; i < arr.length - 1 ; i++) { arr[i] = heights[i - 1 ]; } Deque<Integer> stack = new ArrayDeque <>(); int res = 0 ; for (int i = 0 ; i < arr.length; i++) { while (!stack.isEmpty() && arr[i] < arr[stack.peek()]) { int cur = stack.pop(); int width = i - stack.peek() - 1 ; res = Math.max(res, width * arr[cur]); } stack.push(i); } return res; } }
写一个 RecentCounter 类来计算特定时间范围内最近的请求。
请你实现 RecentCounter 类:
RecentCounter() 初始化计数器,请求数为 0 。int ping(int t) 在时间 t 添加一个新请求,其中 t 表示以毫秒为单位的某个时间,并返回过去 3000 毫秒内发生的所有请求数(包括新请求)。确切地说,返回在 [t-3000, t] 内发生的请求数。
保证 每次对 ping 的调用都使用比之前更大的 t 值。
示例 1:
1 2 3 4 5 6 7 8 9 10 11 12 输入: ["RecentCounter", "ping", "ping", "ping", "ping"] [[], [1], [100], [3001], [3002]] 输出: [null, 1, 2, 3, 3] 解释: RecentCounter recentCounter = new RecentCounter(); recentCounter.ping(1); // requests = [1],范围是 [-2999,1],返回 1 recentCounter.ping(100); // requests = [1, 100],范围是 [-2900,100],返回 2 recentCounter.ping(3001); // requests = [1, 100, 3001],范围是 [1,3001],返回 3 recentCounter.ping(3002); // requests = [1, 100, 3001, 3002],范围是 [2,3002],返回 3
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 class RecentCounter { Queue<Integer> queue; public RecentCounter () { queue = new ArrayDeque <>(); } public int ping (int t) { queue.offer(t); while (queue.peek() < t - 3000 ) { queue.poll(); } return queue.size(); } }
Dota2 的世界里有两个阵营:Radiant(天辉)和 Dire(夜魇)
Dota2 参议院由来自两派的参议员组成。现在参议院希望对一个 Dota2 游戏里的改变作出决定。他们以一个基于轮为过程的投票进行。在每一轮中,每一位参议员都可以行使两项权利中的 一 项:
禁止一名参议员的权利 :参议员可以让另一位参议员在这一轮和随后的几轮中丧失 所有的权利 。宣布胜利 :如果参议员发现有权利投票的参议员都是 同一个阵营的 ,他可以宣布胜利并决定在游戏中的有关变化。
给你一个字符串 senate 代表每个参议员的阵营。字母 'R' 和 'D'分别代表了 Radiant(天辉)和 Dire(夜魇)。然后,如果有 n 个参议员,给定字符串的大小将是 n。
以轮为基础的过程从给定顺序的第一个参议员开始到最后一个参议员结束。这一过程将持续到投票结束。所有失去权利的参议员将在过程中被跳过。
假设每一位参议员都足够聪明,会为自己的政党做出最好的策略,你需要预测哪一方最终会宣布胜利并在 Dota2 游戏中决定改变。输出应该是 "Radiant" 或 "Dire" 。
示例 1:
1 2 3 4 5 6 输入:senate = "RD" 输出:"Radiant" 解释: 第 1 轮时,第一个参议员来自 Radiant 阵营,他可以使用第一项权利让第二个参议员失去所有权利。 这一轮中,第二个参议员将会被跳过,因为他的权利被禁止了。 第 2 轮时,第一个参议员可以宣布胜利,因为他是唯一一个有投票权的人。
示例 2:
1 2 3 4 5 6 7 输入:senate = "RDD" 输出:"Dire" 解释: 第 1 轮时,第一个来自 Radiant 阵营的参议员可以使用第一项权利禁止第二个参议员的权利。 这一轮中,第二个来自 Dire 阵营的参议员会将被跳过,因为他的权利被禁止了。 这一轮中,第三个来自 Dire 阵营的参议员可以使用他的第一项权利禁止第一个参议员的权利。 因此在第二轮只剩下第三个参议员拥有投票的权利,于是他可以宣布胜利
使用两个队列 radiant 和 dire 分别按照投票顺序存储天辉方和夜魇方每一名议员的投票时间。随后我们就可以开始模拟整个投票的过程:
如果此时 radiant 为空 或者 dire 为空,那么就可以宣布另一方获得胜利;
如果均不为空,那么比较这两个队列的首元素,就可以确定当前行使权利的是哪一名议员。
如果 radiant 的首元素较小,那说明轮到天辉方的议员行使权利,其会挑选 dire 的首元素对应的那一名议员禁止权利。因此,将 dire 的首元素永久地弹出,并将 radiant 的首元素弹出,增加 n 之后再重新放回队列,这里 n 是给定的字符串 senate 的长度,即表示该议员会参与下一轮的投票。
同理,如果 dire 的首元素较小,那么会永久弹出 radiant 的首元素,剩余的处理方法也是类似的。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 class Solution { public String predictPartyVictory (String senate) { int n = senate.length(); Queue<Integer> radiant = new LinkedList <>(); Queue<Integer> dire = new LinkedList <>(); for (int i = 0 ; i < n; i++){ if (senate.charAt(i) == 'R' ){ radiant.offer(i); } else { dire.offer(i); } } while (!radiant.isEmpty() && !dire.isEmpty()){ int radiantIndex = radiant.poll(); int direIndex = dire.poll(); if (radiantIndex < direIndex) { radiant.offer(radiantIndex + n); } else { dire.offer(direIndex + n); } } return radiant.isEmpty() ? "Dire" : "Radiant" ; } }
给你一个整数数组 nums,有一个大小为 k 的滑动窗口从数组的最左侧移动到数组的最右侧。你只可以看到在滑动窗口内的 k 个数字。滑动窗口每次只向右移动一位。返回 滑动窗口中的最大值 。
示例 1:
1 2 3 4 5 6 7 8 9 10 11 输入:nums = [1,3,-1,-3,5,3,6,7], k = 3 输出:[3,3,5,5,6,7] 解释: 滑动窗口的位置 最大值 --------------- ----- [1 3 -1] -3 5 3 6 7 3 1 [3 -1 -3] 5 3 6 7 3 1 3 [-1 -3 5] 3 6 7 5 1 3 -1 [-3 5 3] 6 7 5 1 3 -1 -3 [5 3 6] 7 6 1 3 -1 -3 5 [3 6 7] 7
示例 2:
1 2 输入:nums = [1], k = 1 输出:[1]
方法一:优先队列
初始时,我们将数组 nums 的前 k 个元素和对应坐标放入优先队列中。
每当向右移动窗口时,就把新的元素放入优先队列中,此时堆顶的元素就是堆中所有元素的最大值。
特殊情况:到目前每次滑出窗口的元素并没有都从堆中删除,就会造成前面窗口的最大值一直在优先队列中,而窗口已经移走,最大值已经更换,前面窗口的最大值应该移出队列
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 class Solution { public int [] maxSlidingWindow(int [] nums, int k) { int n = nums.length; PriorityQueue<int []> pq = new PriorityQueue <int []>(new Comparator <int []>(){ public int compare (int [] a,int [] b) { return a[0 ] != b[0 ] ? b[0 ] - a[0 ] : b[1 ] - a[1 ]; } }); for (int i = 0 ; i < k; i++){ pq.offer(new int []{nums[i], i}); } int [] res = new int [n - k + 1 ]; res[0 ] = pq.peek()[0 ]; for (int i = k; i < n; i++){ pq.offer(new int []{nums[i], i}); while (pq.peek()[1 ] <= i - k){ pq.poll(); } res[i - k + 1 ] = pq.peek()[0 ]; } return res; } }
方法二:单调队列
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 class Solution { public int [] maxSlidingWindow(int [] nums, int k) { if (nums == null || nums.length < 2 ){ return nums; } Deque<Integer> deque = new LinkedList <>(); int [] res = new int [nums.length - k + 1 ]; for (int i = 0 ; i < nums.length; i++){ if (!deque.isEmpty() && deque.peek() <= i - k){ deque.pollFirst(); } while (!deque.isEmpty() && nums[deque.peekLast()] <= nums[i]){ deque.pollLast(); } deque.addLast(i); if (i + 1 >= k){ res[i + 1 - k] = nums[deque.peekFirst()]; } } return res; } }
剑指 Offer II 060. 出现频率最高的 k 个数字 - 力扣(Leetcode)
给你一个整数数组 nums 和一个整数 k ,请你返回其中出现频率前 k 高的元素。你可以按 任意顺序 返回答案。
示例 1:
1 2 输入 : nums = [1,1,1,2,2,3], k = 2 输出 : [1,2]
示例 2:
1 2 输入 : nums = [1], k = 1 输出 : [1]
首先,用一个 map 把每个元素出现的频率计算出来。然后,这道题就变成了 215. 数组中的第 K 个最大元素 ,只不过第 215 题让你求数组中元素值 e 排在第 k 大的那个元素,这道题让你求数组中元素值 map[e] 排在前 k 个的元素。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 class Solution { public int [] topKFrequent(int [] nums, int k) { Map<Integer, Integer> map = new HashMap <>(); for (int num : nums){ map.put(num, map.getOrDefault(num, 0 ) + 1 ); } PriorityQueue<int []> queue = new PriorityQueue <int []>(new Comparator <int []>() { public int compare (int [] a, int [] b) { return a[1 ] - b[1 ]; } }); for (Map.Entry<Integer, Integer> entry : map.entrySet()) { int num = entry.getKey(), count = entry.getValue(); queue.offer(new int []{num, count}); if (queue.size() > k) { queue.poll(); } } int [] res = new int [k]; for (int i = 0 ; i < k; ++i) { res[i] = queue.poll()[0 ]; } return res; } } class Solution { public int [] topKFrequent(int [] nums, int k) { Map<Integer, Integer> map = new HashMap <>(); for (int i : nums){ map.put(i, map.getOrDefault(i, 0 ) + 1 ); } PriorityQueue<Integer> queue = new PriorityQueue <>(new Comparator <Integer>() { @Override public int compare (Integer a, Integer b) { return map.get(a) - map.get(b); } }); for (Integer key : map.keySet()){ if (queue.size() < k) { queue.offer(key); } else if (map.get(key) > map.get(queue.peek())) { queue.poll(); queue.offer(key); } } int [] ret = new int [k]; for (int i = 0 ; i < k; ++i) { ret[i] = queue.poll(); } return ret; } }
剑指 Offer 41. 数据流中的中位数 - 力扣(Leetcode)
中位数 是有序整数列表中的中间值。如果列表的大小是偶数,则没有中间值,中位数是两个中间值的平均值。
例如 arr = [2,3,4] 的中位数是 3 。
例如 arr = [2,3] 的中位数是 (2 + 3) / 2 = 2.5 。
实现 MedianFinder 类:
MedianFinder() 初始化 MedianFinder 对象。void addNum(int num) 将数据流中的整数 num 添加到数据结构中。double findMedian() 返回到目前为止所有元素的中位数。与实际答案相差 10-5 以内的答案将被接受。
示例 1:
1 2 3 4 5 6 7 8 9 10 11 12 13 输入 ["MedianFinder", "addNum", "addNum", "findMedian", "addNum", "findMedian"] [[], [1], [2], [], [3], []] 输出 [null, null, null, 1.5, null, 2.0] 解释 MedianFinder medianFinder = new MedianFinder(); medianFinder.addNum(1); // arr = [1] medianFinder.addNum(2); // arr = [1, 2] medianFinder.findMedian(); // 返回 1.5 ((1 + 2) / 2) medianFinder.addNum(3); // arr[1, 2, 3] medianFinder.findMedian(); // return 2.0
如果元素不一样多,多的那个堆的堆顶元素就是中位数
如果元素一样多,两个堆堆顶元素的平均数是中位数
每次调用addNum函数的时候,我们比较一下large和small的元素个数,谁的元素少我们就加到谁那里,想要往large里添加元素,不能直接添加,而是要先往small里添加,然后再把small的堆顶元素加到large中;向small中添加元素同理。(要维护两堆元素个数之差不超过 1,且 large 堆顶元素要大于 small 堆顶)
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 class MedianFinder { PriorityQueue<Integer> large, small; public MedianFinder () { small = new PriorityQueue <>(); large = new PriorityQueue <>((x, y) -> (y - x)); } public void addNum (int num) { if (small.size() >= large.size()) { small.offer(num); large.offer(small.poll()); } else { large.offer(num); small.offer(large.poll()); } } public double findMedian () { if (large.size() < small.size()) { return small.peek(); } else if (large.size() > small.size()) { return large.peek(); } return (large.peek() + small.peek()) / 2.0 ; } }
给定整数数组 nums 和整数 k,请返回数组中第 k 个最大的元素。
请注意,你需要找的是数组排序后的第 k 个最大的元素,而不是第 k 个不同的元素。
你必须设计并实现时间复杂度为 O(n) 的算法解决此问题。
示例 1:
1 2 输入 : [3,2,1,5,6,4], k = 2 输出 : 5
示例 2:
1 2 输入 : [3,2,3,1,2,4,5,5,6], k = 4 输出 : 4
方法一:暴力法
1 2 3 4 5 6 7 class Solution { public int findKthLargest (int [] nums, int k) { int len = nums.length; Arrays.sort(nums); return nums[len - k]; } }
时间复杂度:O(NlogN),这里 N 是数组的长度,算法的性能消耗主要在排序,JDK 默认使用快速排序,因此时间复杂度为 O(NlogN);
空间复杂度:O(logN),这里认为编程语言使用的排序方法是「快速排序」,空间复杂度为递归调用栈的高度,为 logN。
方法二:优先队列
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 class Solution { public int findKthLargest (int [] nums, int k) { PriorityQueue<Integer> pq = new PriorityQueue <>(); for (int e : nums) { pq.offer(e); if (pq.size() > k) { pq.poll(); } } return pq.peek(); } }
二叉堆插入和删除的时间复杂度和堆中的元素个数有关,在这里我们堆的大小不会超过 k,所以插入和删除元素的复杂度是 O(logk),再套一层 for 循环,假设数组元素总数为 N,总的时间复杂度就是 O(Nlogk)。空间复杂度很显然就是二叉堆的大小,为 O(k)。
时间复杂度: O(Nlogk)
空间复杂度: O(k)
方法三:快速选择
「快速排序」虽然快,但是「快速排序」在遇到特殊测试用例(「顺序数组」或者「逆序数组」)的时候,递归树会退化成链表,时间复杂度会变成 O(N^2)。
事实上,有一个很经典的基于「快速排序」的算法,可以通过一次遍历,确定某一个元素在排序以后的位置,这个算法叫「快速选择」。
首先,题目问「第 k 个最大的元素」,相当于数组升序排序后「排名第 n - k 的元素」,为了方便表述,后文另 target = n - k。
partition 函数会将 nums[p] 排到正确的位置,使得 nums[left..p-1] < nums[p] < nums[p+1..right]:
这时候,虽然还没有把整个数组排好序,但我们已经让 nums[p] 左边的元素都比 nums[p] 小了,也就知道 nums[p] 的排名了。
那么我们可以把 p 和 target 进行比较,如果 p < target 说明第 target 大的元素在 nums[p+1..right] 中,如果 p > target 说明第 target 大的元素在 nums[left..p-1] 中 。
进一步,去 nums[p+1..right] 或者 nums[left..p-1] 这两个子数组中执行 partition 函数,就可以进一步缩小排在第 target 的元素的范围,最终找到目标元素。
注意:本题必须随机初始化 pivot 元素,否则通过时间会很慢,因为测试用例中有极端测试用例。为了应对极端测试用例,使得递归树加深,可以在循环一开始的时候,随机交换第 1 个元素与任意 1 个元素的位置。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 class Solution { public int findKthLargest (int [] nums, int k) { int len = nums.length; int target = len - k; int left = 0 ; int right = len - 1 ; return quickSelect(nums, left, right, target); } public static int quickSelect (int [] a, int l, int r, int k) { if (l > r) { return 0 ; } int p = partition(a, l, r); if (p == k) { return a[p]; } else { return p < k ? quickSelect(a, p + 1 , r, k) : quickSelect(a, l, p - 1 , k); } } static Random random = new Random (); public static int partition (int [] arr, int left, int right) { int randomIndex = random.nextInt(right - left + 1 ) + left; swap(arr, left, randomIndex); int pivot = arr[left]; int i = left; int j = right; while (i != j) { while (pivot <= arr[j] && i < j) j--; while (pivot >= arr[i] && i < j) i++; if (i < j) { swap(arr, i, j); } } swap(arr, left, i); return i; } public static void swap (int [] nums, int index1, int index2) { int temp = nums[index1]; nums[index1] = nums[index2]; nums[index2] = temp; } }
时间复杂度:O(N),这里 N 是数组的长度
空间复杂度:O(logN)
现有一个包含所有正整数的集合 [1, 2, 3, 4, 5, ...] 。
实现 SmallestInfiniteSet 类:
SmallestInfiniteSet() 初始化 SmallestInfiniteSet 对象以包含 所有 正整数。int popSmallest() 移除 并返回该无限集中的最小整数。void addBack(int num) 如果正整数 num 不 存在于无限集中,则将一个 num 添加 到该无限集中。
示例:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 输入 ["SmallestInfiniteSet", "addBack", "popSmallest", "popSmallest", "popSmallest", "addBack", "popSmallest", "popSmallest", "popSmallest"] [[], [2], [], [], [], [1], [], [], []] 输出 [null, null, 1, 2, 3, null, 1, 4, 5] 解释 SmallestInfiniteSet smallestInfiniteSet = new SmallestInfiniteSet(); smallestInfiniteSet.addBack(2); // 2 已经在集合中,所以不做任何变更。 smallestInfiniteSet.popSmallest(); // 返回 1 ,因为 1 是最小的整数,并将其从集合中移除。 smallestInfiniteSet.popSmallest(); // 返回 2 ,并将其从集合中移除。 smallestInfiniteSet.popSmallest(); // 返回 3 ,并将其从集合中移除。 smallestInfiniteSet.addBack(1); // 将 1 添加到该集合中。 smallestInfiniteSet.popSmallest(); // 返回 1 ,因为 1 在上一步中被添加到集合中, // 且 1 是最小的整数,并将其从集合中移除。 smallestInfiniteSet.popSmallest(); // 返回 4 ,并将其从集合中移除。 smallestInfiniteSet.popSmallest(); // 返回 5 ,并将其从集合中移除。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 class SmallestInfiniteSet { PriorityQueue<Integer> pq = new PriorityQueue <>(); public SmallestInfiniteSet () { for (int i = 1 ; i <= 1000 ; i++) { pq.offer(i); } } public int popSmallest () { return pq.poll(); } public void addBack (int num) { if (!pq.contains(num)){ pq.offer(num); } } } class SmallestInfiniteSet { private int min; PriorityQueue<Integer> pq; public SmallestInfiniteSet () { min = 1 ; pq = new PriorityQueue <>(); } public int popSmallest () { if (!pq.isEmpty()) { return pq.poll(); } return min++; } public void addBack (int num) { if (num < min && !pq.contains(num)) { pq.offer(num); } } }
给你两个下标从 0 开始的整数数组 nums1 和 nums2 ,两者长度都是 n ,再给你一个正整数 k 。你必须从 nums1 中选一个长度为 k 的 子序列 对应的下标。
对于选择的下标 i0 ,i1 ,…, ik - 1 ,你的 分数 定义如下:
nums1 中下标对应元素求和,乘以 nums2 中下标对应元素的 最小值 。用公示表示: (nums1[i0] + nums1[i1] +...+ nums1[ik - 1]) * min(nums2[i0] , nums2[i1], ... ,nums2[ik - 1]) 。
请你返回 最大 可能的分数。
一个数组的 子序列 下标是集合 {0, 1, ..., n-1} 中删除若干元素得到的剩余集合,也可以不删除任何元素。
示例 1:
1 2 3 4 5 6 7 8 9 输入:nums1 = [1,3,3,2], nums2 = [2,1,3,4], k = 3 输出:12 解释: 四个可能的子序列分数为: - 选择下标 0 ,1 和 2 ,得到分数 (1+3+3) * min(2,1,3) = 7 。 - 选择下标 0 ,1 和 3 ,得到分数 (1+3+2) * min(2,1,4) = 6 。 - 选择下标 0 ,2 和 3 ,得到分数 (1+3+2) * min(2,3,4) = 12 。 - 选择下标 1 ,2 和 3 ,得到分数 (3+3+2) * min(1,3,4) = 8 。 所以最大分数为 12 。
示例 2:
1 2 3 4 输入:nums1 = [4,2,3,1,1], nums2 = [7,5,10,9,6], k = 1 输出:30 解释: 选择下标 2 最优:nums1[2] * nums2[2] = 3 * 10 = 30 是最大可能分数。
根据nums2进行降序排序,这样每次取的数都是递减并且可以获取最小的乘数,又因为要让nums1中的和为尽可能的大,那么可以使用优先队列小根堆来实现每次抛出最小的那个数使得和尽可能的大
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 class Solution { public long maxScore (int [] nums1, int [] nums2, int k) { int n = nums1.length; Integer[] sorts = new Integer [n]; for (int i = 0 ; i < n; i++) { sorts[i] = i; } Arrays.sort(sorts, (a, b) -> nums2[b] - nums2[a]); PriorityQueue<Integer> pq = new PriorityQueue <>(); long sum = 0L ; for (int i = 0 ; i < k - 1 ; i++){ sum += nums1[sorts[i]]; pq.offer(nums1[sorts[i]]); } long ans = 0L ; for (int i = k - 1 ; i < n; i++){ sum += nums1[sorts[i]]; pq.offer(nums1[sorts[i]]); ans = Math.max(ans, nums2[sorts[i]] * sum); sum -= pq.poll(); } return ans; } }
给你一个下标从 0 开始的整数数组 costs ,其中 costs[i] 是雇佣第 i 位工人的代价。
同时给你两个整数 k 和 candidates 。我们想根据以下规则恰好雇佣 k 位工人:
总共进行 k 轮雇佣,且每一轮恰好雇佣一位工人。
在每一轮雇佣中,从最前面 candidates 和最后面 candidates 人中选出代价最小的一位工人,如果有多位代价相同且最小的工人,选择下标更小的一位工人。
比方说,costs = [3,2,7,7,1,2] 且 candidates = 2 ,第一轮雇佣中,我们选择第 4 位工人,因为他的代价最小 [3,2,7,7,1,2] 。
第二轮雇佣,我们选择第 1 位工人,因为他们的代价与第 4 位工人一样都是最小代价,而且下标更小,[3,2,7,7,2] 。注意每一轮雇佣后,剩余工人的下标可能会发生变化。
如果剩余员工数目不足 candidates 人,那么下一轮雇佣他们中代价最小的一人,如果有多位代价相同且最小的工人,选择下标更小的一位工人。
一位工人只能被选择一次。
返回雇佣恰好 k 位工人的总代价。
示例 1:
1 2 3 4 5 6 7 输入:costs = [17,12,10,2,7,2,11,20,8], k = 3, candidates = 4 输出:11 解释:我们总共雇佣 3 位工人。总代价一开始为 0 。 - 第一轮雇佣,我们从 [17,12,10,2,7,2,11,20,8] 中选择。最小代价是 2 ,有两位工人,我们选择下标更小的一位工人,即第 3 位工人。总代价是 0 + 2 = 2 。 - 第二轮雇佣,我们从 [17,12,10,7,2,11,20,8] 中选择。最小代价是 2 ,下标为 4 ,总代价是 2 + 2 = 4 。 - 第三轮雇佣,我们从 [17,12,10,7,11,20,8] 中选择,最小代价是 7 ,下标为 3 ,总代价是 4 + 7 = 11 。注意下标为 3 的工人同时在最前面和最后面 4 位工人中。 总雇佣代价是 11 。
示例 2:
1 2 3 4 5 6 7 输入:costs = [1,2,4,1], k = 3, candidates = 3 输出:4 解释:我们总共雇佣 3 位工人。总代价一开始为 0 。 - 第一轮雇佣,我们从 [1,2,4,1] 中选择。最小代价为 1 ,有两位工人,我们选择下标更小的一位工人,即第 0 位工人,总代价是 0 + 1 = 1 。注意,下标为 1 和 2 的工人同时在最前面和最后面 3 位工人中。 - 第二轮雇佣,我们从 [2,4,1] 中选择。最小代价为 1 ,下标为 2 ,总代价是 1 + 1 = 2 。 - 第三轮雇佣,少于 3 位工人,我们从剩余工人 [2,4] 中选择。最小代价是 2 ,下标为 0 。总代价为 2 + 2 = 4 。 总雇佣代价是 4 。
根据题意,优先元素小的元素,然后优先索引,根据此我们可以创建一个小顶堆
从candidates 前后选择对应的索引,遍历数组,将对应的索引添加到小顶堆
需要雇佣k位工人,遍历k次,弹出堆顶元素累加 result += costs[poll[0]],每次遍历,弹出的元素不再参于下一次计算,不停的比较 left 于 right
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 class Solution { public long totalCost (int [] costs, int k, int candidates) { PriorityQueue<int []> queue = new PriorityQueue <>(((o1, o2) -> { if (costs[o1[0 ]] == costs[o2[0 ]]) { return o1[0 ] - o2[0 ]; } else { return costs[o1[0 ]] - costs[o2[0 ]]; } })); int left = 0 , right = costs.length - 1 ; while (left < candidates) { queue.add(new int []{left++, 0 }); } while (Math.max(left, costs.length - candidates) <= right) { queue.add(new int []{right--, 1 }); } long result = 0 ; for (int i = 0 ; i < k; i++) { int [] poll = queue.poll(); result += costs[poll[0 ]]; if (left <= right) { if (poll[1 ] == 0 ) { queue.add(new int []{left++, 0 }); } else { queue.add(new int []{right--, 1 }); } } } return result; } }
由于每次获取的是代价最小的工人,所以采用小顶堆来存储元素,方便每次弹出最小的元素。使用两个小顶堆(left、right)分别存储最前面 candidates 个工人和最后面 candidates 个工人,同时使用双指针(i、j)来表明小顶堆包含的元素范围;
初始化:[0,candidate−1] 范围内的元素加入到 left 中,[n−candidate,n−1]范围内的元素加入到 right 中,i -> candidate, 如果长度够的话,j -> n−candidate−1。
总共遍历 k 次,每次遍历时,比较两个小顶堆的堆顶元素,将较小的代价弹出,累加到结果中,移动相应的指针(指针都是往中间移动,i++, j–),并将代价加入到对应的小顶堆中。
代码:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 class Solution { public long totalCost (int [] costs, int k, int candidates) long res = 0L ; PriorityQueue<Integer> left = new PriorityQueue<>(), right = new PriorityQueue<>(); int n = costs.length, i = 0 , j = n - 1 ; while (i < candidates) left.offer (costs[i++]); while (j >= i && j >= n - candidates) right.offer (costs[j--]); while (k-- > 0 ) { int a = left.isEmpty () ? Integer.MAX_VALUE : left.peek (); int b = right.isEmpty () ? Integer.MAX_VALUE : right.peek (); if (a <= b) { res += a; left.poll (); if (i <= j) left.offer (costs[i++]); } else { res += b; right.poll (); if (i <= j) right.offer (costs[j--]); } } return res; } }
④哈希表
❶基础知识
哈希表(Hash table),是根据关键码值 (Key value)而直接进行访问的数据结构。也就是说,它通过把关键码值映射到表中一个位置来访问记录,以加快查找的速度。这个映射函数叫做散列函数,存放记录的数组叫做哈希表。
常见的三种哈希结构
1 2 3 int [] hashTable = new int [26 ];
1 2 3 4 Set<Integer> set = new HashSet <>();
1 2 3 4 5 6 7 8 9 Map<Integer, Integer> map = new HashMap <>();
❷LeetCode真题
给定两个字符串 s 和 t ,编写一个函数来判断 t 是否是 s 的字母异位词。
**注意:**若 s 和 t 中每个字符出现的次数都相同,则称 s 和 t 互为字母异位词。
示例 1:
1 2 输入 : s = "anagram", t = "nagaram" 输出 : true
示例 2:
1 2 输入 : s = "rat", t = "car" 输出 : false
方法1:哈希表
首先判断两个字符串长度是否相等,不相等则直接返回 false
若相等,则初始化 26 个字母哈希表,遍历字符串 s 和 t
s 负责在对应位置增加,t 负责在对应位置减少
如果哈希表的值都为 0,则二者是字母异位词
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 class Solution { public boolean isAnagram (String s, String t) { if (s.length() != t.length()){ return false ; } int [] hashTable = new int [26 ]; for (int i = 0 ; i < s.length(); i++){ hashTable[s.charAt(i) - 'a' ]++; hashTable[t.charAt(i) - 'a' ]--; } for (int i = 0 ; i < 26 ; i++){ if (hashTable[i] != 0 ) return false ; } return true ; } }
方法2:排序
1 2 3 4 5 6 7 8 9 10 11 12 13 class Solution { public boolean isAnagram (String s, String t) { if (s.length() != t.length()) { return false ; } char [] str1 = s.toCharArray(); char [] str2 = t.toCharArray(); Arrays.sort(str1); Arrays.sort(str2); return Arrays.equals(str1, str2); } }
给你一个字符串数组,请你将 字母异位词 组合在一起。可以按任意顺序返回结果列表。
字母异位词 是由重新排列源单词的字母得到的一个新单词,所有源单词中的字母通常恰好只用一次。
示例 1:
1 2 输入 : strs = ["eat", "tea", "tan", "ate", "nat", "bat"] 输出 : [["bat"],["nat","tan"],["ate","eat","tea"]]
示例 2:
1 2 输入 : strs = [""] 输出 : [[""]]
示例 3:
1 2 输入 : strs = ["a"] 输出 : [["a"]]
方法1:排序
遍历字符串数组,对每个字符串中的字符排序,加入map对应的key的数组中。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 class Solution { public List<List<String>> groupAnagrams (String[] strs) { Map<String,List<String>> map = new HashMap <>(); for (String str : strs){ char [] arr = str.toCharArray(); Arrays.sort(arr); String key = new String (arr); List<String> list = map.getOrDefault(key, new ArrayList <String>()); list.add(str); map.put(key, list); } return new ArrayList <List<String>>(map.values()); } }
方法2:计数
由于字符串只包含小写字母,因此对于每个字符串,可以使用长度为 26 的数组记录每个字母出现的次数。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 class Solution { public List<List<String>> groupAnagrams (String[] strs) { Map<String, List<String>> map = new HashMap <String, List<String>>(); for (String str : strs) { int [] counts = new int [26 ]; int length = str.length(); for (int i = 0 ; i < length; i++) { counts[str.charAt(i) - 'a' ]++; } StringBuffer sb = new StringBuffer (); for (int i = 0 ; i < 26 ; i++) { if (counts[i] != 0 ) { sb.append((char ) ('a' + i)); sb.append(counts[i]); } } String key = sb.toString(); List<String> list = map.getOrDefault(key, new ArrayList <String>()); list.add(str); map.put(key, list); } return new ArrayList <List<String>>(map.values()); } }
如果可以使用以下操作从一个字符串得到另一个字符串,则认为两个字符串 接近 :
操作 1:交换任意两个
现有
字符。
操作 2:将一个
现有
字符的每次出现转换为另一个
现有
字符,并对另一个字符执行相同的操作。
例如,aacabb -> bbcbaa(所有 a 转化为 b ,而所有的 b 转换为 a )
你可以根据需要对任意一个字符串多次使用这两种操作。
给你两个字符串,word1 和 word2 。如果 word1 和 word2 接近 ,就返回 true ;否则,返回 false 。
示例 1:
1 2 3 4 5 输入:word1 = "abc", word2 = "bca" 输出:true 解释:2 次操作从 word1 获得 word2 。 执行操作 1:"abc" -> "acb" 执行操作 1:"acb" -> "bca"
示例 2:
1 2 3 输入:word1 = "a", word2 = "aa" 输出:false 解释:不管执行多少次操作,都无法从 word1 得到 word2 ,反之亦然。
示例 3:
1 2 3 4 5 6 输入:word1 = "cabbba", word2 = "abbccc" 输出:true 解释:3 次操作从 word1 获得 word2 。 执行操作 1:"cabbba" -> "caabbb" 执行操作 2:"caabbb" -> "baaccc" 执行操作 2:"baaccc" -> "abbccc"
示例 4:
1 2 3 输入:word1 = "cabbba", word2 = "aabbss" 输出:false 解释:不管执行多少次操作,都无法从 word1 得到 word2 ,反之亦然。
把题意翻译成充要条件就是:
两字符串的长度相同
两字符串的字符种类相同 , 例如,对于某个字符,要么都有,要么都没有。
符合:word1=abbccc,word2=caabbb,都有 a、b、c
不符合:word1=abbccc,word2=abbccd,word1 只有3类字符a、b、c
字符频次相同 。跟具体是什么字符无关,只要频次相同即可。
符合:word1=abbccc,word2=caabbb,都有1、2、3频次
不符合,word1=abbccc,word2=aabbcc,word1 频次有1、2、3,word2 的频次只有2
所以: 解题过程实际上在验证是否满足3个条件,而不是寻求满足 word1 转换到 word2 的方法
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 class Solution { public boolean closeStrings (String word1, String word2) { if (word1.length() != word2.length()) { return false ; } int [] time1 = new int [26 ]; int [] time2 = new int [26 ]; for (int i = 0 ; i < word1.length(); i++) { time1[word1.charAt(i) - 'a' ]++; time2[word2.charAt(i) - 'a' ]++; } for (int i = 0 ; i < 26 ; i++) { if ((time1[i] > 0 && time2[i] == 0 ) || (time2[i] > 0 && time1[i] == 0 )) { return false ; } } Arrays.sort(time1); Arrays.sort(time2); for (int i = 0 ; i < 26 ; i++) { if (time1[i] != time2[i]) { return false ; } } return true ; } }
给你一个下标从 0 开始、大小为 n x n 的整数矩阵 grid ,返回满足 Ri 行和 Cj 列相等的行列对 (Ri, Cj) 的数目*。*
如果行和列以相同的顺序包含相同的元素(即相等的数组),则认为二者是相等的。
示例 1:
1 2 3 4 输入:grid = [[3,2,1],[1,7,6],[2,7,7]] 输出:1 解释:存在一对相等行列对: - (第 2 行,第 1 列):[2,7,7]
示例 2:
1 2 3 4 5 6 输入:grid = [[3,1,2,2],[1,4,4,5],[2,4,2,2],[2,4,2,2]] 输出:3 解释:存在三对相等行列对: - (第 0 行,第 0 列):[3,1,2,2] - (第 2 行, 第 2 列):[2,4,2,2] - (第 3 行, 第 2 列):[2,4,2,2]
方法一:模拟
思路
按照题目要求,对任意一行,将它与每一列都进行比较,如果相等,则对结果加一,最后返回总数。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 class Solution { public int equalPairs (int [][] grid) { int res = 0 , n = grid.length; for (int row = 0 ; row < n; row++) { for (int col = 0 ; col < n; col++) { if (equal(row, col, n, grid)) { res++; } } } return res; } public boolean equal (int row, int col, int n, int [][] grid) { for (int i = 0 ; i < n; i++) { if (grid[row][i] != grid[i][col]) { return false ; } } return true ; } }
方法二:哈希表
map保存各行,然后遍历每列对比map中是否存在该列
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 class Solution { public int equalPairs (int [][] grid) { int n = grid.length; Map<List<Integer>, Integer> map = new HashMap <>(); for (int [] row : grid) { List<Integer> arr = new ArrayList <>(); for (int num : row) { arr.add(num); } map.put(arr, map.getOrDefault(arr, 0 ) + 1 ); } int res = 0 ; for (int j = 0 ; j < n; j++) { List<Integer> arr = new ArrayList <>(); for (int i = 0 ; i < n; i++) { arr.add(grid[i][j]); } if (map.containsKey(arr)) { res += map.get(arr); } } return res; } }
给定两个数组 nums1 和 nums2 ,返回它们的交集 。输出结果中的每个元素一定是 唯一 的。我们可以 不考虑输出结果的顺序 。
示例 1:
1 2 输入:nums1 = [1,2,2,1], nums2 = [2,2] 输出:[2]
示例 2:
1 2 3 输入:nums1 = [4,9,5], nums2 = [9,4,9,8,4] 输出:[9,4] 解释:[4,9] 也是可通过的
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 class Solution { public int [] intersection(int [] nums1, int [] nums2) { Set<Integer> set1 = new HashSet <>(); Set<Integer> set2 = new HashSet <>(); for (int i = 0 ; i < nums1.length; i++){ set1.add(nums1[i]); } for (int num : nums2){ if (set1.contains(num)){ set2.add(num); } } int [] res = new int [set2.size()]; int index = 0 ; for (int num : set2){ res[index++] = num; } return res; } }
编写一个算法来判断一个数 n 是不是快乐数。
「快乐数」 定义为:
对于一个正整数,每一次将该数替换为它每个位置上的数字的平方和。
然后重复这个过程直到这个数变为 1,也可能是 无限循环 但始终变不到 1。
如果这个过程 结果为 1,那么这个数就是快乐数。
如果 n 是 快乐数 就返回 true ;不是,则返回 false 。
示例 1:
1 2 3 4 5 6 7 输入:n = 19 输出:true 解释: 1 ^2 + 9 ^2 = 82 8 ^2 + 2 ^2 = 68 6 ^2 + 8 ^2 = 100 1 ^2 + 0 ^2 + 0 ^2 = 1
示例 2:
给一个数字 n,循环计算下一个数字,直到等于1
使用Set判断我们是否进入了一个循环。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 class Solution { public boolean isHappy (int n) { Set<Integer> set = new HashSet <>(); while (n != 1 && !set.contains(n)){ set.add(n); n = getNextNum(n); } return n == 1 ; } public int getNextNum (int n) { int nextNum = 0 ; while (n > 0 ){ int temp = n % 10 ; nextNum += temp * temp; n = n / 10 ; } return nextNum; }
给定一个整数数组 nums 和一个整数目标值 target,请你在该数组中找出 和为目标值 target两个 整数,并返回它们的数组下标。
你可以假设每种输入只会对应一个答案。但是,数组中同一个元素在答案里不能重复出现。
你可以按任意顺序返回答案。
示例 1:
1 2 3 输入:nums = [2,7,11,15], target = 9 输出:[0,1] 解释:因为 nums[0] + nums[1] == 9 ,返回 [0, 1] 。
示例 2:
1 2 输入:nums = [3,2,4], target = 6 输出:[1,2]
示例 3:
1 2 输入:nums = [3,3], target = 6 输出:[0,1]
1 2 3 4 5 6 7 8 9 10 11 12 class Solution { public int [] twoSum(int [] nums, int target) { HashMap<Integer,Integer> map = new HashMap <>(); for (int i = 0 ; i < nums.length; i++){ if (map.containsKey(target - nums[i])){ return new int []{map.get(target - nums[i]),i}; } map.put(nums[i],i); } return new int [0 ]; } }
给你四个整数数组 nums1、nums2、nums3 和 nums4 ,数组长度都是 n ,请你计算有多少个元组 (i, j, k, l) 能满足:
0 <= i, j, k, l < nnums1[i] + nums2[j] + nums3[k] + nums4[l] == 0
示例 1:
1 2 3 4 5 6 输入:nums1 = [1,2], nums2 = [-2,-1], nums3 = [-1,2], nums4 = [0,2] 输出:2 解释: 两个元组如下: 1. (0, 0, 0, 1) -> nums1[0] + nums2[0] + nums3[0] + nums4[1] = 1 + (-2) + (-1) + 2 = 0 2. (1, 1, 0, 0) -> nums1[1] + nums2[1] + nums3[0] + nums4[0] = 2 + (-1) + (-1) + 0 = 0
示例 2:
1 2 输入:nums1 = [0], nums2 = [0], nums3 = [0], nums4 = [0] 输出:1
该题等价于 计算 a + b + c + d = 0
首先定义 map,key放a和b两数之和,value 放a和b两数之和出现的次数。
遍历数组1和2,统计两个数组元素之和,和出现的次数,放到map中。
定义int变量res,用来统计 a+b+c+d = 0 出现的次数。
再遍历数组3和4,找到如果 0-(c+d) 在map中出现过的话,就把map中key对应的value统计出来。
最后返回统计值 res 就可以了
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 class Solution { public int fourSumCount (int [] nums1, int [] nums2, int [] nums3, int [] nums4) { Map<Integer, Integer> map = new HashMap <>(); for (int i : nums1){ for (int j: nums2){ map.put(i + j, map.getOrDefault(i + j, 0 ) + 1 ); } } int res = 0 ; for (int i : nums3){ for (int j: nums4){ if (map.containsKey(0 - (i + j))){ res += map.get(0 - (i + j)); } } } return res; } }
给你两个字符串:ransomNote 和 magazine ,判断 ransomNote 能不能由 magazine 里面的字符构成。
如果可以,返回 true ;否则返回 false 。
magazine 中的每个字符只能在 ransomNote 中使用一次。
示例 1:
1 2 输入:ransomNote = "a", magazine = "b" 输出:false
示例 2:
1 2 输入:ransomNote = "aa", magazine = "ab" 输出:false
示例 3:
1 2 输入:ransomNote = "aa", magazine = "aab" 输出:true
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 class Solution { public boolean canConstruct (String ransomNote, String magazine) { Map<Character, Integer> map = new HashMap <>(); for (char ch : magazine.toCharArray()){ map.put(ch, map.getOrDefault(ch, 0 ) + 1 ); } for (char ch : ransomNote.toCharArray()){ map.put(ch, map.getOrDefault(ch, 0 ) - 1 ); } for (Integer value : map.values() ){ if (value < 0 ) return false ; } return true ; } } class Solution { public boolean canConstruct (String ransomNote, String magazine) { int [] hashTable = new int [26 ]; for (char ch : magazine.toCharArray()){ hashTable[ch - 'a' ]++; } for (char ch : ransomNote.toCharArray()){ hashTable[ch - 'a' ]--; } for (int value : hashTable){ if (value < 0 ){ return false ; } } return true ; } } class Solution { public boolean canConstruct (String ransomNote, String magazine) { int [] hashTable = new int [26 ]; for (char ch : magazine.toCharArray()) { hashTable[ch - 'a' ]++; } for (char ch : ransomNote.toCharArray()) { if (--hashTable[ch - 'a' ] < 0 ) return false ; } return true ; } }
给你一个整数数组 nums ,判断是否存在三元组 [nums[i], nums[j], nums[k]] 满足 i != j、i != k 且 j != k ,同时还满足 nums[i] + nums[j] + nums[k] == 0 。请你返回所有和为 0 且不重复的三元组。
**注意:**答案中不可以包含重复的三元组。
示例 1:
1 2 3 4 5 6 7 8 输入:nums = [-1,0,1,2,-1,-4] 输出:[[-1,-1,2],[-1,0,1]] 解释: nums[0] + nums[1] + nums[2] = (-1) + 0 + 1 = 0 。 nums[1] + nums[2] + nums[4] = 0 + 1 + (-1) = 0 。 nums[0] + nums[3] + nums[4] = (-1) + 2 + (-1) = 0 。 不同的三元组是 [-1,0,1] 和 [-1,-1,2] 。 注意,输出的顺序和三元组的顺序并不重要。
示例 2:
1 2 3 输入:nums = [0,1,1] 输出:[] 解释:唯一可能的三元组和不为 0 。
示例 3:
1 2 3 输入:nums = [0,0,0] 输出:[[0,0,0]] 解释:唯一可能的三元组和为 0 。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 private List<List<Integer>> directlySolution (int [] nums) { if (nums == null || nums.length <= 2 ) { return Collections.emptyList(); } Arrays.sort(nums); Set<List<Integer>> result = new LinkedHashSet <>(); for (int i = 0 ; i < nums.length; i++) { for (int j = i+1 ; j < nums.length; j++) { for (int k = j+1 ; k < nums.length; k++) { if (nums[i] + nums[j] + nums[k] == 0 ) { List<Integer> value = Arrays.asList(nums[i], nums[j], nums[k]); result.add(value); } } } } return new ArrayList <>(result); }
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 class Solution { public List<List<Integer>> threeSum (int [] nums) { List<List<Integer>> result = new ArrayList <>(); Map<Integer, Integer> map = new HashMap <>(); for (int i = 0 ; i < nums.length; i++){ map.put(nums[i], i); } for (int i = 0 ; i < nums.length; i++){ for (int j = i + 1 ; j < nums.length; j++){ int c = 0 - (nums[i] + nums[j]); if (map.containsKey(c) && map.get(c) > j){ List<Integer> list = new ArrayList <>(); list.add(nums[i]); list.add(nums[j]); list.add(c); Collections.sort(list); if (!result.contains(list)){ result.add(list); } } } } return result; } }
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 class Solution { public static List<List<Integer>> threeSum (int [] nums) { List<List<Integer>> ans = new ArrayList (); int len = nums.length; if (nums == null || len < 3 ) return ans; Arrays.sort(nums); for (int i = 0 ; i < len ; i++) { if (nums[i] > 0 ) break ; if (i > 0 && nums[i] == nums[i-1 ]) continue ; int L = i + 1 ; int R = len - 1 ; while (L < R){ int sum = nums[i] + nums[L] + nums[R]; if (sum < 0 ) L++; else if (sum > 0 ) R--; else if (sum == 0 ){ ans.add(Arrays.asList(nums[i],nums[L],nums[R])); while (L < R && nums[L] == nums[L+1 ]) L++; while (L < R && nums[R] == nums[R-1 ]) R--; L++; R--; } } } return ans; } }
给你一个由 n 个整数组成的数组 nums ,和一个目标值 target 。请你找出并返回满足下述全部条件且不重复 的四元组 [nums[a], nums[b], nums[c], nums[d]] (若两个四元组元素一一对应,则认为两个四元组重复):
0 <= a, b, c, d < na、b、c 和 d 互不相同 nums[a] + nums[b] + nums[c] + nums[d] == target
你可以按 任意顺序 返回答案 。
示例 1:
1 2 输入:nums = [1,0,-1,0,-2,2], target = 0 输出:[[-2,-1,1,2],[-2,0,0,2],[-1,0,0,1]]
示例 2:
1 2 输入:nums = [2,2,2,2,2], target = 8 输出:[[2,2,2,2]]
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 class Solution { public List<List<Integer>> fourSum (int [] nums, int target) { List<List<Integer>> res = new ArrayList <>(); Arrays.sort(nums); for (int i = 0 ; i < nums.length; i++){ if (nums[i] > 0 && nums[i] > target) break ; if (i > 0 && nums[i] == nums[i -1 ]) continue ; for (int j = i + 1 ; j < nums.length; j++){ if (j > i + 1 && nums[j - 1 ] == nums[j]) continue ; int L = j + 1 , R = nums.length - 1 ; while (L < R) { int sum = nums[i] + nums[j] + nums[L] + nums[R]; if (sum > target) R--; else if (sum < target) L++; else { res.add(Arrays.asList(nums[i],nums[j],nums[L],nums[R])); while (L < R && nums[L] == nums[L + 1 ]) L++; while (L < R && nums[R] == nums[R - 1 ]) R--; L++; R--; } } } } return res; } }
请你设计并实现一个满足 LRU (最近最少使用) 缓存 约束的数据结构。
实现 LRUCache 类:
LRUCache(int capacity) 以 正整数 作为容量 capacity 初始化 LRU 缓存int get(int key) 如果关键字 key 存在于缓存中,则返回关键字的值,否则返回 -1 。void put(int key, int value) 如果关键字 key 已经存在,则变更其数据值 value ;如果不存在,则向缓存中插入该组 key-value 。如果插入操作导致关键字数量超过 capacity ,则应该 逐出 最久未使用的关键字。
函数 get 和 put 必须以 O(1) 的平均时间复杂度运行。
示例:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 输入 ["LRUCache" , "put" , "put" , "get" , "put" , "get" , "put" , "get" , "get" , "get" ] [[2 ], [1 , 1 ], [2 , 2 ], [1 ], [3 , 3 ], [2 ], [4 , 4 ], [1 ], [3 ], [4 ]] 输出 [null , null , null , 1 , null , -1 , null , -1 , 3 , 4 ] 解释 LRUCache lRUCache = new LRUCache (2 );lRUCache.put(1 , 1 ); lRUCache.put(2 , 2 ); lRUCache.get(1 ); lRUCache.put(3 , 3 ); lRUCache.get(2 ); lRUCache.put(4 , 4 ); lRUCache.get(1 ); lRUCache.get(3 ); lRUCache.get(4 );
LRU:把最不常用的淘汰。把所有元素按使用情况排序,最近使用的移动到末尾,缓存满了就从头删除。
方法一:用 Java 的内置类型 LinkedHashMap 实现
哈希表查找快,但是数据无固定顺序;链表有顺序之分,插入删除快,但是查找慢,所以结合二者的长处,可以形成一种新的数据结构:哈希链表 LinkedHashMap
首先要接收一个 capacity 参数作为缓存的最大容量,然后实现两个 API,一个是 put(key, val) 方法存入键值对,另一个是 get(key) 方法获取 key 对应的 val,如果 key 不存在则返回 -1。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 class LRUCache { int cap; LinkedHashMap<Integer, Integer> cache; public LRUCache (int capacity) { this .cap = capacity; cache = new LinkedHashMap <>(); } public int get (int key) { if (cache.containsKey(key)){ makeRecently(key); return cache.get(key); } else { return -1 ; } } public void put (int key, int value) { if (cache.containsKey(key)){ cache.put(key, value); makeRecently(key); } else { if (cache.size() >= this .cap){ int lruKey = cache.keySet().iterator().next(); cache.remove(lruKey); } cache.put(key, value); } } public void makeRecently (int key) { int value = cache.get(key); cache.remove(key); cache.put(key, value); } } class LRUCache extends LinkedHashMap <Integer, Integer>{ private int capacity; public LRUCache (int capacity) { super (capacity, 0.75F , true ); this .capacity = capacity; } public int get (int key) { return super .getOrDefault(key, -1 ); } public void put (int key, int value) { super .put(key, value); } @Override protected boolean removeEldestEntry (Map.Entry<Integer, Integer> eldest) { return size() > capacity; } } class LRUCache { int capacity; LinkedHashMap<Integer, Integer> cache; public LRUCache (int capacity) { this .capacity = capacity; cache = new LinkedHashMap <Integer, Integer>(capacity, 0.75f , true ) { @Override protected boolean removeEldestEntry (Map.Entry eldest) { return cache.size() > capacity; } }; } public int get (int key) { return cache.getOrDefault(key, -1 ); } public void put (int key, int value) { cache.put(key, value); } }
方法二:自己实现LinkeHashMap
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 92 93 94 95 96 97 98 99 100 101 102 103 104 105 106 107 108 109 110 111 112 113 114 115 116 117 118 119 120 121 122 123 124 125 126 127 128 129 130 class LRUCache { private HashMap<Integer, Node> map; private DoubleList cache; private int cap; public LRUCache (int capacity) { this .cap = capacity; map = new HashMap <>(); cache = new DoubleList (); } public int get (int key) { if (!map.containsKey(key)) { return -1 ; } makeRecently(key); return map.get(key).val; } public void put (int key, int val) { if (map.containsKey(key)) { Node node = map.get(key); node.val = val; makeRecently(key); } else { if (cache.size() >= this .cap){ removeLeastRecently(); } addRecently(key, val); } } private void makeRecently (int key) { Node x = map.get(key); cache.remove(x); cache.addLast(x); } private void addRecently (int key, int val) { Node x = new Node (key, val); cache.addLast(x); map.put(key, x); } private void removeLeastRecently () { Node deletedNode = cache.removeFirst(); map.remove(deletedNode.key); } } class Node { int key, val; Node prev, next; public Node () {} public Node (int key, int val) { this .key = key; this .val = val; } } class DoubleList { private Node head, tail; private int size; public DoubleList () { head = new Node (0 , 0 ); tail = new Node (0 , 0 ); head.next = tail; tail.prev = head; size = 0 ; } public void addLast (Node x) { x.prev = tail.prev; x.next = tail; tail.prev.next = x; tail.prev = x; size++; } public void remove (Node x) { x.prev.next = x.next; x.next.prev = x.prev; size--; } public Node removeFirst () { if (head.next == tail){ return null ; } Node first = head.next; remove(first); return first; } public int size () { return size; } }
给定一个未排序的整数数组 nums ,找出数字连续的最长序列(不要求序列元素在原数组中连续)的长度。
请你设计并实现时间复杂度为 O(n) 的算法解决此问题。
示例 1:
1 2 3 输入:nums = [100,4,200,1,3,2] 输出:4 解释:最长数字连续序列是 [1, 2, 3, 4]。它的长度为 4。
示例 2:
1 2 输入:nums = [0,3,7,2,5,8,4,6,0,1] 输出:9
排序
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 class Solution { public int longestConsecutive (int [] nums) { if (nums.length == 0 ) return 0 ; Arrays.sort(nums); int max = 1 , curr = 1 , last = nums[0 ]; for (int i = 1 ; i < nums.length; i++) { if (nums[i] == last) continue ; if (nums[i] == last + 1 ) curr++; else { max = Math.max(max, curr); curr = 1 ; } last = nums[i]; } max = Math.max(max, curr); return max; } }
哈希表
想找连续序列,首先要找到这个连续序列的开头元素 ,然后递增,看看之后有多少个元素还在 nums 中,即可得到最长连续序列的长度了。
我们可以用空间换时间的思路,把数组元素放到哈希集合里面,然后去寻找连续序列的第一个元素,即可在 O(N) 时间找到答案。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 class Solution { public int longestConsecutive (int [] nums) { int res = 0 ; Set<Integer> set = new HashSet <>(); for (int num : nums){ set.add(num); } for (int num : set){ if (set.contains(num - 1 )) continue ; int curNum = num; while (set.contains(curNum + 1 )){ curNum++; } res = Math.max(res, curNum - num + 1 ); } return res; } }
给你两个下标从 0 开始的整数数组 nums1 和 nums2 ,请你返回一个长度为 2 的列表 answer ,其中:
answer[0] 是 nums1 中所有 不 存在于 nums2 中的 不同 整数组成的列表。answer[1] 是 nums2 中所有 不 存在于 nums1 中的 不同 整数组成的列表。
**注意:**列表中的整数可以按 任意 顺序返回。
示例 1:
1 2 3 4 5 输入:nums1 = [1,2,3], nums2 = [2,4,6] 输出:[[1,3],[4,6]] 解释: 对于 nums1 ,nums1[1] = 2 出现在 nums2 中下标 0 处,然而 nums1[0] = 1 和 nums1[2] = 3 没有出现在 nums2 中。因此,answer[0] = [1,3]。 对于 nums2 ,nums2[0] = 2 出现在 nums1 中下标 1 处,然而 nums2[1] = 4 和 nums2[2] = 6 没有出现在 nums2 中。因此,answer[1] = [4,6]。
示例 2:
1 2 3 4 5 输入:nums1 = [1,2,3,3], nums2 = [1,1,2,2] 输出:[[3],[]] 解释: 对于 nums1 ,nums1[2] 和 nums1[3] 没有出现在 nums2 中。由于 nums1[2] == nums1[3] ,二者的值只需要在 answer[0] 中出现一次,故 answer[0] = [3]。 nums2 中的每个整数都在 nums1 中出现,因此,answer[1] = [] 。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 class Solution { public List<List<Integer>> findDifference (int [] nums1, int [] nums2) { Set<Integer> set1 = new HashSet <>(); Set<Integer> set2 = new HashSet <>(); for (int num : nums1){ set1.add(num); } for (int num : nums2){ set2.add(num); } List<Integer> ans1 = new ArrayList <>(); List<Integer> ans2 = new ArrayList <>(); for (int num : set1) { if (!set2.contains(num)){ ans1.add(num); } } for (int num : set2) { if (!set1.contains(num)){ ans2.add(num); } } List<List<Integer>> ans = new ArrayList <>(); ans.add(ans1); ans.add(ans2); return ans; } }
给你一个整数数组 arr,请你帮忙统计数组中每个数的出现次数。
如果每个数的出现次数都是独一无二的,就返回 true;否则返回 false。
示例 1:
1 2 3 输入:arr = [1,2,2,1,1,3] 输出:true 解释:在该数组中,1 出现了 3 次,2 出现了 2 次,3 只出现了 1 次。没有两个数的出现次数相同。
示例 2:
示例 3:
1 2 输入:arr = [-3,0,1,-3,1,1,1,-3,10,0] 输出:true
1 2 3 4 5 6 7 8 9 10 11 12 13 14 class Solution { public boolean uniqueOccurrences (int [] arr) { Map<Integer, Integer> map = new HashMap <>(); for (int i : arr){ map.put(i, map.getOrDefault(i, 0 ) + 1 ); } Set<Integer> set = new HashSet <Integer>(); for (int value : map.values()){ set.add(value); } return set.size() == map.size(); } }
实现RandomizedSet 类:
RandomizedSet() 初始化 RandomizedSet 对象bool insert(int val) 当元素 val 不存在时,向集合中插入该项,并返回 true ;否则,返回 false 。bool remove(int val) 当元素 val 存在时,从集合中移除该项,并返回 true ;否则,返回 false 。int getRandom() 随机返回现有集合中的一项(测试用例保证调用此方法时集合中至少存在一个元素)。每个元素应该有 相同的概率 被返回。
你必须实现类的所有函数,并满足每个函数的 平均 时间复杂度为 O(1) 。
示例:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 输入 ["RandomizedSet", "insert", "remove", "insert", "getRandom", "remove", "insert", "getRandom"] [[], [1], [2], [2], [], [1], [2], []] 输出 [null, true, false, true, 2, true, false, 2] 解释 RandomizedSet randomizedSet = new RandomizedSet(); randomizedSet.insert(1); // 向集合中插入 1 。返回 true 表示 1 被成功地插入。 randomizedSet.remove(2); // 返回 false ,表示集合中不存在 2 。 randomizedSet.insert(2); // 向集合中插入 2 。返回 true 。集合现在包含 [1,2] 。 randomizedSet.getRandom(); // getRandom 应随机返回 1 或 2 。 randomizedSet.remove(1); // 从集合中移除 1 ,返回 true 。集合现在包含 [2] 。 randomizedSet.insert(2); // 2 已在集合中,所以返回 false 。 randomizedSet.getRandom(); // 由于 2 是集合中唯一的数字,getRandom 总是返回 2 。
对于 insert 和 remove 操作容易想到使用「哈希表」来实现 O(1) 复杂度,但对于 getRandom 操作,比较理想的情况是能够在一个数组内随机下标进行返回。
将两者结合,我们可以将哈希表设计为:以入参 val 为键,数组下标 loc 为值。
用动态数组来获取随机元素,用哈希表来执行插入和删除
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 class RandomizedSet { List<Integer> nums; Map<Integer, Integer> valToIndex; public RandomizedSet () { nums = new ArrayList <>(); valToIndex = new HashMap <>(); } public boolean insert (int val) { if (valToIndex.containsKey(val)) { return false ; } valToIndex.put(val, nums.size()); nums.add(val); return true ; } public boolean remove (int val) { if (!valToIndex.containsKey(val)) { return false ; } int index = valToIndex.get(val); valToIndex.put(nums.get(nums.size() - 1 ), index); Collections.swap(nums, index, nums.size() - 1 ); nums.remove(nums.size() - 1 ); valToIndex.remove(val); return true ; } public int getRandom () { return nums.get((int )(Math.random() * nums.size())); } }
⑤字符串
编写一个函数,其作用是将输入的字符串反转过来。输入字符串以字符数组 s 的形式给出。
不要给另外的数组分配额外的空间,你必须原地修改输入数组 、使用 O(1) 的额外空间解决这一问题。
示例 1:
1 2 输入:s = ["h","e","l","l","o"] 输出:["o","l","l","e","h"]
示例 2:
1 2 输入:s = ["H","a","n","n","a","h"] 输出:["h","a","n","n","a","H"]
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 class Solution { public void reverseString (char [] s) { int left = 0 , right = s.length - 1 ; while (left < right){ char tmp = s[left]; s[left] = s[right]; s[right] = tmp; left++; right--; } } class Solution { public void reverseString (char [] s) { int n = s.length; for (int left = 0 , right = n - 1 ; left < right; ++left, --right) { char tmp = s[left]; s[left] = s[right]; s[right] = tmp; } } } class Solution { public void reverseString (char [] s) { int l = 0 ; int r = s.length - 1 ; while (l < r) { s[l] ^= s[r]; s[r] ^= s[l]; s[l] ^= s[r]; l++; r--; } } }
给定一个字符串 s 和一个整数 k,从字符串开头算起,每计数至 2k 个字符,就反转这 2k 字符中的前 k 个字符。
如果剩余字符少于 k 个,则将剩余字符全部反转。
如果剩余字符小于 2k 但大于或等于 k 个,则反转前 k 个字符,其余字符保持原样。
示例 1:
1 2 输入:s = "abcdefg", k = 2 输出:"bacdfeg"
示例 2:
1 2 输入:s = "abcd", k = 2 输出:"bacd"
题意:每隔2k个反转前k个,尾数不够k个时候全部反转
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 class Solution { public String reverseStr (String s, int k) { int n = s.length(); char [] arr = s.toCharArray(); for (int i = 0 ; i < n; i += 2 * k) { if (i + k <= n) { reverse(arr, i, i + k - 1 ); continue ; } reverse(arr, i, n - 1 ); } return new String (arr); } public void reverse (char [] arr, int left, int right) { while (left < right) { char temp = arr[left]; arr[left] = arr[right]; arr[right] = temp; left++; right--; } } } class Solution { public String reverseStr (String s, int k) { int n = s.length(); char [] arr = s.toCharArray(); for (int i = 0 ; i < n; i += 2 * k) { reverse(arr, i, Math.min(i + k, n) - 1 ); } return String.valueOf(arr); } public void reverse (char [] arr, int left, int right) { while (left < right) { char temp = arr[left]; arr[left] = arr[right]; arr[right] = temp; left++; right--; } } }
给你一个字符串 s ,仅反转字符串中的所有元音字母,并返回结果字符串。
元音字母包括 'a'、'e'、'i'、'o'、'u',且可能以大小写两种形式出现不止一次。
示例 1:
1 2 输入:s = "hello" 输出:"holle"
示例 2:
1 2 输入:s = "leetcode" 输出:"leotcede"
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 class Solution { public String reverseVowels (String s) { int l = 0 , r = s.length() - 1 ; char [] arr = s.toCharArray(); while (l < r) { while (!"aeiouAEIOU" .contains(String.valueOf(arr[l])) && l < r) l++; while (!"aeiouAEIOU" .contains(String.valueOf(arr[r])) && l < r) r--; if (l < r) { char temp = arr[l]; arr[l] = arr[r]; arr[r] = temp; l++; r--; } } return new String (arr); } }
给你两个字符串 word1 和 word2 。请你从 word1 开始,通过交替添加字母来合并字符串。如果一个字符串比另一个字符串长,就将多出来的字母追加到合并后字符串的末尾。
返回 合并后的字符串 。
示例 1:
1 2 3 4 5 6 输入:word1 = "abc", word2 = "pqr" 输出:"apbqcr" 解释:字符串合并情况如下所示: word1: a b c word2: p q r 合并后: a p b q c r
示例 2:
1 2 3 4 5 6 输入:word1 = "ab", word2 = "pqrs" 输出:"apbqrs" 解释:注意,word2 比 word1 长,"rs" 需要追加到合并后字符串的末尾。 word1: a b word2: p q r s 合并后: a p b q r s
示例 3:
1 2 3 4 5 6 输入:word1 = "abcd", word2 = "pq" 输出:"apbqcd" 解释:注意,word1 比 word2 长,"cd" 需要追加到合并后字符串的末尾。 word1: a b c d word2: p q 合并后: a p b q c d
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 class Solution { public String mergeAlternately (String word1, String word2) { StringBuilder sb = new StringBuilder (); int m = word1.length(), n = word2.length(); int i = 0 , j = 0 ; while (i < m && j < n){ sb.append(word1.charAt(i)); sb.append(word2.charAt(j)); i++; j++; } while (i < m){ sb.append(word1.charAt(i)); i++; } while (j < n){ sb.append(word2.charAt(j)); j++; } return sb.toString(); } } class Solution { public String mergeAlternately (String word1, String word2) { StringBuilder sb = new StringBuilder (); int m = word1.length(), n = word2.length(); int i = 0 , j = 0 ; while (i < m || j < n){ if (i < m){ sb.append(word1.charAt(i)); i++; } if (j < n){ sb.append(word2.charAt(j)); j++; } } return sb.toString(); } }
请实现一个函数,把字符串 s 中的每个空格替换成”%20”。
1 2 输入:s = "We are happy." 输出:"We%20are%20happy."
1 2 3 4 5 6 7 8 9 10 11 12 13 class Solution { public String replaceSpace (String s) { StringBuilder sb = new StringBuilder (); for (int i = 0 ; i < s.length(); i++){ if (s.charAt(i) == ' ' ){ sb.append("%20" ); } else { sb.append(s.charAt(i)); } } return sb.toString(); } }
151. 反转字符串中的单词
给你一个字符串 s ,请你反转字符串中 单词 的顺序。
单词 是由非空格字符组成的字符串。s 中使用至少一个空格将字符串中的 单词 分隔开。
返回 单词 顺序颠倒且 单词 之间用单个空格连接的结果字符串。
**注意:**输入字符串 s中可能会存在前导空格、尾随空格或者单词间的多个空格。返回的结果字符串中,单词间应当仅用单个空格分隔,且不包含任何额外的空格。
示例 1:
1 2 输入:s = "the sky is blue" 输出:"blue is sky the"
示例 2:
1 2 3 输入:s = " hello world " 输出:"world hello" 解释:反转后的字符串中不能存在前导空格和尾随空格。
示例 3:
1 2 3 输入:s = "a good example" 输出:"example good a" 解释:如果两个单词间有多余的空格,反转后的字符串需要将单词间的空格减少到仅有一个。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 class Solution { public String reverseWords (String s) { s = s.trim(); List<String> wordList = Arrays.asList(s.split("\\s+" )); Collections.reverse(wordList); return String.join(" " , wordList); } } class Solution { public String reverseWords (String s) { String[] strs = s.trim().split(" " ); StringBuilder res = new StringBuilder (); for (int i = strs.length - 1 ; i >= 0 ; i--) { if (strs[i].equals("" )) continue ; res.append(strs[i] + " " ); } return res.toString().trim(); } } class Solution { public String reverseWords (String s) { s = s.trim(); int j = s.length() - 1 , i = j; StringBuilder res = new StringBuilder (); while (i >= 0 ) { while (i >= 0 && s.charAt(i) != ' ' ) i--; res.append(s.substring(i + 1 , j + 1 ) + " " ); while (i >= 0 && s.charAt(i) == ' ' ) i--; j = i; } return res.toString().trim(); } }
字符串的左旋转操作是把字符串前面的若干个字符转移到字符串的尾部。请定义一个函数实现字符串左旋转操作的功能。比如,输入字符串”abcdefg”和数字2,该函数将返回左旋转两位得到的结果”cdefgab”。
示例 1:
1 2 输入 : s = "abcdefg", k = 2 输出 : "cdefgab"
示例 2:
1 2 输入 : s = "lrloseumgh", k = 6 输出 : "umghlrlose"
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 class Solution { public String reverseLeftWords (String s, int n) { StringBuilder sb = new StringBuilder (); for (int i = n; i < s.length(); i++){ sb.append(s.charAt(i)); } for (int i = 0 ; i < n; i++){ sb.append(s.charAt(i)); } return sb.toString(); } } class Solution { public String reverseLeftWords (String s, int n) { return s.substring(n, s.length()) + s.substring(0 , n); } }
给你两个字符串 haystack 和 needle ,请你在 haystack 字符串中找出 needle 字符串的第一个匹配项的下标(下标从 0 开始)。如果 needle 不是 haystack 的一部分,则返回 -1 。
示例 1:
1 2 3 4 输入:haystack = "sadbutsad", needle = "sad" 输出:0 解释:"sad" 在下标 0 和 6 处匹配。 第一个匹配项的下标是 0 ,所以返回 0 。
示例 2:
1 2 3 输入:haystack = "leetcode", needle = "leeto" 输出:-1 解释:"leeto" 没有在 "leetcode" 中出现,所以返回 -1 。
暴力破解
枚举原串 haystack 中的每个字符作为「发起点」,每次从原串的「发起点」和匹配串的「首位」开始尝试匹配:
匹配成功:返回本次匹配的原串「发起点」。
匹配失败:枚举原串的下一个「发起点」,重新尝试匹配。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 class Solution { public int strStr (String haystack, String needle) { int n = haystack.length(), m = needle.length(); for (int i = 0 ; i <= n - m; i++){ boolean flag = true ; for (int j = 0 ; j < m; j++){ if (haystack.charAt(i + j) != needle.charAt(j)){ flag = false ; break ; } } if (flag) return i; } return -1 ; } }
KMP算法
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 class Solution { public static int strStr (String haystack, String needle) { int n = haystack.length(), m = needle.length(); if (m == 0 ) return 0 ; int [] next = new int [m]; for (int i = 1 , j = 0 ; i < m; i++) { while (j > 0 && needle.charAt(i) != needle.charAt(j)) { j = next[j - 1 ]; } if (needle.charAt(i) == needle.charAt(j)) { j++; } next[i] = j; } for (int i = 0 , j = 0 ; i < n; i++) { while (j > 0 && haystack.charAt(i) != needle.charAt(j)) { j = next[j - 1 ]; } if (haystack.charAt(i) == needle.charAt(j)) { j++; } if (j == m) { return i - m + 1 ; } } return -1 ; } }
给定一个非空的字符串 s ,检查是否可以通过由它的一个子串重复多次构成。
示例 1:
1 2 3 输入 : s = "abab" 输出 : true 解释 : 可由子串 "ab" 重复两次构成。
示例 2:
示例 3:
1 2 3 输入 : s = "abcabcabcabc" 输出 : true 解释 : 可由子串 "abc" 重复四次构成。 (或子串 "abcabc" 重复两次构成。)
方法一:枚举
如果一个长度为 n 的字符串 s 可以由它的一个长度为 m 的子串 s′ 重复多次构成,那么:
n 一定是 m 的倍数;
s′ 一定是 s 的前缀;
对于任意的 i∈[m,n),有 s[i] = s[i − m]。
小优化:因为子串至少需要重复一次,所以 m 不会大于 n 的一半,所以只需在 [1,n/2]的范围内枚举 m 即可。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 class Solution { public boolean repeatedSubstringPattern (String s) { int n = s.length(); for (int m = 1 ; m <= n/2 ; m++){ if (n % m == 0 ){ boolean match = true ; for (int i = m; i < n; i++){ if (s.charAt(i) != s.charAt(i - m)) { match = false ; break ; } } if (match){ return true ; } } } return false ; } }
给定两个字符串形式的非负整数 num1 和num2 ,计算它们的和并同样以字符串形式返回。
你不能使用任何內建的用于处理大整数的库(比如 BigInteger), 也不能直接将输入的字符串转换为整数形式。
示例 1:
1 2 输入:num1 = "11", num2 = "123" 输出:"134"
示例 2:
1 2 输入:num1 = "456", num2 = "77" 输出:"533"
示例 3:
1 2 输入:num1 = "0", num2 = "0" 输出:"0"
算法流程:
设定
,
两指针分别指向
,
尾部,模拟人工加法;
计算进位: 计算 carry = tmp / 10,代表当前位相加是否产生进位;添加当前位: 计算 tmp = n1 + n2 + carry,并将当前位 tmp % 10 添加至 res 头部;索引溢出处理: 当指针 i或j 走过数字首部后,给 n1,n2 赋值为 0,相当于给 num1,num2 中长度较短的数字前面填 0,以便后续计算。当遍历完 num1,num2 后跳出循环,并根据 carry 值决定是否在头部添加进位 1,最终返回 res 即可。
复杂度分析:
时间复杂度 O(max(M,N))):其中 M,N 为num1 和 num2长度;
空间复杂度 O(1):指针与变量使用常数大小空间。
char 转 int :字符的ASCII码值减去0的ASCII码值 等于数值本身。 即num1.charAt(i) - '0'
进位操作:2. 两数相加 、本题解题思路参考:415. 字符串相加 -题解
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 class Solution { public String addStrings (String num1, String num2) { StringBuilder res = new StringBuilder ("" ); int i = num1.length() - 1 , j = num2.length() - 1 , carry = 0 ; while (i >= 0 || j >= 0 ){ int n1 = i >= 0 ? num1.charAt(i) - '0' : 0 ; int n2 = j >= 0 ? num2.charAt(j) - '0' : 0 ; int tmp = n1 + n2 + carry; carry = tmp / 10 ; res.append(tmp % 10 ); i--; j--; } if (carry == 1 ) res.append(1 ); return res.reverse().toString(); } }
给定两个以字符串形式表示的非负整数 num1 和 num2,返回 num1 和 num2 的乘积,它们的乘积也表示为字符串形式。
**注意:**不能使用任何内置的 BigInteger 库或直接将输入转换为整数。
示例 1:
1 2 输入 : num1 = "2", num2 = "3" 输出 : "6"
示例 2:
1 2 输入 : num1 = "123", num2 = "456" 输出 : "56088"
乘数 num1 位数为 m,被乘数 num2 位数为 n, num1 x num2 结果 res 最大总位数为 m+n
num1[i] x num2[j] 的结果为 tmp(位数为两位,”0x”, “xy” 的形式),其第一位位于 res[i+j],第二位位于 res[i+j+1]。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 class Solution { public String multiply (String num1, String num2) { if (num1.equals("0" ) || num2.equals("0" )) { return "0" ; } int m = num1.length(), n = num2.length(); int [] res = new int [m + n]; for (int i = m - 1 ; i >= 0 ; i--) { for (int j = n - 1 ; j >= 0 ; j--) { int n1 = num1.charAt(i) - '0' ; int n2 = num2.charAt(j) - '0' ; int p1 = i + j, p2 = i + j + 1 ; int sum = (res[p2] + n1 * n2); res[p2] = sum % 10 ; res[p1] += sum / 10 ; } } StringBuilder result = new StringBuilder (); for (int i = 0 ; i < res.length; i++) { if (i == 0 && res[i] == 0 ) continue ; result.append(res[i]); } return result.toString(); } }
num1[i] 和 num2[j] 的乘积对应的就是 res[i+j] 和 res[i+j+1] 这两个位置。
对于字符串 s 和 t,只有在 s = t + ... + t(t 自身连接 1 次或多次)时,我们才认定 “t 能除尽 s”。
给定两个字符串 str1 和 str2 。返回 最长字符串 x,要求满足 x 能除尽 str1 且 x 能除尽 str2 。
示例 1:
1 2 输入:str1 = "ABCABC", str2 = "ABC" 输出:"ABC"
示例 2:
1 2 输入:str1 = "ABABAB", str2 = "ABAB" 输出:"AB"
示例 3:
1 2 输入:str1 = "LEET", str2 = "CODE" 输出:""
辗转相除法, 又名欧几里得算法(Euclidean algorithm),目的是求出两个正整数的最大公约数。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 class Solution { public String gcdOfStrings (String str1, String str2) { if (!(str1 + str2).equals(str2 + str1)){ return "" ; } return str1.substring(0 , gcd(str1.length(), str2.length())); } public int gcd (int a, int b) { return b == 0 ? a : gcd(b, a % b); } } public int gcd (int a, int b) { int remainder = a % b; while (remainder != 0 ) { a = b; b = remainder; remainder = a % b; } return b; }
罗马数字包含以下七种字符: I, V, X, L,C,D 和 M。
1 2 3 4 5 6 7 8 字符 数值 I 1 V 5 X 10 L 50 C 100 D 500 M 1000
例如, 罗马数字 2 写做 II ,即为两个并列的 1 。12 写做 XII ,即为 X + II 。 27 写做 XXVII, 即为 XX + V + II 。
通常情况下,罗马数字中小的数字在大的数字的右边。但也存在特例,例如 4 不写做 IIII,而是 IV。数字 1 在数字 5 的左边,所表示的数等于大数 5 减小数 1 得到的数值 4 。同样地,数字 9 表示为 IX。这个特殊的规则只适用于以下六种情况:
I 可以放在 V (5) 和 X (10) 的左边,来表示 4 和 9。X 可以放在 L (50) 和 C (100) 的左边,来表示 40 和 90。C 可以放在 D (500) 和 M (1000) 的左边,来表示 400 和 900。
给定一个罗马数字,将其转换成整数。
示例 1:
示例 2:
示例 3:
示例 4:
1 2 3 输入 : s = "LVIII" 输出 : 58 解释 : L = 50, V= 5, III = 3.
示例 5:
1 2 3 输入 : s = "MCMXCIV" 输出 : 1994 解释 : M = 1000, CM = 900, XC = 90, IV = 4.
按照题目的描述,可以总结如下规则:
罗马数字由 I,V,X,L,C,D,M 构成;
当小值在大值的左边,则减小值,如 IV=5-1=4;
当小值在大值的右边,则加小值,如 VI=5+1=6;
因此,把一个小值放在大值的左边,就是做减法,否则为加法 。
在代码实现上,可以往后看多一位,对比当前位与后一位的大小关系,从而确定当前位是加还是减法。当没有下一位时,做加法即可。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 class Solution { public int romanToInt (String s) { int sum = 0 ; int preNum = getValue(s.charAt(0 )); for (int i = 1 ; i < s.length(); i++){ int curNum = getValue(s.charAt(i)); if (preNum < curNum){ sum -= preNum; } else { sum += preNum; } preNum = curNum; } sum += preNum; return sum; } private int getValue (char ch) { switch (ch) { case 'I' : return 1 ; case 'V' : return 5 ; case 'X' : return 10 ; case 'L' : return 50 ; case 'C' : return 100 ; case 'D' : return 500 ; case 'M' : return 1000 ; default : return 0 ; } } } class Solution { public int romanToInt (String s) { s = s.replace("IV" ,"a" ); s = s.replace("IX" ,"b" ); s = s.replace("XL" ,"c" ); s = s.replace("XC" ,"d" ); s = s.replace("CD" ,"e" ); s = s.replace("CM" ,"f" ); int sum = 0 ; for (int i = 0 ; i < s.length(); i++) { sum += getValue(s.charAt(i)); } return sum; } public int getValue (char c) { switch (c) { case 'I' : return 1 ; case 'V' : return 5 ; case 'X' : return 10 ; case 'L' : return 50 ; case 'C' : return 100 ; case 'D' : return 500 ; case 'M' : return 1000 ; case 'a' : return 4 ; case 'b' : return 9 ; case 'c' : return 40 ; case 'd' : return 90 ; case 'e' : return 400 ; case 'f' : return 900 ; } return 0 ; } }
罗马数字包含以下七种字符: I, V, X, L,C,D 和 M。
1 2 3 4 5 6 7 8 字符 数值 I 1 V 5 X 10 L 50 C 100 D 500 M 1000
例如, 罗马数字 2 写做 II ,即为两个并列的 1。12 写做 XII ,即为 X + II 。 27 写做 XXVII, 即为 XX + V + II 。
通常情况下,罗马数字中小的数字在大的数字的右边。但也存在特例,例如 4 不写做 IIII,而是 IV。数字 1 在数字 5 的左边,所表示的数等于大数 5 减小数 1 得到的数值 4 。同样地,数字 9 表示为 IX。这个特殊的规则只适用于以下六种情况:
I 可以放在 V (5) 和 X (10) 的左边,来表示 4 和 9。X 可以放在 L (50) 和 C (100) 的左边,来表示 40 和 90。C 可以放在 D (500) 和 M (1000) 的左边,来表示 400 和 900。
给你一个整数,将其转为罗马数字。
示例 1:
示例 2:
示例 3:
示例 4:
1 2 3 输入 : num = 58 输出 : "LVIII" 解释 : L = 50, V = 5, III = 3.
示例 5:
1 2 3 输入 : num = 1994 输出 : "MCMXCIV" 解释 : M = 1000, CM = 900, XC = 90, IV = 4.
贪心法则:我们每次尽量使用最大的数来表示。 比如对于 1994 这个数,如果我们每次尽量用最大的数来表示,依次选 1000,900,90,4,会得到正确结果 MCMXCIV。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 class Solution { public String intToRoman (int num) { int [] nums = {1000 , 900 , 500 , 400 , 100 , 90 , 50 , 40 , 10 , 9 , 5 , 4 , 1 }; String[] romans = {"M" , "CM" ,"D" ,"CD" ,"C" ,"XC" ,"L" ,"XL" ,"X" ,"IX" ,"V" ,"IV" ,"I" }; StringBuilder res = new StringBuilder (); for (int i = 0 ; i < nums.length; i++){ while (num >= nums[i]){ num -= nums[i]; res.append(romans[i]); } } return res.toString(); } }
给你一个字符串 s,由若干单词组成,单词前后用一些空格字符隔开。返回字符串中 最后一个 单词的长度。
单词 是指仅由字母组成、不包含任何空格字符的最大子字符串。
示例 1:
1 2 3 输入:s = "Hello World" 输出:5 解释:最后一个单词是“World”,长度为5 。
示例 2:
1 2 3 输入:s = " fly me to the moon " 输出:4 解释:最后一个单词是“moon”,长度为4 。
示例 3:
1 2 3 输入:s = "luffy is still joyboy" 输出:6 解释:最后一个单词是长度为6 的“joyboy”。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 class Solution { public int lengthOfLastWord (String s) { String[] arr = s.split("\\s+" ); String str = arr[arr.length - 1 ]; return str.length(); } } class Solution { public int lengthOfLastWord (String s) { int end = s.length() - 1 ; while (end >= 0 && s.charAt(end) == ' ' ) end--; if (end < 0 ) return 0 ; int start = end; while (start >= 0 && s.charAt(start) != ' ' ) start--; return end - start; } }
编写一个函数来查找字符串数组中的最长公共前缀。
如果不存在公共前缀,返回空字符串 ""。
示例 1:
1 2 输入:strs = ["flower","flow","flight"] 输出:"fl"
示例 2:
1 2 3 输入:strs = ["dog","racecar","car"] 输出:"" 解释:输入不存在公共前缀。
把字符串列表看成一个二维数组,然后用一个嵌套 for 循环计算这个二维数组前面有多少列的元素完全相同即可。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 class Solution { public String longestCommonPrefix (String[] strs) { int m = strs.length; int n = strs[0 ].length(); for (int col = 0 ; col < n; col++){ for (int row = 1 ; row < m; row++){ String thisStr = strs[row]; String prevStr = strs[row - 1 ]; if (col >= thisStr.length() || col >= prevStr.length() || thisStr.charAt(col) != prevStr.charAt(col)) { return strs[row].substring(0 , col); } } } return strs[0 ]; } }
将一个给定字符串 s 根据给定的行数 numRows ,以从上往下、从左到右进行 Z 字形排列。
比如输入字符串为 "PAYPALISHIRING" 行数为 3 时,排列如下:
1 2 3 P A H N A P L S I I G Y I R
之后,你的输出需要从左往右逐行读取,产生出一个新的字符串,比如:"PAHNAPLSIIGYIR"。
请你实现这个将字符串进行指定行数变换的函数:
1 string convert(string s, int numRows);
示例 1:
1 2 输入:s = "PAYPALISHIRING", numRows = 3 输出:"PAHNAPLSIIGYIR"
示例 2:
1 2 3 4 5 6 7 输入:s = "PAYPALISHIRING", numRows = 4 输出:"PINALSIGYAHRPI" 解释: P I N A L S I G Y A H R P I
示例 3:
1 2 输入:s = "A", numRows = 1 输出:"A"
题目理解:
字符串 s 是以 Z 字形为顺序存储的字符串,目标是按行打印。
设 numRows 行字符串分别为 rowStr[1] , rowStr[2] ,…, rowStr[n],则容易发现:按顺序遍历字符串 s 时,每个字符 c 在 Z 字形中对应的 行索引 先从 rowStr[1] 增大至 rowStr[n],再从 rowStr[n] 减小至 rowStr[1] …… 如此反复。
因此,解决方案为:模拟这个行索引的变化,在遍历 s 中把每个字符填到正确的行 rowStr[i] 。
算法流程: 按顺序遍历字符串 s;
res[i] += c:c 填入对应行 rowStr;i += flag:c 对应的行索引;flag = - flag:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 class Solution { public String convert (String s, int numRows) { if (numRows < 2 ) return s; List<StringBuilder> rowStr = new ArrayList <>(); for (int i = 0 ; i < numRows; i++){ rowStr.add(new StringBuilder ()); } int row = 0 , flag = -1 ; for (char c : s.toCharArray()) { rowStr.get(row).append(c); if (row == 0 || row == numRows - 1 ){ flag = -flag; } row += flag; } StringBuilder res = new StringBuilder (); for (StringBuilder str: rowStr) { res.append(str); } return res.toString(); } }
⑥双指针
编写一个函数,其作用是将输入的字符串反转过来。输入字符串以字符数组 s 的形式给出。
不要给另外的数组分配额外的空间,你必须原地修改输入数组 、使用 O(1) 的额外空间解决这一问题。
示例 1:
1 2 输入:s = ["h","e","l","l","o"] 输出:["o","l","l","e","h"]
示例 2:
1 2 输入:s = ["H","a","n","n","a","h"] 输出:["h","a","n","n","a","H"]
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 class Solution { public void reverseString (char [] s) { int left = 0 , right = s.length - 1 ; while (left < right){ char tmp = s[left]; s[left] = s[right]; s[right] = tmp; left++; right--; } } class Solution { public void reverseString (char [] s) { int n = s.length; for (int left = 0 , right = n - 1 ; left < right; ++left, --right) { char tmp = s[left]; s[left] = s[right]; s[right] = tmp; } } } class Solution { public void reverseString (char [] s) { int l = 0 ; int r = s.length - 1 ; while (l < r) { s[l] ^= s[r]; s[r] ^= s[l]; s[l] ^= s[r]; l++; r--; } } }
给你一个数组 nums 和一个值 val,你需要原地移除所有数值等于 val 的元素,并返回移除后数组的新长度。
不要使用额外的数组空间,你必须仅使用 O(1) 额外空间并原地修改输入数组。
元素的顺序可以改变。你不需要考虑数组中超出新长度后面的元素。
示例 1:
1 2 3 输入:nums = [3,2,2,3], val = 3 输出:2, nums = [2,2] 解释:函数应该返回新的长度 2, 并且 nums 中的前两个元素均为 2。你不需要考虑数组中超出新长度后面的元素。例如,函数返回的新长度为 2 ,而 nums = [2,2,3,3] 或 nums = [2,2,0,0],也会被视作正确答案。
示例 2:
1 2 3 输入:nums = [0,1,2,2,3,0,4,2], val = 2 输出:5, nums = [0,1,4,0,3] 解释:函数应该返回新的长度 5, 并且 nums 中的前五个元素为 0, 1, 3, 0, 4。注意这五个元素可为任意顺序。你不需要考虑数组中超出新长度后面的元素。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 class Solution { public int removeElement (int [] nums, int val) { int slow = 0 ; for (int fast = 0 ; fast < nums.length; fast++){ if (nums[fast] != val){ nums[slow] = nums[fast]; slow++; } } return slow; } } class Solution { public int removeElement (int [] nums, int val) { int idx = 0 ; for (int x : nums) { if (x != val) nums[idx++] = x; } return idx; } }
给定一个数组 nums,编写一个函数将所有 0 移动到数组的末尾,同时保持非零元素的相对顺序。
请注意 ,必须在不复制数组的情况下原地对数组进行操作。
示例 1:
1 2 输入 : nums = [0,1,0,3,12] 输出 : [1,3,12,0,0]
示例 2:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 class Solution { public void moveZeroes (int [] nums) { int p = removeElement(nums, 0 ); for (; p < nums.length; p++) { nums[p] = 0 ; } } int removeElement (int [] nums, int val) { int fast = 0 , slow = 0 ; while (fast < nums.length) { if (nums[fast] != val) { nums[slow] = nums[fast]; slow++; } fast++; } return slow; } }
快排思想,用 0 当做这个中间点,把不等于 0的放到中间点的左边,等于 0 的放到其右边。使用两个指针 i 和 j,只要 nums[i]!=0,我们就交换 nums[i] 和 nums[j]
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 class Solution { public void moveZeroes (int [] nums) { if (nums == null ) return ; int j = 0 ; for (int i = 0 ; i < nums.length; i++) { if (nums[i] != 0 ) { int tmp = nums[i]; nums[i] = nums[j]; nums[j++] = tmp; } } } }
请实现一个函数,把字符串 s 中的每个空格替换成”%20”。
1 2 输入:s = "We are happy." 输出:"We%20are%20happy."
1 2 3 4 5 6 7 8 9 10 11 12 13 class Solution { public String replaceSpace (String s) { StringBuilder sb = new StringBuilder (); for (int i = 0 ; i < s.length(); i++){ if (s.charAt(i) == ' ' ){ sb.append("%20" ); } else { sb.append(s.charAt(i)); } } return sb.toString(); } }
给你一个字符串 s ,请你反转字符串中 单词 的顺序。
单词 是由非空格字符组成的字符串。s 中使用至少一个空格将字符串中的 单词 分隔开。
返回 单词 顺序颠倒且 单词 之间用单个空格连接的结果字符串。
**注意:**输入字符串 s中可能会存在前导空格、尾随空格或者单词间的多个空格。返回的结果字符串中,单词间应当仅用单个空格分隔,且不包含任何额外的空格。
示例 1:
1 2 输入:s = "the sky is blue" 输出:"blue is sky the"
示例 2:
1 2 3 输入:s = " hello world " 输出:"world hello" 解释:反转后的字符串中不能存在前导空格和尾随空格。
示例 3:
1 2 3 输入:s = "a good example" 输出:"example good a" 解释:如果两个单词间有多余的空格,反转后的字符串需要将单词间的空格减少到仅有一个。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 class Solution { public String reverseWords (String s) { s = s.trim(); List<String> wordList = Arrays.asList(s.split("\\s+" )); Collections.reverse(wordList); return String.join(" " , wordList); } } class Solution { public String reverseWords (String s) { String[] strs = s.trim().split(" " ); StringBuilder res = new StringBuilder (); for (int i = strs.length - 1 ; i >= 0 ; i--) { if (strs[i].equals("" )) continue ; res.append(strs[i] + " " ); } return res.toString().trim(); } } class Solution { public String reverseWords (String s) { s = s.trim(); int j = s.length() - 1 , i = j; StringBuilder res = new StringBuilder (); while (i >= 0 ) { while (i >= 0 && s.charAt(i) != ' ' ) i--; res.append(s.substring(i + 1 , j + 1 ) + " " ); while (i >= 0 && s.charAt(i) == ' ' ) i--; j = i; } return res.toString().trim(); } }
给你单链表的头节点 head ,请你反转链表,并返回反转后的链表。
示例 1:
1 2 输入:head = [1,2,3,4,5] 输出:[5,4,3,2,1]
示例 2:
示例 3:
**进阶:**链表可以选用迭代或递归方式完成反转。你能否用两种方法解决这道题?
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 class Solution { public ListNode reverseList (ListNode head) { ListNode pre = null ; ListNode cur = head; ListNode tmp = null ; while (cur != null ){ tmp = cur.next; cur.next = pre; pre = cur; cur = tmp; } return pre; } } class Solution { public ListNode reverseList (ListNode head) { return reverse(null ,head); } public ListNode reverse (ListNode pre, ListNode cur) { if (cur == null ) { return pre; } ListNode tmp = null ; tmp = cur.next; cur.next = pre; return reverse(cur,tmp); } } class Solution { public ListNode reverseList (ListNode head) { Deque<ListNode> stack = new ArrayDeque <>(); while (head != null ){ stack.push(head); head = head.next; } ListNode dummy = new ListNode (0 ); ListNode temp = dummy; while (!stack.isEmpty()){ temp.next = stack.pop(); temp = temp.next; } temp.next = null ; return dummy.next; } } class Solution { public ListNode reverseList (ListNode head) { Deque<ListNode> stack = new ArrayDeque <>(); while (head != null ){ stack.add(head); head = head.next; } ListNode dummy = new ListNode (0 ), ListNode temp = dummy; while (stack.size() != 0 ){ temp.next = new ListNode (stack.pop()); temp = temp.next; } return dummy.next; } }
给你一个 升序排列 的数组 nums ,请你 原地 删除重复出现的元素,使每个元素 只出现一次 ,返回删除后数组的新长度。元素的 相对顺序 应该保持 一致 。
由于在某些语言中不能改变数组的长度,所以必须将结果放在数组nums的第一部分。更规范地说,如果在删除重复项之后有 k 个元素,那么 nums 的前 k 个元素应该保存最终结果。
将最终结果插入 nums 的前 k 个位置后返回 k 。
不要使用额外的空间,你必须在 原地 并在使用 O(1) 额外空间的条件下完成。
示例 1:
1 2 3 输入:nums = [1,1,2] 输出:2, nums = [1,2] 解释:函数应该返回新的长度 2 ,并且原数组 nums 的前两个元素被修改为 1, 2 。不需要考虑数组中超出新长度后面的元素。
示例 2:
1 2 3 输入:nums = [0,0,1,1,1,2,2,3,3,4] 输出:5, nums = [0,1,2,3,4] 解释:函数应该返回新的长度 5 , 并且原数组 nums 的前五个元素被修改为 0, 1, 2, 3, 4 。不需要考虑数组中超出新长度后面的元素。
快慢指针
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 class Solution { public int removeDuplicates (int [] nums) { int slow = 0 ; for (int fast = 0 ; fast < nums.length; fast++){ if (nums[fast] != nums[slow]){ slow++; nums[slow] = nums[fast]; } } return slow + 1 ; } } class Solution { public int removeDuplicates (int [] nums) { if (nums.length == 0 ) { return 0 ; } int slow = 0 , fast = 0 ; while (fast < nums.length) { if (nums[fast] != nums[slow]) { slow++; nums[slow] = nums[fast]; } fast++; } return slow + 1 ; } }
通用解法
举个🌰,我们令 k=1,假设有样例:[3,3,3,3,4,4,4,5,5,5]
设定变量 idx,指向待插入位置。idx 初始值为 0,目标数组为 []
首先我们先让第 1 位直接保留(性质 1)。idx 变为 1,目标数组为 [3]
继续往后遍历,能够保留的前提是与 idx 的前面 1 位元素不同(性质 2),因此我们会跳过剩余的 3,将第一个 4 追加进去。idx 变为 2,目标数组为 [3,4]
继续这个过程,跳过剩余的 4,将第一个 5 追加进去。idx 变为 3,目标数组为 [3,4,5]
当整个数组被扫描完,最终我们得到了目标数组 [3,4,5] 和 答案 idx 为 3。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 class Solution { public int removeDuplicates (int [] nums) { return process(nums, 1 ); } int process (int [] nums, int k) { int idx = 0 ; for (int x : nums) { if (idx < k || nums[idx - k] != x) nums[idx++] = x; } return idx; } }
给你一个有序数组 nums ,请你** 原地 ** 删除重复出现的元素,使得出现次数超过两次的元素只出现两次 ,返回删除后数组的新长度。
不要使用额外的数组空间,你必须在 原地 修改输入数组
示例 1:
1 2 3 输入:nums = [1,1,1,2,2,3] 输出:5, nums = [1,1,2,2,3] 解释:函数应返回新长度 length = 5, 并且原数组的前五个元素被修改为 1, 1, 2, 2, 3 。 不需要考虑数组中超出新长度后面的元素。
示例 2:
1 2 3 输入:nums = [0,0,1,1,1,1,2,3,3] 输出:7, nums = [0,0,1,1,2,3,3] 解释:函数应返回新长度 length = 7, 并且原数组的前五个元素被修改为 0, 0, 1, 1, 2, 3, 3 。 不需要考虑数组中超出新长度后面的元素。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 class Solution { public int removeDuplicates (int [] nums) { int n = nums.length; if (n <= 2 ) { return n; } int slow = 2 , fast = 2 ; while (fast < n) { if (nums[slow - 2 ] != nums[fast]) { nums[slow] = nums[fast]; slow++; } fast++; } return slow; } } class Solution { public int removeDuplicates (int [] nums) { return process(nums, 2 ); } int process (int [] nums, int k) { int idx = 0 ; for (int x : nums) { if (idx < k || nums[idx - k] != x) nums[idx++] = x; } return idx; } }
输入两个链表,找出它们的第一个公共节点。
如下面的两个链表:
在节点 c1 开始相交。
示例 1:
1 2 3 输入:intersectVal = 8 , listA = [4,1,8,4 ,5 ], listB = [5,0,1,8 ,4 ,5 ], skipA = 2 , skipB = 3 输出:Reference of the node with value = 8 输入解释:相交节点的值为 8 (注意,如果两个列表相交则不能为 0 )。从各自的表头开始算起,链表 A 为 [4,1,8,4 ,5 ],链表 B 为 [5,0,1,8 ,4 ,5 ]。在 A 中,相交节点前有 2 个节点;在 B 中,相交节点前有 3 个节点。
示例 2:
1 2 3 输入:intersectVal = 2 , listA = [0 ,9 ,1 ,2 ,4 ], listB = [3 ,2 ,4 ], skipA = 3 , skipB = 1 输出:Reference of the node with value = 2 输入解释:相交节点的值为 2 (注意,如果两个列表相交则不能为 0 )。从各自的表头开始算起,链表 A 为 [0 ,9 ,1 ,2 ,4 ],链表 B 为 [3 ,2 ,4 ]。在 A 中,相交节点前有 3 个节点;在 B 中,相交节点前有 1 个节点。
示例 3:
1 2 3 4 输入:int ersectVal = 0 , listA = [2 ,6 ,4 ], listB = [1 ,5 ], skipA = 3 , skipB = 2 输出:null 输入解释:从各自的表头开始算起,链表 A 为 [2 ,6 ,4 ],链表 B 为 [1 ,5 ]。由于这两个链表不相交,所以 int ersectVal 必须为 0 ,而 skipA 和 skipB 可以是任意值。 解释:这两个链表不相交,因此返回 null 。
1 2 3 4 5 6 7 8 9 10 11 12 13 public class Solution { public ListNode getIntersectionNode (ListNode headA, ListNode headB) { ListNode A = headA; ListNode B = headB; while (A != B){ if (A != null ) A = A.next; else A = headB; if (B != null ) B = B.next; else B = headA; } return A; } }
给定一个链表的头节点 head ,返回链表开始入环的第一个节点。 如果链表无环,则返回 null。
如果链表中有某个节点,可以通过连续跟踪 next 指针再次到达,则链表中存在环。 为了表示给定链表中的环,评测系统内部使用整数 pos 来表示链表尾连接到链表中的位置(索引从 0 开始 )。如果 pos 是 -1,则在该链表中没有环。注意:pos 不作为参数进行传递 ,仅仅是为了标识链表的实际情况。
不允许修改 链表。
示例 1:
1 2 3 输入:head = [3,2,0,-4], pos = 1 输出:返回索引为 1 的链表节点 解释:链表中有一个环,其尾部连接到第二个节点。
示例 2:
1 2 3 输入:head = [1,2], pos = 0 输出:返回索引为 0 的链表节点 解释:链表中有一个环,其尾部连接到第一个节点。
示例 3:
1 2 3 输入:head = [1 ], pos = -1 输出:返回 null 解释:链表中没有环。
**进阶:**你是否可以使用 O(1) 空间解决此题?
方法一:哈希表
遍历链表中的每个节点,并将它记录下来;一旦遇到了此前遍历过的节点,就可以判定链表中存在环。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 public class Solution { public ListNode detectCycle (ListNode head) { Set<ListNode> set = new HashSet <>(); ListNode temp = head; while (temp != null ){ if (set.contains(temp)){ return temp; } set.add(temp); temp = temp.next; } return null ; } }
时间复杂度:O(N),其中 N 为链表中节点的数目。我们恰好需要访问链表中的每一个节点。
空间复杂度:O(N),其中 N 为链表中节点的数目。我们需要将链表中的每个节点都保存在哈希表当中。
方法二:快慢指针
双指针第一次相遇: 设两指针 fast,slow 指向链表头部 head,fast 每轮走 2 步,slow 每轮走 1 步;
第一种结果: fast 指针走过链表末端,说明链表无环,直接返回 null;第二种结果: 当fast == slow时, 两指针在环中 第一次相遇 。
双指针第二次相遇:
slow指针 位置不变 ,将fast指针重新 指向链表头部节点 ;slow和fast同时每轮向前走 1 步;当 fast 指针走到链表环入口,两指针重合 。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 public class Solution { public ListNode detectCycle (ListNode head) { ListNode fast = head, slow = head; while (true ){ if (fast == null || fast.next == null ) return null ; fast = fast.next.next; slow = slow.next; if (fast == slow) break ; } fast = head; while (fast != slow){ fast = fast.next; slow = slow.next; } return fast; } }
给你一个整数数组 nums ,判断是否存在三元组 [nums[i], nums[j], nums[k]] 满足 i != j、i != k 且 j != k ,同时还满足 nums[i] + nums[j] + nums[k] == 0 。请你返回所有和为 0 且不重复的三元组。
**注意:**答案中不可以包含重复的三元组。
示例 1:
1 2 3 4 5 6 7 8 输入:nums = [-1,0,1,2,-1,-4] 输出:[[-1,-1,2],[-1,0,1]] 解释: nums[0] + nums[1] + nums[2] = (-1) + 0 + 1 = 0 。 nums[1] + nums[2] + nums[4] = 0 + 1 + (-1) = 0 。 nums[0] + nums[3] + nums[4] = (-1) + 2 + (-1) = 0 。 不同的三元组是 [-1,0,1] 和 [-1,-1,2] 。 注意,输出的顺序和三元组的顺序并不重要。
示例 2:
1 2 3 输入:nums = [0,1,1] 输出:[] 解释:唯一可能的三元组和不为 0 。
示例 3:
1 2 3 输入:nums = [0,0,0] 输出:[[0,0,0]] 解释:唯一可能的三元组和为 0 。
特判,对于数组长度 n,如果数组为 null 或者数组长度小于 3,返回 []。
对数组进行排序。
遍历排序后数组:
如果第一个数 nums[i] 就大于 0,则三数之和必然无法等于 0,结束循环
如果 nums[i] == nums[i−1],当起始的值等于前一个元素,那么得到的结果将会和前一次重复,所以应该跳过
再使用左右指针指向 nums[i]后面的两端,数字分别为 nums[L] 和 nums[R],当 L < R时,执行循环,计算三个数的和 sum 判断是否满足为 0,满足则添加进结果集
若和大于 0,说明 nums[R]太大,R 左移
若和小于 0,说明 nums[L]太小,L 右移
若和等于0,添加进结果集,并执行循环,判断左界和右界是否和下一位置重复,去除重复解。并同时将 L,R移到下一位置,寻找新的解
即当 sum == 0 时,nums[L] == nums[L+1] 则会导致结果重复,应该跳过,L++
即当 sum == 0 时,nums[R] == nums[R−1] 则会导致结果重复,应该跳过,R−−
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 class Solution { public static List<List<Integer>> threeSum (int [] nums) { List<List<Integer>> ans = new ArrayList (); int len = nums.length; if (nums == null || len < 3 ) return ans; Arrays.sort(nums); for (int i = 0 ; i < len ; i++) { if (nums[i] > 0 ) break ; if (i > 0 && nums[i] == nums[i - 1 ]) continue ; int L = i + 1 ; int R = len - 1 ; while (L < R){ int sum = nums[i] + nums[L] + nums[R]; if (sum < 0 ) L++; else if (sum > 0 ) R--; else if (sum == 0 ){ ans.add(Arrays.asList(nums[i],nums[L],nums[R])); while (L < R && nums[L] == nums[L + 1 ]) L++; while (L < R && nums[R] == nums[R - 1 ]) R--; L++; R--; } } } return ans; } }
给你一个由 n 个整数组成的数组 nums ,和一个目标值 target 。请你找出并返回满足下述全部条件且不重复 的四元组 [nums[a], nums[b], nums[c], nums[d]] (若两个四元组元素一一对应,则认为两个四元组重复):
0 <= a, b, c, d < na、b、c 和 d 互不相同 nums[a] + nums[b] + nums[c] + nums[d] == target
你可以按 任意顺序 返回答案 。
示例 1:
1 2 输入:nums = [1,0,-1,0,-2,2], target = 0 输出:[[-2,-1,1,2],[-2,0,0,2],[-1,0,0,1]]
示例 2:
1 2 输入:nums = [2,2,2,2,2], target = 8 输出:[[2,2,2,2]]
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 class Solution { public List<List<Integer>> fourSum (int [] nums, int target) { List<List<Integer>> res = new ArrayList <>(); Arrays.sort(nums); for (int i = 0 ; i < nums.length; i++){ if (nums[i] > 0 && nums[i] > target) break ; if (i > 0 && nums[i] == nums[i - 1 ]) continue ; for (int j = i + 1 ; j < nums.length; j++){ if (j > i + 1 && nums[j - 1 ] == nums[j]) continue ; int L = j + 1 , R = nums.length - 1 ; while (L < R) { int sum = nums[i] + nums[j] + nums[L] + nums[R]; if (sum > target) R--; else if (sum < target) L++; else { res.add(Arrays.asList(nums[i],nums[j],nums[L],nums[R])); while (L < R && nums[L] == nums[L + 1 ]) L++; while (L < R && nums[R] == nums[R - 1 ]) R--; L++; R--; } } } } return res; } }
给定字符串 s 和 t ,判断 s 是否为 t 的子序列。
字符串的一个子序列是原始字符串删除一些(也可以不删除)字符而不改变剩余字符相对位置形成的新字符串。(例如,"ace"是"abcde"的一个子序列,而"aec"不是)。
进阶:
如果有大量输入的 S,称作 S1, S2, … , Sk 其中 k >= 10亿,你需要依次检查它们是否为 T 的子序列。在这种情况下,你会怎样改变代码?
示例 1:
1 2 输入:s = "abc", t = "ahbgdc" 输出:true
示例 2:
1 2 输入:s = "axc", t = "ahbgdc" 输出:false
基础-双指针
1 2 3 4 5 6 7 8 9 10 11 12 class Solution { public boolean isSubsequence (String s, String t) { int i = 0 , j = 0 ; while (i < s.length() && j < t.length()){ if (s.charAt(i) == t.charAt(j)){ i++; } j++; } return i == s.length(); } }
进阶-二分查找
对 t 进行预处理,用一个字典 index 将每个字符出现的索引位置按顺序存储下来
比如对于这个情况,匹配了 “ab”,应该匹配 “c” 了,按照之前的解法,我们需要 j 线性前进扫描字符 “c”,但借助 index 中记录的信息,可以二分搜索 index[c] 中比 j 大的那个索引 ,在下图的例子中,就是在 [0,2,6] 中搜索比 4 大的那个索引
这样就可以直接得到下一个 “c” 的索引。现在的问题就是,如何用二分查找计算那个恰好比 4 大的索引呢?答案是,寻找左侧边界的二分搜索就可以做到。
对于搜索左侧边界 的二分查找,有一个特殊性质:当 val 不存在时,得到的索引恰好是比 val 大的最小元素索引 。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 class Solution { public boolean isSubsequence (String s, String t) { int m = s.length(), n = t.length(); ArrayList<Integer>[] index = new ArrayList [128 ]; for (int i = 0 ; i < n; i++){ char c = t.charAt(i); if (index[c] == null ){ index[c] = new ArrayList <>(); } index[c].add(i); } int j = 0 ; for (int i = 0 ; i < m; i++) { char c = s.charAt(i); if (index[c] == null ) return false ; int pos = left_bound(index[c], j); if (pos == -1 ) return false ; j = index[c].get(pos) + 1 ; } return true ; } public int left_bound (ArrayList<Integer> arr, int target) { int left = 0 , right = arr.size(); while (left < right) { int mid = left + (right - left) / 2 ; if (target > arr.get(mid)) { left = mid + 1 ; } else { right = mid; } } if (left == arr.size()) { return -1 ; } return left; } }
给定一个长度为 n 的整数数组 height 。有 n 条垂线,第 i 条线的两个端点是 (i, 0) 和 (i, height[i]) 。
找出其中的两条线,使得它们与 x 轴共同构成的容器可以容纳最多的水。
返回容器可以储存的最大水量。**说明:**你不能倾斜容器。
示例 1:
1 2 3 输入:[1,8,6,2,5,4,8,3,7] 输出:49 解释:图中垂直线代表输入数组 [1,8,6,2,5,4,8,3,7]。在此情况下,容器能够容纳水(表示为蓝色部分)的最大值为 49。
示例 2:
暴力法
计算每两个柱子所围成的面积,把所有的都计算一遍,然后保留最大值即可。
1 2 3 4 5 6 7 8 9 10 11 12 13 class Solution { public int maxArea (int [] height) { int n = height.length; int res = 0 ; for (int i = 0 ; i < n - 1 ; i++) { for (int j = i + 1 ; j < n; j++) { int area = Math.min(height[i], height[j]) * (j - i); res = Math.max(res, area); } } return res; } }
双指针
用 left 和 right 两个指针从两端向中心收缩,一边收缩一边计算 [left, right] 之间的矩形面积,取最大的面积值即是答案
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 class Solution { public int maxArea (int [] height) { int left = 0 , right = height.length - 1 ; int res = 0 ; while (left < right) { int area = Math.min(height[left], height[right]) * (right - left); res = Math.max(res, area); if (height[left] < height[right]) { left++; } else { right--; } } return res; } }
给你一个整数数组 nums 和一个整数 k 。
每一步操作中,你需要从数组中选出和为 k 的两个整数,并将它们移出数组。
返回你可以对数组执行的最大操作数。
示例 1:
1 2 3 4 5 6 输入:nums = [1,2,3,4], k = 5 输出:2 解释:开始时 nums = [1,2,3,4]: - 移出 1 和 4 ,之后 nums = [2,3] - 移出 2 和 3 ,之后 nums = [] 不再有和为 5 的数对,因此最多执行 2 次操作。
示例 2:
1 2 3 4 5 输入:nums = [3,1,3,4,3], k = 6 输出:1 解释:开始时 nums = [3,1,3,4,3]: - 移出前两个 3 ,之后nums = [1,4,3] 不再有和为 6 的数对,因此最多执行 1 次操作。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 class Solution { public int maxOperations (int [] nums, int k) { Arrays.sort(nums); int left = 0 , right = nums.length - 1 ; int res = 0 ; while (left < right){ if (nums[left] + nums[right] == k){ res++; left++; right--; } else if (nums[left] + nums[right] < k){ left++; } else { right--; } } return res; } }
⑦二叉树
二叉树基础知识请参考:数据结构-树 | 简言之 (jwt1399.top)
1 2 3 4 5 6 7 8 9 10 11 12 13 public class TreeNode { int val; TreeNode left; TreeNode right; TreeNode() {} TreeNode(int val) { this .val = val; } TreeNode(int val, TreeNode left, TreeNode right) { this .val = val; this .left = left; this .right = right; } }
我们有一棵二叉树:
栈是一种 先进后出的结构,那么入栈顺序必须调整为倒序
前序遍历,出栈顺序:根左右; 入栈顺序:右左根
中序遍历,出栈顺序:左根右; 入栈顺序:右根左
后序遍历,出栈顺序:左右根; 入栈顺序:根右左
❶二叉树遍历
先输出父节点 ,再遍历左子树和右子树
1.递归
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 class Solution { public List<Integer> preorderTraversal (TreeNode root) { List<Integer> res = new ArrayList <>(); dfs(root, res); return res; } public void dfs (TreeNode root, List<Integer> res) { if (root == null ){ return ; } res.add(root.val); dfs(root.left, res); dfs(root.right, res); } }
2.迭代
弹栈顶入列表
如有右,先 入右
如有左,再 入左
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 class Solution { public List<Integer> preorderTraversal (TreeNode root) { List<Integer> res = new ArrayList <>(); if (root == null ) { return res; } Deque<TreeNode> stack = new LinkedList <>(); stack.push(root); while (!stack.isEmpty()){ TreeNode tmp = stack.pop(); res.add(tmp.val); if (tmp.right != null ){ stack.push(tmp.right); } if (tmp.left != null ){ stack.push(tmp.left); } } return res; } }
先遍历左子树,再输出父节点 ,再遍历右子树
1.递归
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 class Solution { public List<Integer> inorderTraversal (TreeNode root) { List<Integer> res = new ArrayList <>(); dfs(root, res); return res; } public void dfs (TreeNode root, List<Integer> res) { if (root == null ){ return ; } dfs(root.left, res); res.add(root.val); dfs(root.right, res); } }
2.迭代
根结点不为空,入栈并向左走。整条界依次入栈
根结点为空,弹栈顶打印,向右走。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 class Solution { public List<Integer> inorderTraversal (TreeNode root) { List<Integer> res = new ArrayList <Integer>(); Deque<TreeNode> stack = new LinkedList <>(); while (root != null || !stack.isEmpty()) { while (root != null ) { stack.push(root); root = root.left; } TreeNode tmp = stack.pop(); res.add(tmp.val); root = tmp.right; } return res; } } class Solution { public List<Integer> inorderTraversal (TreeNode root) { List<Integer> res = new ArrayList <Integer>(); Deque<TreeNode> stack = new LinkedList <>(); while (root != null || !stack.isEmpty()) { if (root != null ) { stack.push(root); root = root.left; } else { TreeNode tmp = stack.pop(); res.add(tmp.val); root = tmp.right; } } return res; } }
先遍历左子树,再遍历右子树,最后输出父节点
1.递归
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 class Solution { public List<Integer> postorderTraversal (TreeNode root) { List<Integer> res = new ArrayList <>(); dfs(root, res); return res; } public void dfs (TreeNode root ,List<Integer> res) { if (root == null ){ return ; } dfs(root.left, res); dfs(root.right, res); res.add(root.val); } }
2.迭代
弹栈顶输出
如有左,压入左
如有右,压入右
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 class Solution { public List<Integer> postorderTraversal (TreeNode root) { List<Integer> res = new ArrayList <>(); if (root == null ) { return res; } Deque<TreeNode> stack = new LinkedList <>(); TreeNode prev = null ; while (!stack.isEmpty() || root != null ) { while (root != null ) { stack.push(root); root = root.left; } root = stack.pop(); if (root.right == null || root.right == prev) { res.add(root.val); prev = root; root = null ; } else { stack.push(root); root = root.right; } } return res; } } class Solution { public List<Integer> postorderTraversal (TreeNode root) { List<Integer> res = new ArrayList <>(); Deque<TreeNode> stack = new LinkedList <>(); if (root == null ){ return res; } stack.push(root); while (!stack.isEmpty()) { TreeNode tmp = stack.pop(); res.add(tmp.val); if (tmp.left != null ) stack.push(tmp.left); if (tmp.right != null ) stack.push(tmp.right); } Collections.reverse(res); return res; } }
1.递归
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 class Solution { public List<List<Integer>> levelOrder (TreeNode root) { List<List<Integer>> res = new ArrayList <List<Integer>>(); dfs(root, 0 , res); return res; } public void dfs (TreeNode root, Integer level, List<List<Integer>> res) { if (root == null ) return ; if (res.size() <= level) { List<Integer> item = new ArrayList <Integer>(); res.add(item); } List<Integer> list = res.get(level); list.add(root.val); dfs(root.left, level + 1 , res); dfs(root.right, level + 1 , res); } }
2.迭代
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 class Solution { public List<List<Integer>> levelOrder (TreeNode root) { List<List<Integer>> res = new ArrayList <List<Integer>>(); if (root == null ) { return res; } Queue<TreeNode> queue = new LinkedList <>(); queue.offer(root); while (!queue.isEmpty()) { List<Integer> level = new ArrayList <Integer>(); int currentLevelSize = queue.size(); for (int i = 0 ; i < currentLevelSize; i++) { TreeNode node = queue.poll(); level.add(node.val); if (node.left != null ) { queue.offer(node.left); } if (node.right != null ) { queue.offer(node.right); } } res.add(level); } return res; } }
从上到下打印出二叉树的每个节点,同一层的节点按照从左到右的顺序打印。
例如:[3,9,20,null,null,15,7],
返回:
递归
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 class Solution { public int [] levelOrder(TreeNode root) { List<Integer> res = new ArrayList <>(); dfs(root, 0 , res); return res.stream().mapToInt(Integer::valueOf).toArray(); } public void dfs (TreeNode root, Integer level, List<Integer> res) { if (root == null ) return ; res.add(root.val); dfs(root.left, level + 1 , res); dfs(root.right, level + 1 , res); } }
迭代
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 class Solution { public int [] levelOrder(TreeNode root) { if (root == null ) { return new int [0 ]; } List<Integer> list = new ArrayList (); Queue<TreeNode> q = new LinkedList (); q.offer(root); while (!q.isEmpty()){ int n = q.size(); for (int i = 0 ; i < n; i++){ TreeNode node = q.poll(); list.add(node.val); if (node.left != null ){ q.offer(node.left); } if (node.right != null ){ q.offer(node.right); } } } int [] res = new int [list.size()]; for (int i = 0 ; i < list.size(); i++) res[i] = list.get(i); return res; } }
给你二叉树的根节点 root ,返回其节点值的 锯齿形层序遍历 。(即先从左往右,再从右往左进行下一层遍历,以此类推,层与层之间交替进行)。
示例 1:
1 2 输入:root = [3,9,20,null,null,15,7] 输出:[[3],[20,9],[15,7]]
示例 2:
示例 3:
递归
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 class Solution { public List<List<Integer>> zigzagLevelOrder (TreeNode root) { List<List<Integer>> res = new ArrayList <List<Integer>>(); dfs(root, 0 , res); return res; } public void dfs (TreeNode root, Integer level, List<List<Integer>> res) { if (root == null ) return ; if (res.size() <= level) { List<Integer> item = new ArrayList <>(); res.add(item); } List<Integer> list = res.get(level); if (level % 2 == 0 ){ list.add(root.val); } else { list.add(0 , root.val); } dfs(root.left, level + 1 , res); dfs(root.right, level + 1 , res); } }
迭代
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 class Solution { public List<List<Integer>> zigzagLevelOrder (TreeNode root) { List<List<Integer>> res = new ArrayList <List<Integer>>(); if (root == null ){ return res; } Queue<TreeNode> queue = new LinkedList <>(); queue.offer(root); boolean flag = true ; while (!queue.isEmpty()){ List<Integer> list = new ArrayList <>(); int n = queue.size(); for (int i = 0 ; i < n; i++){ TreeNode node = queue.poll(); if (flag){ list.add(node.val); } else { list.add(0 , node.val); } if (node.left != null ) { queue.offer(node.left); } if (node.right != null ) { queue.offer(node.right); } } flag = !flag; res.add(list); } return res; } }
❷二叉树深度
给定一个二叉树,找出其最大深度。
二叉树的深度为根节点到最远叶子节点的最长路径上的节点数。
说明: 叶子节点是指没有子节点的节点。
示例: [3,9,20,null,null,15,7],
返回它的最大深度 3 。
1.递归
1 2 3 4 5 6 7 8 9 10 11 12 13 class Solution { public int maxDepth (TreeNode root) { if (root == null ) { return 0 ; } int leftDepth = maxDepth(root.left); int rightDepth = maxDepth(root.right); return Math.max(leftDepth, rightDepth) + 1 ; } }
2.迭代
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 class Solution { public int maxDepth (TreeNode root) { if (root == null ) { return 0 ; } int count = 0 ; Queue<TreeNode> queue = new LinkedList <>(); queue.offer(root); while (!queue.isEmpty()){ int n = queue.size(); count++; for (int i = 0 ; i < n; i++){ TreeNode node = queue.poll(); if (node.left != null ) queue.offer(node.left); if (node.right != null ) queue.offer(node.right); } } return count; } }
给定一个 N 叉树,找到其最大深度。
最大深度是指从根节点到最远叶子节点的最长路径上的节点总数。
N 叉树输入按层序遍历序列化表示,每组子节点由空值分隔(请参见示例)。
示例 1:
1 2 输入:root = [1,null,3,2,4,null,5,6] 输出:3
示例 2:
1 2 输入:root = [1,null,2,3,4,5,null,null,6,7,null,8,null,9,10,null,null,11,null,12,null,13,null,null,14] 输出:5
1.递归
1 2 3 4 5 6 7 8 9 10 11 12 13 14 class Solution { public int maxDepth (Node root) { if (root == null ){ return 0 ; } int depth = 0 ; if (root.children != null ){ for (Node child : root.children){ depth = Math.max(depth, maxDepth(child)); } } return depth + 1 ; } }
2.迭代
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 class Solution { public int maxDepth (Node root) { if (root == null ){ return 0 ; } int depth = 0 ; Queue<Node> queue = new LinkedList <>(); queue.offer(root); while (!queue.isEmpty()){ int n = queue.size(); depth++; for (int i = 0 ; i < n; i++){ Node node = queue.poll(); if (node.children != null ) { for (Node child : node.children){ queue.offer(child); } } } } return depth; } }
给定一个二叉树,找出其最小深度。
最小深度是从根节点到最近叶子节点的最短路径上的节点数量。
**说明:**叶子节点是指没有子节点的节点。
示例 1:
1 2 输入:root = [3,9,20,null,null,15,7] 输出:2
示例 2:
1 2 输入:root = [2,null,3,null,4,null,5,null,6] 输出:5
1.递归
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 class Solution { public int minDepth (TreeNode root) { if (root == null ) return 0 ; if (root.left == null && root.right == null ) return 1 ; int m1 = minDepth(root.left); int m2 = minDepth(root.right); if (root.left == null || root.right == null ) return m1 + m2 + 1 ; return Math.min(m1, m2) + 1 ; } } class Solution { public int minDepth (TreeNode root) { if (root == null ) return 0 ; int m1 = minDepth(root.left); int m2 = minDepth(root.right); return root.left == null || root.right == null ? m1 + m2 + 1 : Math.min(m1,m2) + 1 ; } }
2.迭代
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 class Solution { public int minDepth (TreeNode root) { if (root == null ) return 0 ; Queue<TreeNode> queue = new LinkedList <>(); int depth = 1 ; queue.offer(root); while (!queue.isEmpty()){ int n = queue.size(); depth++; while (n > 0 ){ TreeNode node = queue.poll(); if (node.left != null ) queue.offer(node.left); if (node.right != null ) queue.offer(node.right); if (node.left == null && node.right == null ){ return depth; } n--; } } return depth; } }
给定一棵二叉树,你需要计算它的直径长度。一棵二叉树的直径长度是任意两个结点路径长度中的最大值。这条路径可能穿过也可能不穿过根结点。
示例 : 给定二叉树
返回 3 , 它的长度是路径 [4,2,1,3] 或者 [5,2,1,3]。
**注意:**两结点之间的路径长度是以它们之间边的数目表示。
当前节点的最大深度(节点层数) = Max(左孩子节点的最大深度, 右孩子节点的最大深度) + 1当前节点的最大直径 = 左孩子节点的最大深度 + 右孩子节点的最大深度
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 class Solution { int maxDiameter = 0 ; public int diameterOfBinaryTree (TreeNode root) { maxDepth(root); return maxDiameter; } int maxDepth (TreeNode root) { if (root == null ) { return 0 ; } int leftMax = maxDepth(root.left); int rightMax = maxDepth(root.right); maxDiameter = Math.max(maxDiameter, leftMax + rightMax); return Math.max(leftMax, rightMax) + 1 ; } }
❸二叉树属性
给你一棵二叉树的根节点 root ,翻转这棵二叉树,并返回其根节点。
示例 1:
1 2 输入:root = [4,2,7,1,3,6,9] 输出:[4,7,2,9,6,3,1]
示例 2:
1 2 输入:root = [2,1,3] 输出:[2,3,1]
示例 3:
1.递归
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 class Solution { public TreeNode invertTree (TreeNode root) { traverse(root); return root; } public void traverse (TreeNode root) { if (root == null ){ return ; } TreeNode tmp = root.left; root.left = root.right; root.right = tmp; traverse(root.left); traverse(root.right); } } class Solution { public TreeNode invertTree (TreeNode root) { if (root == null ) { return null ; } TreeNode left = invertTree(root.left); TreeNode right = invertTree(root.right); root.left = right; root.right = left; return root; } }
2.迭代
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 class Solution { public TreeNode invertTree (TreeNode root) { if (root==null ) { return null ; } LinkedList<TreeNode> queue = new LinkedList <TreeNode>(); queue.add(root); while (!queue.isEmpty()) { TreeNode tmp = queue.poll(); TreeNode left = tmp.left; tmp.left = tmp.right; tmp.right = left; if (tmp.left != null ) { queue.add(tmp.left); } if (tmp.right != null ) { queue.add(tmp.right); } } return root; } }
给你一个二叉树的根节点 root , 检查它是否轴对称。
示例 1:
1 2 输入:root = [1,2,2,3,4,4,3] 输出:true
示例 2:
1 2 输入:root = [1,2,2,null,3,null,3] 输出:false
1.递归
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 class Solution { public boolean isSymmetric (TreeNode root) { if (root == null ) return true ; return check(root.left, root.right); } boolean check (TreeNode left, TreeNode right) { if (left == null && right == null ) return true ; if (left == null || right == null ) return false ; if (left.val != right.val) return false ; return check(left.left, right.right) && check(left.right, right.left); } } class Solution { public boolean isSymmetric (TreeNode root) { if (root == null ) return true ; return check(root.left, root.right); } boolean check (TreeNode left, TreeNode right) { if (left == null || right == null ) return left == right; if (left.val != right.val) return false ; return check(left.left, right.right) && check(left.right, right.left); } }
2.迭代
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 class Solution { public boolean isSymmetric (TreeNode root) { LinkedList<TreeNode> queue = new LinkedList <TreeNode>(); queue.offer(root.left); queue.offer(root.right); while (queue.size() > 0 ) { TreeNode left = queue.poll(); TreeNode right = queue.poll(); if (left == null && right == null ) { continue ; } if (left == null || right == null ) { return false ; } if (left.val != right.val) { return false ; } queue.offer(left.left); queue.offer(right.right); queue.offer(left.right); queue.offer(right.left); } return true ; } }
给定一个二叉树,判断它是否是高度平衡的二叉树。
本题中,一棵高度平衡二叉树定义为:一个二叉树每个节点 的左右两个子树的高度差的绝对值不超过 1 。
示例 1:
1 2 输入:root = [3,9,20,null,null,15,7] 输出:true
示例 2:
1 2 输入:root = [1,2,2,3,3,null,null,4,4] 输出:false
示例 3:
1.从顶至底(暴力法)
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 class Solution { public boolean isBalanced (TreeNode root) { if (root == null ) { return true ; } if (Math.abs(height(root.left) - height(root.right)) > 1 ) { return false ; } return isBalanced(root.left) && isBalanced(root.right); } int height (TreeNode root) { if (root == null ) return 0 ; int lHeight = height(root.left); int rHeight = height(root.right); return Math.max(lHeight, rHeight) + 1 ; } }
2.从底至顶(提前阻断)
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 class Solution { public boolean isBalanced (TreeNode root) { return height(root) != -1 ; } int height (TreeNode root) { if (root == null ) return 0 ; int lHeight = height(root.left); int rHeight = height(root.right); if (lHeight == -1 || rHeight == -1 || Math.abs(lHeight - rHeight) > 1 ) { return -1 ; } else { return Math.max(lHeight, rHeight) + 1 ; } } }
给定一个二叉树的 根节点 root,想象自己站在它的右侧,按照从顶部到底部的顺序,返回从右侧所能看到的节点值。
示例 1:
1 2 输入 : [1,2,3,null,5,null,4] 输出 : [1,3,4]
示例 2:
1 2 输入 : [1,null,3] 输出 : [1,3]
示例 3:
1.BFS 用 BFS 层序遍历算法,每一层的最后一个节点就是二叉树的右侧视图。我们可以把 BFS 反过来,从右往左遍历每一行,进一步提升效率。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 class Solution { public List<Integer> rightSideView (TreeNode root) { List<Integer> res = new ArrayList <>(); if (root == null ){ return res; } Queue<TreeNode> queue = new LinkedList <>(); queue.offer(root); while (!queue.isEmpty()){ int n = queue.size(); TreeNode last = queue.peek(); for (int i = 0 ; i < n; i++){ TreeNode node = queue.poll(); if (node.right != null ) { queue.offer(node.right); } if (node.left != null ){ queue.offer(node.left); } } res.add(last.val); } return res; } }
2.DFS 用 DFS 递归遍历算法,同样需要反过来,先递归 root.right 再递归 root.left。按照 「根结点 -> 右子树 -> 左子树」 的顺序访问,就可以保证每层都是最先访问最右边的节点的。同时用 res 记录每一层的最右侧节点作为右侧视图。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 class Solution { List<Integer> res = new ArrayList <>(); public List<Integer> rightSideView (TreeNode root) { dfs(root, 0 ); return res; } private void dfs (TreeNode root, int depth) { if (root == null ) { return ; } if (depth == res.size()) { res.add(root.val); } depth++; dfs(root.right, depth); dfs(root.left, depth); } }
给你两棵二叉树 root 和 subRoot 。检验 root 中是否包含和 subRoot 具有相同结构和节点值的子树。如果存在,返回 true ;否则,返回 false 。
二叉树 tree 的一棵子树包括 tree 的某个节点和这个节点的所有后代节点。tree 也可以看做它自身的一棵子树。
示例 1:
1 2 输入:root = [3,4,5,1,2], subRoot = [4,1,2] 输出:true
示例 2:
1 2 输入:root = [3,4,5,1,2,null,null,null,null,0], subRoot = [4,1,2] 输出:false
首先任意看一个节点的root.val,该节点可能等于subRoot.val,也可能不相等,共有两种可能,对应的也就有两种不同的操作:
当root.val == subRoot.val时,则判断剩余的后代节点是否都相等,如果有其中一个不相等,则subRoot不是root的子树,返回false,如果走到叶子节点都相等的话返回true;
当root.val != subRoot.val时, 则接着到root的左右节点比较,只要有其中一个满足子树,就返回true;
递归上述两种情况则可判断是否存在子树。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 class Solution { public boolean isSubtree (TreeNode root, TreeNode subRoot) { if (root == null || subRoot == null ) { return false ; } return dfs(root, subRoot) || isSubtree(root.left, subRoot) || isSubtree(root.right, subRoot); } public boolean dfs (TreeNode root, TreeNode subRoot) { if (root == null && subRoot == null ) return true ; if (root == null || subRoot == null || root.val != subRoot.val){ return false ; } return dfs(root.left, subRoot.left) && dfs(root.right, subRoot.right); } }
❹二叉树路径
解题模版:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 List<String> res = new ArrayList <>(); List<int > path = new ArrayList <>(); void dfs (TreeNode root) { if (root == null ) { return ; } path.add(root.val); if (root.left == null && root.right == null ) { res.add(new ArrayList (path)); } dfs(root.left); dfs(root.right); } }
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 List<List<Integer>> res = new ArrayList <>(); List<Integer> path = new ArrayList <>(); void dfs (TreeNode root, int targetSum) { if (root == null ) { return ; } path.add(root.val); if (root.left == null && root.right == null ) { if (targetSum == root.val){ res.add(new ArrayList (path)); } } dfs(root.left, targetSum - root.val); dfs(root.right, targetSum - root.val); path.remove(path.size() - 1 ); }
给你一个二叉树的根节点 root ,按 任意顺序 ,返回所有从根节点到叶子节点的路径。
叶子节点 是指没有子节点的节点。
示例 1:
1 2 输入:root = [1,2,3,null,5] 输出:["1->2->5","1->3"]
示例 2:
1.深度优先
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 class Solution { public List<String> binaryTreePaths (TreeNode root) { List<String> res = new ArrayList <>(); dfs(root, "" , res); return res; } private void dfs (TreeNode root, String path, List<String> res) { if (root == null ) return ; if (root.left == null && root.right == null ) { res.add(path + root.val); return ; } dfs(root.left, path + root.val + "->" , res); dfs(root.right, path + root.val + "->" , res); } } class Solution { public List<String> binaryTreePaths (TreeNode root) { List<String> res = new LinkedList <>(); if (root == null ) return res; if (root.left == null && root.right == null ) { res.add(root.val + "" ); return res; } for (String path : binaryTreePaths(root.left)) { res.add(root.val + "->" + path); } for (String path : binaryTreePaths(root.right)) { res.add(root.val + "->" + path); } return res; } }
2.广度优先
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 class Solution { public List<String> binaryTreePaths (TreeNode root) { List<String> res = new ArrayList <>(); if (root == null ) return res; Queue<Object> queue = new LinkedList <>(); queue.offer(root); queue.offer(root.val + "" ); while (!queue.isEmpty()) { TreeNode node = (TreeNode) queue.poll(); String path = (String) queue.poll(); if (node.left == null && node.right == null ) { res.add(path); } if (node.right != null ) { queue.offer(node.right); queue.offer(path + "->" + node.right.val); } if (node.left != null ) { queue.offer(node.left); queue.offer(path + "->" + node.left.val); } } return res; } } class Solution { public List<String> binaryTreePaths (TreeNode root) { List<String> paths = new ArrayList <String>(); if (root == null ) { return paths; } Queue<TreeNode> nodeQueue = new LinkedList <TreeNode>(); Queue<String> pathQueue = new LinkedList <String>(); nodeQueue.offer(root); pathQueue.offer(Integer.toString(root.val)); while (!nodeQueue.isEmpty()) { TreeNode node = nodeQueue.poll(); String path = pathQueue.poll(); if (node.left == null && node.right == null ) { paths.add(path); } if (node.left != null ) { nodeQueue.offer(node.left); pathQueue.offer(new StringBuffer (path).append("->" ).append(node.left.val).toString()); } if (node.right != null ) { nodeQueue.offer(node.right); pathQueue.offer(new StringBuffer (path).append("->" ).append(node.right.val).toString()); } } return paths; } }
给你二叉树的根节点 root 和一个表示目标和的整数 targetSum 。判断该树中是否存在 根节点到叶子节点 的路径,这条路径上所有节点值相加等于目标和 targetSum 。如果存在,返回 true ;否则,返回 false 。
示例 1:
1 2 3 输入:root = [5,4,8,11,null,13,4,7,2,null,null,null,1], targetSum = 22 输出:true 解释:等于目标和的根节点到叶节点路径如上图所示。
示例 2:
1 2 3 4 5 6 输入:root = [1,2,3], targetSum = 5 输出:false 解释:树中存在两条根节点到叶子节点的路径: (1 --> 2): 和为 3 (1 --> 3): 和为 4 不存在 sum = 5 的根节点到叶子节点的路径。
示例 3:
1 2 3 输入:root = [], targetSum = 0 输出:false 解释:由于树是空的,所以不存在根节点到叶子节点的路径。
1.深度优先
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 class Solution { public boolean hasPathSum (TreeNode root, int sum) { if (root == null ) { return false ; } if (root.left == null && root.right == null ) { return sum == root.val; } return hasPathSum(root.left, sum - root.val) || hasPathSum(root.right, sum - root.val); } } class Solution { public boolean hasPathSum (TreeNode root, int targetSum) { List<Integer> res = new ArrayList <>(); dfs(root, 0 , res); for (int i : res){ if (i == targetSum){ return true ; } } return false ; } private void dfs (TreeNode root, int sum, List<Integer> res) { if (root == null ) return ; if (root.left == null && root.right == null ) { res.add(sum + root.val); return ; } dfs(root.left, sum + root.val , res); dfs(root.right, sum + root.val , res); } } class Solution { List<Integer> res = new ArrayList <>(); boolean flag = false ; public boolean hasPathSum (TreeNode root, int targetSum) { dfs(root, targetSum); return flag; } private void dfs (TreeNode root, int targetSum) { if (root == null ) { return ; } if (root.left == null && root.right == null ) { if (targetSum == root.val){ flag = true ; } } dfs(root.left, targetSum - root.val); dfs(root.right, targetSum - root.val); } }
2.广度优先
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 class Solution { public boolean hasPathSum (TreeNode root, int targetSum) { List<Integer> res = new ArrayList <>(); if (root == null ) return false ; Queue<Object> queue = new LinkedList <>(); queue.offer(root); queue.offer(root.val); while (!queue.isEmpty()) { TreeNode node = (TreeNode) queue.poll(); int path = (int ) queue.poll(); if (node.left == null && node.right == null ) { res.add(path); } if (node.right != null ) { queue.offer(node.right); queue.offer(path + node.right.val); } if (node.left != null ) { queue.offer(node.left); queue.offer(path + node.left.val); } } for (int i : res){ if (i == targetSum){ return true ; } } return false ; } } class Solution { public boolean hasPathSum (TreeNode root, int sum) { if (root == null ) { return false ; } Queue<TreeNode> queNode = new LinkedList <TreeNode>(); Queue<Integer> queVal = new LinkedList <Integer>(); queNode.offer(root); queVal.offer(root.val); while (!queNode.isEmpty()) { TreeNode now = queNode.poll(); int temp = queVal.poll(); if (now.left == null && now.right == null ) { if (temp == sum) { return true ; } continue ; } if (now.left != null ) { queNode.offer(now.left); queVal.offer(now.left.val + temp); } if (now.right != null ) { queNode.offer(now.right); queVal.offer(now.right.val + temp); } } return false ; } }
给你二叉树的根节点 root 和一个整数目标和 targetSum ,找出所有 从根节点到叶子节点 路径总和等于给定目标和的路径。
示例 1:
1 2 输入:root = [5,4,8,11,null,13,4,7,2,null,null,5,1], targetSum = 22 输出:[[5,4,11,2],[5,8,4,5]]
示例 2:
img
1 2 输入:root = [1,2,3], targetSum = 5 输出:[]
示例 3:
1 2 输入:root = [1,2], targetSum = 0 输出:[]
1.深度优先
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 class Solution { List<List<Integer>> res = new ArrayList <>(); List<Integer> path = new ArrayList <>(); public List<List<Integer>> pathSum (TreeNode root, int targetSum) { dfs(root, targetSum); return res; } void dfs (TreeNode root, int targetSum) { if (root == null ) { return ; } path.add(root.val); if (root.left == null && root.right == null ) { if (targetSum == root.val){ res.add(new ArrayList (path)); } } dfs(root.left, targetSum - root.val); dfs(root.right, targetSum - root.val); path.remove(path.size() - 1 ); } }
2.广度优先
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 class Solution { public List<List<Integer>> pathSum (TreeNode root, int targetSum) { List<List<Integer>> res = new ArrayList <>(); if (root == null ){ return res; } Queue<TreeNode> nodeQueue = new LinkedList <>(); Queue<List<Integer>> pathQueue = new LinkedList <>(); nodeQueue.offer(root); List<Integer> pathList = new ArrayList <>(); pathList.add(root.val); pathQueue.offer(pathList); while (!nodeQueue.isEmpty()){ TreeNode node = nodeQueue.poll(); List<Integer> tempList = pathQueue.poll(); if (node.left == null && node.right == null ){ int pathSum = 0 ; for (int i : tempList){ pathSum += i; } if (pathSum == targetSum){ res.add(tempList); } } if (node.left != null ){ nodeQueue.offer(node.left); tempList.add(node.left.val); pathQueue.offer(new ArrayList <>(tempList)); tempList.remove(tempList.size() - 1 ); } if (node.right != null ){ nodeQueue.offer(node.right); tempList.add(node.right.val); pathQueue.offer(new ArrayList <>(tempList)); } } return res; } }
给定一个二叉树的根节点 root ,和一个整数 targetSum ,求该二叉树里节点值之和等于 targetSum 的 路径 的数目。
路径 不需要从根节点开始,也不需要在叶子节点结束,但是路径方向必须是向下的(只能从父节点到子节点)。
示例 1:
1 2 3 输入:root = [10,5,-3,3,2,null,11,3,-2,null,1], targetSum = 8 输出:3 解释:和等于 8 的路径有 3 条,如图所示。
示例 2:
1 2 输入:root = [5,4,8,11,null,13,4,7,2,null,null,5,1], targetSum = 22 输出:3
双重循环
第一重递归使用前序遍历的方法遍历每个节点
第二重递归用于以每一个节点为开始节点再次遍历寻找符合结果的路径
枚举每个节点,计算往下遍历过程中和为targetSum的路径个数。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 class Solution { int count = 0 ; public int pathSum (TreeNode root, long targetSum) { if (root == null ) return 0 ; dfs(root, targetSum); pathSum(root.left, targetSum); pathSum(root.right, targetSum); return count; } void dfs (TreeNode root, long targetSum) { if (root == null ) return ; if (targetSum == root.val) count++; dfs(root.left, targetSum - root.val); dfs(root.right, targetSum - root.val); } }
二叉树中的 路径 被定义为一条节点序列,序列中每对相邻节点之间都存在一条边。同一个节点在一条路径序列中 至多出现一次 。该路径 至少包含一个 节点,且不一定经过根节点。
路径和 是路径中各节点值的总和。
给你一个二叉树的根节点 root ,返回其 最大路径和 。
示例 1:
1 2 3 输入:root = [1,2,3] 输出:6 解释:最优路径是 2 -> 1 -> 3 ,路径和为 2 + 1 + 3 = 6
示例 2:
1 2 3 输入:root = [-10,9,20,null,null,15,7] 输出:42 解释:最优路径是 15 -> 20 -> 7 ,路径和为 15 + 20 + 7 = 42
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 class Solution { int max = Integer.MIN_VALUE; public int maxPathSum (TreeNode root) { if (root == null ) { return 0 ; } dfs(root); return max; } public int dfs (TreeNode root) { if (root == null ) { return 0 ; } int leftMax = Math.max(0 , dfs(root.left)); int rightMax = Math.max(0 , dfs(root.right)); max = Math.max(max, root.val + leftMax + rightMax); return root.val + Math.max(leftMax, rightMax); } }
给你一棵以 root 为根的二叉树,二叉树中的交错路径定义如下:
选择二叉树中 任意 节点和一个方向(左或者右)。
如果前进方向为右,那么移动到当前节点的的右子节点,否则移动到它的左子节点。
改变前进方向:左变右或者右变左。
重复第二步和第三步,直到你在树中无法继续移动。
交错路径的长度定义为:访问过的节点数目 - 1 (单个节点的路径长度为 0 )。
请你返回给定树中最长 交错路径 的长度。
示例 1:
1 2 3 输入:root = [1,null,1,1,1,null,null,1,1,null,1,null,null,null,1,null,1] 输出:3 解释:蓝色节点为树中最长交错路径(右 -> 左 -> 右)。
示例 2:
1 2 3 输入:root = [1,1,1,null,1,null,null,1,1,null,1] 输出:4 解释:蓝色节点为树中最长交错路径(左 -> 右 -> 左 -> 右)。
示例 3:
设 direct == 1表示向左移动,direct == 2表示向右移动
dfs递归遍历树节点时需要注意,如果连续向左或者向右,则需要重新计算交错节点。 如:dfs(root.left, direct == 1 ? 1 : count + 1, 1);
当root向左移动,并且direct == 1时,那么这个时候连续的交错节点就断开了(因为连续两次或以上向左移动),count需要重新计算,所以递归下去的值要为1,否则为count + 1
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 class Solution { private int max = 0 ; public int longestZigZag (TreeNode root) { if (root == null ) { return 0 ; } dfs(root.left, 1 , 1 ); dfs(root.right, 1 , 2 ); return max; } public void dfs (TreeNode root, int count, int direct) { if (root == null ) { return ; } max = Math.max(max, count); dfs(root.left, direct == 1 ? 1 : count + 1 , 1 ); dfs(root.right, direct == 2 ? 1 : count + 1 , 2 ); } }
❺二叉树节点
给定二叉树的根节点 root ,返回所有左叶子之和。
示例 1:
1 2 3 输入 : root = [3,9,20,null,null,15,7] 输出 : 24 解释 : 在这个二叉树中,有两个左叶子,分别是 9 和 15,所以返回 24
示例 2:
1.深度优先
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 class Solution { public int sumOfLeftLeaves (TreeNode root) { dfs(root); return sum; } int sum = 0 ; void dfs (TreeNode root) { if (root == null ){ return ; } if (root.left != null && root.left.left == null && root.left.right == null ) { sum += root.left.val; } dfs(root.left); dfs(root.right); } }
2.广度优先
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 class Solution { public int sumOfLeftLeaves (TreeNode root) { if (root == null ){ return 0 ; } Queue<TreeNode> queue = new LinkedList <>(); queue.offer(root); int sum = 0 ; while (!queue.isEmpty()){ int n = queue.size(); for (int i = 0 ; i < n; i++){ TreeNode node = queue.poll(); if (node.left != null ) { if (node.left.left == null && node.left.right == null ) { sum += node.left.val; } else { queue.offer(node.left); } } if (node.right != null ) queue.offer(node.right); } } return sum; } } class Solution { public int sumOfLeftLeaves (TreeNode root) { if (root == null ){ return 0 ; } Queue<TreeNode> queue = new LinkedList <>(); queue.offer(root); int sum = 0 ; while (!queue.isEmpty()){ TreeNode node = queue.poll(); if (node.left != null ) { if (node.left.left == null && node.left.right == null ) { sum += node.left.val; } else { queue.offer(node.left); } } if (node.right != null ) queue.offer(node.right); } return sum; } }
此题同:剑指 Offer II 045. 二叉树最底层最左边的值
给定一个二叉树的 根节点 root,请找出该二叉树的 最底层 最左边 节点的值。
假设二叉树中至少有一个节点。
示例 1:
1 2 输入 : root = [2,1,3] 输出 : 1
示例 2:
1 2 输入 : [1,2,3,4,null,5,6,null,null,7] 输出 : 7
1.广度优先
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 class Solution { public int findBottomLeftValue (TreeNode root) { if (root == null ){ return 0 ; } Queue<TreeNode> queue = new LinkedList <>(); queue.offer(root); int res = 0 ; while (!queue.isEmpty()){ int n = queue.size(); for (int i = 0 ; i < n; i++){ TreeNode node = queue.poll(); if (i == 0 ){ res = node.val; } if (node.left != null ) queue.offer(node.left); if (node.right != null ) queue.offer(node.right); } } return res; } } class Solution { public int findBottomLeftValue (TreeNode root) { int res = 0 ; Queue<TreeNode> queue = new ArrayDeque <TreeNode>(); queue.offer(root); while (!queue.isEmpty()) { TreeNode node = queue.poll(); if (node.right != null ) queue.offer(node.right); if (node.left != null ) queue.offer(node.left); res = node.val; } return res; } }
2.深度优先
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 class Solution { int maxDepth = 0 ; int res = 0 ; public int findBottomLeftValue (TreeNode root) { dfs(root, 1 ); return res; } void dfs (TreeNode root, int depth) { if (root == null ){ return ; } if (depth > maxDepth) { maxDepth = depth; res = root.val; } dfs(root.left, depth + 1 ); dfs(root.right, depth + 1 ); } }
给你一棵二叉树的根节点 root ,请你返回 层数最深的叶子节点的和 。
示例 1:
1 2 输入:root = [1,2,3,4,5,null,6,7,null,null,null,null,8] 输出:15
示例 2:
1 2 输入:root = [6,7,8,2,7,1,3,9,null,1,4,null,null,null,5] 输出:19
1.广度优先
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 class Solution { public int deepestLeavesSum (TreeNode root) { if (root == null ) return 0 ; Queue<TreeNode> queue = new LinkedList <>(); queue.offer(root); int sum = 0 ; while (!queue.isEmpty()){ int n = queue.size(); sum = 0 ; for (int i = 0 ; i < n; i++){ TreeNode node = queue.poll(); sum += node.val; if (node.left != null ) queue.offer(node.left); if (node.right != null ) queue.offer(node.right); } } return sum; } }
2.深度优先
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 class Solution { int maxDepth = 0 ; int sum = 0 ; public int deepestLeavesSum (TreeNode root) { dfs(root, 1 ); return sum; } void dfs (TreeNode root, int depth) { if (root == null ){ return ; } if (depth > maxDepth) { maxDepth = depth; sum = root.val; } else if (depth == maxDepth) { sum += root.val; } dfs(root.left, depth + 1 ); dfs(root.right, depth + 1 ); } }
给你一棵 完全二叉树 的根节点 root ,求出该树的节点个数。
完全二叉树的定义如下:在完全二叉树中,除了最底层节点可能没填满外,其余每层节点数都达到最大值,并且最下面一层的节点都集中在该层最左边的若干位置。若最底层为第 h 层,则该层包含 1~2^h 个节点。
示例 1:
1 2 输入:root = [1,2,3,4,5,6] 输出:6
示例 2:
示例 3:
1.递归
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 class Solution { public int countNodes (TreeNode root) { if (root == null ){ return 0 ; } int countleft = countNodes(root.left); int countright = countNodes(root.right); return countleft + countright + 1 ; } } public int countNodes (TreeNode root) { if (root == null ) return 0 ; int left = countLevel(root.left); int right = countLevel(root.right); if (left == right){ return countNodes(root.right) + (1 << left); } else { return countNodes(root.left) + (1 << right); } } int countLevel (TreeNode root) { int level = 0 ; while (root != null ){ root = root.left; level++; } return level; }
2.迭代
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 class Solution { public int countNodes (TreeNode root) { if (root == null ){ return 0 ; } int res = 0 ; Queue<TreeNode> queue = new LinkedList <>(); queue.offer(root); while (!queue.isEmpty()){ int n = queue.size(); res += n; for (int i = 0 ; i < n; i++){ TreeNode node = queue.poll(); if (node.left != null ) queue.offer(node.left); if (node.right != null ) queue.offer(node.right); } } return res; } }
请考虑一棵二叉树上所有的叶子,这些叶子的值按从左到右的顺序排列形成一个 叶值序列 。
举个例子,如上图所示,给定一棵叶值序列为 (6, 7, 4, 9, 8) 的树。
如果有两棵二叉树的叶值序列是相同,那么我们就认为它们是 叶相似 的。
如果给定的两个根结点分别为 root1 和 root2 的树是叶相似的,则返回 true;否则返回 false 。
示例 1:
1 2 输入:root1 = [3,5,1,6,2,9,8,null,null,7,4], root2 = [3,5,1,6,7,4,2,null,null,null,null,null,null,9,8] 输出:true
示例 2:
1 2 输入:root1 = [1,2,3], root2 = [1,3,2] 输出:false
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 class Solution { public boolean leafSimilar (TreeNode root1, TreeNode root2) { List<Integer> list1 = new ArrayList <>(); if (root1 != null ) dfs(root1, list1); List<Integer> list2 = new ArrayList <>(); if (root2 != null ) dfs(root2, list2); return list1.equals(list2); } public void dfs (TreeNode node, List<Integer> list) { if (node.left == null && node.right == null ){ list.add(node.val); } else { if (node.left != null ){ dfs(node.left, list); } if (node.right != null ){ dfs(node.right, list); } } } }
给你一棵根为 root 的二叉树,请你返回二叉树中好节点的数目。
「好节点」X 定义为:从根到该节点 X 所经过的节点中,没有任何节点的值大于 X 的值。
示例 1:
1 2 3 4 5 6 7 输入:root = [3,1,4,3,null,1,5] 输出:4 解释:图中蓝色节点为好节点。 根节点 (3) 永远是个好节点。 节点 4 -> (3,4) 是路径中的最大值。 节点 5 -> (3,4,5) 是路径中的最大值。 节点 3 -> (3,1,3) 是路径中的最大值。
示例 2:
1 2 3 输入:root = [3,3,null,4,2] 输出:3 解释:节点 2 -> (3, 3, 2) 不是好节点,因为 "3" 比它大。
示例 3:
1 2 3 输入:root = [1] 输出:1 解释:根节点是好节点。
DFS深度递归子节点,递归过程中维护根节点到子节点的最大值,然后比较子节点和最大值来判断该节点是否为好节点。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 class Solution { private int ans = 0 ; public int goodNodes (TreeNode root) { dfs(root, root.val); return ans; } public void dfs (TreeNode root, int max) { if (root == null ){ return ; } if (root.val >= max){ ans++; max = root.val; } dfs(root.left, max); dfs(root.right, max); } }
❻二叉树构建
给定两个整数数组 inorder 和 postorder ,其中 inorder 是二叉树的中序遍历, postorder 是同一棵树的后序遍历,请你构造并返回这颗 二叉树 。
示例 1:
1 2 输入:inorder = [9,3,15,20,7], postorder = [9,15,7,20,3] 输出:[3,9,20,null,null,15,7]
示例 2:
1 2 输入:inorder = [-1], postorder = [-1] 输出:[-1]
构造二叉树,第一件事一定是找根节点,然后想办法构造左右子树 。
中序遍历的顺序:左孩子,根节点,右孩子。
后序遍历的顺序:左孩子,右孩子,根节点。
后序遍历结果最后一个就是根节点的值,然后再根据中序遍历结果确定左右子树的节点。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 class Solution { HashMap<Integer, Integer> valToIndex = new HashMap <>(); public TreeNode buildTree (int [] inorder, int [] postorder) { for (int i = 0 ; i < inorder.length; i++) { valToIndex.put(inorder[i], i); } return build(inorder, 0 , inorder.length - 1 , postorder, 0 , postorder.length - 1 ); } TreeNode build (int [] inorder, int inStart, int inEnd, int [] postorder, int postStart, int postEnd) { if (inStart > inEnd) { return null ; } int rootVal = postorder[postEnd]; int index = valToIndex.get(rootVal); int leftSize = index - inStart; TreeNode root = new TreeNode (rootVal); root.left = build(inorder, inStart, index - 1 , postorder, postStart, postStart + leftSize - 1 ); root.right = build(inorder, index + 1 , inEnd, postorder, postStart + leftSize, postEnd - 1 ); return root; } }
本题与剑指 Offer 07. 重建二叉树 相同
给定两个整数数组 preorder 和 inorder ,其中 preorder 是二叉树的先序遍历 , inorder 是同一棵树的中序遍历 ,请构造二叉树并返回其根节点。
示例 1:
1 2 输入 : preorder = [3,9,20,15,7], inorder = [9,3,15,20,7] 输出 : [3,9,20,null,null,15,7]
示例 2:
1 2 输入 : preorder = [-1], inorder = [-1] 输出 : [-1]
构造二叉树,第一件事一定是找根节点,然后想办法构造左右子树 。
前序遍历结果第一个就是根节点的值,然后再根据中序遍历结果确定左右子树的节点。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 class Solution { HashMap<Integer, Integer> valToIndex = new HashMap <>(); public TreeNode buildTree (int [] preorder, int [] inorder) { for (int i = 0 ; i < inorder.length; i++) { valToIndex.put(inorder[i], i); } return build(preorder, 0 , preorder.length - 1 , inorder, 0 , inorder.length - 1 ); } public TreeNode build (int [] preorder, int preStart, int preEnd, int [] inorder, int inStart, int inEnd) { if (preStart > preEnd) { return null ; } int rootVal = preorder[preStart]; int index = valToIndex.get(rootVal); int leftSize = index - inStart; TreeNode root = new TreeNode (rootVal); root.left = build(preorder, preStart + 1 , preStart + leftSize, inorder, inStart, index - 1 ); root.right = build(preorder, preStart + leftSize + 1 , preEnd, inorder, index + 1 , inEnd); return root; } }
给定两个整数数组,preorder 和 postorder ,其中 preorder 是一个具有 无重复 值的二叉树的前序遍历,postorder 是同一棵树的后序遍历,重构并返回二叉树。
如果存在多个答案,您可以返回其中 任何 一个。
示例 1:
1 2 输入:preorder = [1,2,4,5,3,6,7], postorder = [4,5,2,6,7,3,1] 输出:[1,2,3,4,5,6,7]
示例 2:
1 2 输入 : preorder = [1], postorder = [1] 输出 : [1]
1、首先把前序遍历结果的第一个元素或者后序遍历结果的最后一个元素确定为根节点的值 。
2、然后把前序遍历结果的第二个元素作为左子树的根节点的值 。
3、在后序遍历结果中寻找左子树根节点的值,从而确定了左子树的索引边界,进而确定右子树的索引边界,递归构造左右子树即可 。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 class Solution { HashMap<Integer, Integer> valToIndex = new HashMap <>(); public TreeNode constructFromPrePost (int [] preorder, int [] postorder) { for (int i = 0 ; i < postorder.length; i++) { valToIndex.put(postorder[i], i); } return build(preorder, 0 , preorder.length - 1 , postorder, 0 , postorder.length - 1 ); } TreeNode build (int [] preorder, int preStart, int preEnd, int [] postorder, int postStart, int postEnd) { if (preStart > preEnd) { return null ; } if (preStart == preEnd) { return new TreeNode (preorder[preStart]); } int rootVal = preorder[preStart]; int leftRootVal = preorder[preStart + 1 ]; int index = valToIndex.get(leftRootVal); int leftSize = index - postStart + 1 ; TreeNode root = new TreeNode (rootVal); root.left = build(preorder, preStart + 1 , preStart + leftSize, postorder, postStart, index); root.right = build(preorder, preStart + leftSize + 1 , preEnd, postorder, index + 1 , postEnd - 1 ); return root; } }
给定一个不重复的整数数组 nums 。 最大二叉树 可以用下面的算法从 nums 递归地构建:
创建一个根节点,其值为 nums 中的最大值。
递归地在最大值 左边 的 子数组前缀上 构建左子树。
递归地在最大值 右边 的 子数组后缀上 构建右子树。
返回 nums 构建的最大二叉树 。
示例 1:
1 2 3 4 5 6 7 8 9 10 11 12 输入:nums = [3,2,1,6,0,5] 输出:[6,3,5,null,2,0,null,null,1] 解释:递归调用如下所示: - [3,2,1,6,0,5] 中的最大值是 6 ,左边部分是 [3,2,1] ,右边部分是 [0,5] 。 - [3,2,1] 中的最大值是 3 ,左边部分是 [] ,右边部分是 [2,1] 。 - 空数组,无子节点。 - [2,1] 中的最大值是 2 ,左边部分是 [] ,右边部分是 [1] 。 - 空数组,无子节点。 - 只有一个元素,所以子节点是一个值为 1 的节点。 - [0,5] 中的最大值是 5 ,左边部分是 [0] ,右边部分是 [] 。 - 只有一个元素,所以子节点是一个值为 0 的节点。 - 空数组,无子节点。
示例 2:
1 2 输入:nums = [3,2,1] 输出:[3,null,2,null,1]
1.递归
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 class Solution { public TreeNode constructMaximumBinaryTree (int [] nums) { return build(nums, 0 , nums.length - 1 ); } TreeNode build (int [] nums, int start, int end) { if (start > end){ return null ; } int maxVal = Integer.MIN_VALUE; int maxIndex = -1 ; for (int i = start; i <= end; i++){ if (nums[i] > maxVal){ maxVal = nums[i]; maxIndex = i; } } TreeNode root = new TreeNode (maxVal); root.left = build(nums, start, maxIndex - 1 ); root.right = build(nums, maxIndex + 1 , end); return root; } }
2.单调栈(递减)
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 class Solution { public TreeNode constructMaximumBinaryTree (int [] nums) { Deque<TreeNode> stack = new ArrayDeque (); for (int i = 0 ; i < nums.length; i++) { TreeNode node = new TreeNode (nums[i]); while (!stack.isEmpty()) { TreeNode topNode = stack.peek(); if (topNode.val > node.val) { stack.push(node); topNode.right = node; break ; } else { stack.pop(); node.left = topNode; } } if (stack.isEmpty()) stack.push(node); } return stack.peekLast(); } } class Solution { public TreeNode constructMaximumBinaryTree (int [] nums) { TreeNode[] deque = new TreeNode [1001 ]; int tail = 0 ; for (int i = 0 ; i < nums.length; i++) { TreeNode node = new TreeNode (nums[i]); while (tail != 0 ) { TreeNode topNode = deque[tail - 1 ]; if (topNode.val > node.val) { deque[tail++] = node; topNode.right = node; break ; } else { deque[--tail] = null ; node.left = topNode; } } if (tail == 0 ) deque[tail++] = node; } return deque[0 ]; } }
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 class Solution { public TreeNode insertIntoMaxTree (TreeNode root, int val) { if (root == null ) { return new TreeNode (val); } if (root.val < val) { TreeNode temp = root; root = new TreeNode (val); root.left = temp; } else { root.right = insertIntoMaxTree(root.right, val); } return root; } } class Solution { public TreeNode insertIntoMaxTree (TreeNode root, int val) { if (root == null || root.val < val){ return new TreeNode (val, root, null ); } root.right = insertIntoMaxTree(root.right, val); return root; } }
给你两棵二叉树: root1 和 root2 。
想象一下,当你将其中一棵覆盖到另一棵之上时,两棵树上的一些节点将会重叠(而另一些不会)。你需要将这两棵树合并成一棵新二叉树。合并的规则是:如果两个节点重叠,那么将这两个节点的值相加作为合并后节点的新值;否则,不为 null 的节点将直接作为新二叉树的节点。
返回合并后的二叉树。注意: 合并过程必须从两个树的根节点开始。
示例 1:
1 2 输入:root1 = [1,3,2,5], root2 = [2,1,3,null,4,null,7] 输出:[3,4,5,5,4,null,7]
示例 2:
1 2 输入:root1 = [1], root2 = [1,2] 输出:[2,2]
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 class Solution { public TreeNode mergeTrees (TreeNode root1, TreeNode root2) { if (root1 == null ){ return root2; } if (root2 == null ){ return root1; } TreeNode root = new TreeNode (root1.val + root2.val); root.left = mergeTrees(root1.left, root2.left); root.right = mergeTrees(root1.right, root2.right); return root; } } class Solution { public TreeNode mergeTrees (TreeNode root1, TreeNode root2) { if (root1 == null ) { return root2; } if (root2 == null ) { return root1; } root1.val += root2.val; root1.left = mergeTrees(root1.left, root2.left); root1.right = mergeTrees(root1.right, root2.right); return root1; } }
给你二叉树的根结点 root ,请你将它展开为一个单链表:
展开后的单链表应该同样使用 TreeNode ,其中 right 子指针指向链表中下一个结点,而左子指针始终为 null 。
展开后的单链表应该与二叉树 先序遍历
**进阶:**你可以使用原地算法(O(1) 额外空间)展开这棵树吗?
示例 1:
1 2 输入:root = [1,2,5,3,4,null,6] 输出:[1,null,2,null,3,null,4,null,5,null,6]
示例 2:
示例 3:
思路
将 root 左子树和右子树拉平
将 root 的右子树接到左子树下方,然后将整个左子树作为右子树。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 class Solution { public void flatten (TreeNode root) { if (root == null ){ return ; } flatten(root.left); flatten(root.right); TreeNode left = root.left; TreeNode right = root.right; root.left = null ; root.right = left; TreeNode tmp = root; while (tmp.right != null ){ tmp = tmp.right; } tmp.right = right; } }
❼二叉树祖先
本题与剑指 Offer 68 - II. 二叉树的最近公共祖先 相同
给定一个二叉树, 找到该树中两个指定节点的最近公共祖先。
百度百科 中最近公共祖先的定义为:“对于有根树 T 的两个节点 p、q,最近公共祖先表示为一个节点 x,满足 x 是 p、q 的祖先且 x 的深度尽可能大(一个节点也可以是它自己的祖先 )。”
示例 1:
1 2 3 输入:root = [3,5,1,6,2,0,8,null,null,7,4], p = 5, q = 1 输出:3 解释:节点 5 和节点 1 的最近公共祖先是节点 3 。
示例 2:
1 2 3 输入:root = [3,5,1,6,2,0,8,null,null,7,4], p = 5, q = 4 输出:5 解释:节点 5 和节点 4 的最近公共祖先是节点 5 。因为根据定义最近公共祖先节点可以为节点本身。
示例 3:
1 2 输入:root = [1,2], p = 1, q = 2 输出:1
解析:
终止条件:
当越过叶节点,则直接返回 null ;
当 root 等于 p或q ,则直接返回 root ;
递推工作:
开启递归左子节点,返回值记为 left;
开启递归右子节点,返回值记为 right ;
返回值:
根据 left 和 right ,可展开为四种情况;
当 left 和 right 同时为空 :说明 root 的左 / 右子树中都不包含 p,q ,返回 null;
当 left 和 right 同时不为空 :说明 p,q 分列在 root 的 异侧 (分别在 左 / 右子树),因此 root 为最近公共祖先,返回 root ;
当 left
为空
,right
不为空
:p,q 都不在 root 的左子树中,直接返回 right 。具体可分为两种情况:
p,q 其中一个在 root 的 右子树 中,此时 right 指向 p(假设为 p );
p,q 两节点都在 root 的 右子树 中,此时的 right 指向 最近公共祖先节点 ;
当 left 不为空 , right 为空 :与情况 3. 同理;
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 class Solution { public TreeNode lowestCommonAncestor (TreeNode root, TreeNode p, TreeNode q) { if (root == null ) return null ; if (root == p || root == q) return root; TreeNode left = lowestCommonAncestor(root.left, p, q); TreeNode right = lowestCommonAncestor(root.right, p, q); if (left == null && right == null ) { return null ; } if (left != null && right != null ) { return root; } if (left == null ) return right; if (right == null ) return left; } }
本题与剑指 Offer 68 - I. 二叉搜索树的最近公共祖先 相同
给定一个二叉搜索树, 找到该树中两个指定节点的最近公共祖先。
百度百科 中最近公共祖先的定义为:“对于有根树 T 的两个结点 p、q,最近公共祖先表示为一个结点 x,满足 x 是 p、q 的祖先且 x 的深度尽可能大(一个节点也可以是它自己的祖先 )。”
例如,给定如下二叉搜索树: root = [6,2,8,0,4,7,9,null,null,3,5]
示例 1:
1 2 3 输入 : root = [6,2,8,0,4,7,9,null,null,3,5], p = 2, q = 8 输出 : 6 解释 : 节点 2 和节点 8 的最近公共祖先是 6。
示例 2:
1 2 3 输入 : root = [6,2,8,0,4,7,9,null,null,3,5], p = 2, q = 4 输出 : 2 解释 : 节点 2 和节点 4 的最近公共祖先是 2, 因为根据定义最近公共祖先节点可以为节点本身。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 class Solution { public TreeNode lowestCommonAncestor (TreeNode root, TreeNode p, TreeNode q) { if (root == null ) return null ; if (root.val > q.val && root.val > p.val) { return lowestCommonAncestor(root.left, p, q); } if (root.val < q.val && root.val < p.val) { return lowestCommonAncestor(root.right, p, q); } return root; } }
❽二叉搜索树
中序遍历会有序遍历 BST 的节点
解题框架
1 2 3 4 5 6 7 8 9 10 11 12 13 14 void BST (TreeNode root, int target) { if (root == null ) return ; if (root.val == target) { } if (root.val < target) { BST(root.right, target); } if (root.val > target) { BST(root.left, target); } }
给定二叉搜索树(BST)的根节点 root 和一个整数值 val。
你需要在 BST 中找到节点值等于 val 的节点。 返回以该节点为根的子树。 如果节点不存在,则返回 null 。
示例 1:
1 2 输入:root = [4,2,7,1,3], val = 2 输出:[2,1,3]
示例 2:
1 2 输入:root = [4,2,7,1,3], val = 5 输出:[]
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 class Solution { public TreeNode searchBST (TreeNode root, int target) { if (root == null ) { return null ; } if (root.val > target) { return searchBST(root.left, target); } if (root.val < target) { return searchBST(root.right, target); } return root; } } class Solution { public TreeNode searchBST (TreeNode root, int val) { while (root != null ) { if (val == root.val) { return root; } root = val < root.val ? root.left : root.right; } return null ; } }
给你一个二叉树的根节点 root ,判断其是否是一个有效的二叉搜索树。
有效 二叉搜索树定义如下:
节点的左子树只包含 小于 当前节点的数。
节点的右子树只包含 大于 当前节点的数。
所有左子树和右子树自身必须也是二叉搜索树。
示例 1:
1 2 输入:root = [2,1,3] 输出:true
示例 2:
1 2 3 输入:root = [5,1,4,null,null,3,6] 输出:false 解释:根节点的值是 5 ,但是右子节点的值是 4 。
误区:BST 不是左小右大么,那只要检查 root.val > root.left.val 且 root.val < root.right.val 不就行了?这样是不对的,因为 BST 左小右大的特性是指 root.val 要比左子树的所有节点都更大,要比右子树的所有节点都小,只检查左右两个子节点当然是不够的。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 class Solution { boolean isValidBST (TreeNode root) { return isValidBST(root, null , null ); } boolean isValidBST (TreeNode root, TreeNode min, TreeNode max) { if (root == null ) return true ; if (min != null && root.val <= min.val) return false ; if (max != null && root.val >= max.val) return false ; return isValidBST(root.left, min, root) && isValidBST(root.right, root, max); } }
给定一个二叉搜索树的根节点 root 和一个值 key ,删除二叉搜索树中的 key 对应的节点,并保证二叉搜索树的性质不变。返回二叉搜索树(有可能被更新)的根节点的引用。
一般来说,删除节点可分为两个步骤:
首先找到需要删除的节点;
如果找到了,删除它。
示例 1:
1 2 3 4 5 输入:root = [5,3,6,2,4,null,7], key = 3 输出:[5,4,6,2,null,null,7] 解释:给定需要删除的节点值是 3,所以我们首先找到 3 这个节点,然后删除它。 一个正确的答案是 [5,4,6,2,null,null,7], 如下图所示。 另一个正确答案是 [5,2,6,null,4,null,7]。
示例 2:
1 2 3 输入 : root = [5,3,6,2,4,null,7], key = 0 输出 : [5,3,6,2,4,null,7] 解释 : 二叉树不包含值为 0 的节点
示例 3:
1 2 输入 : root = [], key = 0 输出 : []
情况 1 :key 恰好是末端节点,两个子节点都为空,那么它可以当场去世了:
情况 2 :key 只有一个非空子节点,那么它要让这个孩子接替自己的位置:
情况 3 :key 有两个子节点,麻烦了,为了不破坏 BST 的性质,key 必须找到左子树中最大的那个节点或者右子树中最小的那个节点来接替自己,我的解法是用右子树中最小节点来替换:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 TreeNode deleteNode (TreeNode root, int key) { if (root == null ) return null ; if (root.val == key) { } else if (root.val > key) { root.left = deleteNode(root.left, key); } else if (root.val < key) { root.right = deleteNode(root.right, key); } return root; }
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 class Solution { public TreeNode deleteNode (TreeNode root, int key) { if (root == null ) return null ; if (root.val == key) { if (root.left == null ) return root.right; if (root.right == null ) return root.left; TreeNode minNode = getMin(root.right); root.right = deleteNode(root.right, minNode.val); minNode.left = root.left; minNode.right = root.right; root = minNode; } else if (root.val > key) { root.left = deleteNode(root.left, key); } else if (root.val < key) { root.right = deleteNode(root.right, key); } return root; } TreeNode getMin (TreeNode node) { while (node.left != null ) node = node.left; return node; } }
注意:
情况 3 时通过一系列略微复杂的链表操作交换 root 和 minNode 两个节点:
1 2 3 4 5 6 7 8 9 TreeNode minNode = getMin(root.right);root.right = deleteNode(root.right, minNode.val); minNode.left = root.left; minNode.right = root.right; root = minNode;
有的读者可能会疑惑,替换 root 节点为什么这么麻烦,直接改 val 字段不就行了?看起来还更简洁易懂:
1 2 3 4 5 6 7 TreeNode minNode = getMin(root.right);root.right = deleteNode(root.right, minNode.val); root.val = minNode.val;
仅对于这道算法题来说是可以的,但这样操作并不完美,我们一般不会通过修改节点内部的值来交换节点。因为在实际应用中,BST 节点内部的数据域是用户自定义的,可以非常复杂,而 BST 作为数据结构(一个工具人),其操作应该和内部存储的数据域解耦,所以我们更倾向于使用指针操作来交换节点,根本没必要关心内部数据。
给定二叉搜索树(BST)的根节点 root 和要插入树中的值 value ,将值插入二叉搜索树。 返回插入后二叉搜索树的根节点。 输入数据 保证 ,新值和原始二叉搜索树中的任意节点值都不同。
注意 ,可能存在多种有效的插入方式,只要树在插入后仍保持为二叉搜索树即可。 你可以返回 任意有效的结果
示例 1:
img
1 2 输入:root = [4,2,7,1,3], val = 5 输出:[4,2,7,1,3,5]
示例 2:
1 2 输入:root = [40,20,60,10,30,50,70], val = 25 输出:[40,20,60,10,30,50,70,null,null,25]
示例 3:
1 2 输入:root = [4,2,7,1,3,null,null,null,null,null,null], val = 5 输出:[4,2,7,1,3,5]
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 class Solution { public TreeNode insertIntoBST (TreeNode root, int val) { if (root == null ) return new TreeNode (val); if (root.val < val) { root.right = insertIntoBST(root.right, val); } if (root.val > val) { root.left = insertIntoBST(root.left, val); } return root; } } class Solution { public TreeNode insertIntoBST (TreeNode root, int val) { if (root == null ) { return new TreeNode (val); } TreeNode pos = root; while (pos != null ) { if (val < pos.val) { if (pos.left == null ) { pos.left = new TreeNode (val); break ; } else { pos = pos.left; } } else { if (pos.right == null ) { pos.right = new TreeNode (val); break ; } else { pos = pos.right; } } } return root; } }
本题与783. 二叉搜索树节点最小距离 相同
给你一个二叉搜索树的根节点 root ,返回 树中任意两不同节点值之间的最小差值 。
差值是一个正数,其数值等于两值之差的绝对值。
示例 1:
1 2 输入:root = [4,2,6,1,3] 输出:1
示例 2:
1 2 输入:root = [1,0,48,null,null,12,49] 输出:1
中序遍历会有序遍历 BST 的节点,遍历过程中计算最小差值即可。
使当前节点减去上个节点,比较差值,最小的就是答案。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 class Solution { public int getMinimumDifference (TreeNode root) { dfs(root); return res; } TreeNode prev = null ; int res = Integer.MAX_VALUE; void dfs (TreeNode root) { if (root == null ) return ; dfs(root.left); if (prev != null ) { res = Math.min(res, root.val - prev.val); } prev = root; dfs(root.right); } }
501. 二叉搜索树中的众数
给你一个含重复值的二叉搜索树(BST)的根节点 root ,找出并返回 BST 中的所有 众数 (即,出现频率最高的元素)。如果树中有不止一个众数,可以按 任意顺序 返回。
示例 1:
1 2 输入:root = [1,null,2,2] 输出:[2]
示例 2:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 class Solution { ArrayList<Integer> list = new ArrayList <>(); TreeNode prev = null ; int curCount = 0 ; int maxCount = 0 ; public int [] findMode(TreeNode root) { dfs(root); int [] res = new int [list.size()]; for (int i = 0 ; i < res.length; i++){ res[i] = list.get(i); } return res; } void dfs (TreeNode root) { if (root == null ) return ; dfs(root.left); if (prev == null ){ curCount = 1 ; maxCount = 1 ; list.add(root.val); } else if (root.val == prev.val){ curCount++; if (curCount == maxCount) { list.add(root.val); } else if (curCount > maxCount) { list.clear(); maxCount = curCount; list.add(root.val); } } else { curCount = 1 ; if (curCount == maxCount) { list.add(root.val); } } prev = root; dfs(root.right); } }
给你二叉搜索树的根节点 root ,同时给定最小边界low 和最大边界 high。通过修剪二叉搜索树,使得所有节点的值在[low, high]中。修剪树 不应该 改变保留在树中的元素的相对结构 (即,如果没有被移除,原有的父代子代关系都应当保留)。 可以证明,存在 唯一的答案 。
所以结果应当返回修剪好的二叉搜索树的新的根节点。注意,根节点可能会根据给定的边界发生改变。
示例 1:
1 2 输入:root = [1,0,2], low = 1, high = 2 输出:[1,null,2]
示例 2:
1 2 输入:root = [3,0,4,null,2,null,null,1], low = 1, high = 3 输出:[3,2,null,1]
如果一个节点的值没有落在 [lo, hi] 中,有两种情况:
1、root.val < lo,这种情况下 root 节点本身和 root 的左子树全都是小于 lo 的,都需要被剪掉
2、root.val > hi,这种情况下 root 节点本身和 root 的右子树全都是大于 hi 的,都需要被剪掉
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 class Solution { public TreeNode trimBST (TreeNode root, int low, int high) { if (root == null ) return null ; if (root.val < low) { return trimBST(root.right, low, high); } if (root.val > high) { return trimBST(root.left, low, high); } root.left = trimBST(root.left, low, high); root.right = trimBST(root.right, low, high); return root; } }
给你一个整数数组 nums ,其中元素已经按 升序 排列,请你将其转换为一棵 高度平衡 二叉搜索树。
高度平衡 二叉树是一棵满足「每个节点的左右两个子树的高度差的绝对值不超过 1 」的二叉树。
示例 1:
1 2 3 输入:nums = [-10,-3,0,5,9] 输出:[0,-3,9,-10,null,5] 解释:[0,-10,5,null,-3,null,9] 也将被视为正确答案:
示例 2:
1 2 3 输入:nums = [1,3] 输出:[3,1] 解释:[1,null,3] 和 [3,1] 都是高度平衡二叉搜索树。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 class Solution { public TreeNode sortedArrayToBST (int [] nums) { return build(nums, 0 , nums.length - 1 ); } TreeNode build (int [] nums, int left, int right) { if (left > right) return null ; int mid = left + ((right - left) >> 1 ); TreeNode root = new TreeNode (nums[mid]); root.left = build(nums, left, mid - 1 ); root.right = build(nums, mid + 1 , right); return root; } }
给定一个单链表的头节点 head ,其中的元素 按升序排序 ,将其转换为高度平衡的二叉搜索树。
本题中,一个高度平衡二叉树是指一个二叉树每个节点 的左右两个子树的高度差不超过 1。
示例 1:
1 2 3 输入 : head = [-10,-3,0,5,9] 输出 : [0,-3,9,-10,null,5] 解释 : 一个可能的答案是[0,-3,9,-10,null,5],它表示所示的高度平衡的二叉搜索树。
示例 2:
思路:
方法1:把链表转化成数组,然后直接复用 108. 将有序数组转换为二叉搜索树 的解法。
方法2:如果深刻理解二叉树算法,可以利用中序遍历的特点写出最优化的解法。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 class Solution { public TreeNode sortedListToBST (ListNode head) { int len = 0 , index = 0 ; for (ListNode p = head; p != null ; p = p.next) { len++; } int [] nums = new int [len]; for (ListNode p = head; p != null ; p = p.next) { nums[index++] = p.val; } return build(nums, 0 , len - 1 ); } TreeNode build (int [] nums, int left, int right) { if (left > right) return null ; int mid = left + ((right - left) >> 1 ); TreeNode root = new TreeNode (nums[mid]); root.left = build(nums, left, mid - 1 ); root.right = build(nums, mid + 1 , right); return root; } } class Solution { public TreeNode sortedListToBST (ListNode head) { int len = 0 ; for (ListNode p = head; p != null ; p = p.next) { len++; } cur = head; return inorderBuild(0 , len - 1 ); } ListNode cur; TreeNode inorderBuild (int left, int right) { if (left > right) { return null ; } int mid = (left + right) / 2 ; TreeNode leftTree = inorderBuild(left, mid - 1 ); TreeNode root = new TreeNode (cur.val); cur = cur.next; TreeNode rightTree = inorderBuild(mid + 1 , right); root.left = leftTree; root.right = rightTree; return root; } }
给你一棵二叉搜索树,请你返回一棵 平衡后 的二叉搜索树,新生成的树应该与原来的树有着相同的节点值。如果有多种构造方法,请你返回任意一种。
如果一棵二叉搜索树中,每个节点的两棵子树高度差不超过 1 ,我们就称这棵二叉搜索树是 平衡的 。
示例 1:
1 2 3 输入:root = [1,null,2,null,3,null,4,null,null] 输出:[2,1,3,null,null,null,4] 解释:这不是唯一的正确答案,[3,1,4,null,2,null,null] 也是一个可行的构造方案。
示例 2:
1 2 输入 : root = [2,1,3] 输出 : [2,1,3]
用中序遍历获取 BST 的有序列表,然后用 108. 将有序数组转换为二叉搜索树 的解法代码,将这个有序数组转化成平衡 BST。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 class Solution { ArrayList<Integer> res = new ArrayList <>(); public TreeNode balanceBST (TreeNode root) { traverse(root); return build(res, 0 , res.size() - 1 ); } void traverse (TreeNode root) { if (root == null ) { return ; } traverse(root.left); res.add(root.val); traverse(root.right); } TreeNode build (ArrayList<Integer> res, int left, int right) { if (left > right) return null ; int mid = left + (right - left) / 2 ; TreeNode root = new TreeNode (res.get(mid)); root.left = build(res, left, mid - 1 ); root.right = build(res, mid + 1 , right); return root; } }
1 2 3 4 5 6 7 8 9 10 11 12 class Solution { int sum = 0 ; public TreeNode convertBST (TreeNode root) { if (root == null ) return null ; convertBST(root.right); sum += root.val; root.val = sum; convertBST(root.left); return root; } }
给定一个二叉搜索树的根节点 root ,和一个整数 k ,请你设计一个算法查找其中第 k 个最小元素(从 1 开始计数)。
示例 1:
1 2 输入:root = [3,1,4,null,2], k = 1 输出:1
示例 2:
1 2 输入:root = [5,3,6,2,4,null,null,1], k = 3 输出:3
BST 的中序遍历结果是有序的(升序),所以用一个外部变量记录中序遍历结果第 k 个元素即是第 k 小的元素。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 class Solution { public int kthSmallest (TreeNode root, int k) { dfs(root, k); return res; } int res = 0 ; int rank = 0 ; void dfs (TreeNode root, int k) { if (root == null ) { return ; } dfs(root.left, k); rank++; if (k == rank) { res = root.val; return ; } dfs(root.right, k); } }
层序遍历相关题目
给你二叉树的根节点 root ,返回其节点值 自底向上的层序遍历 。 (即按从叶子节点所在层到根节点所在的层,逐层从左向右遍历)
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 class Solution { public List<List<Integer>> levelOrderBottom (TreeNode root) { List<List<Integer>> res = new ArrayList <List<Integer>>(); if (root == null ) { return res; } Queue<TreeNode> queue = new LinkedList <TreeNode>(); queue.offer(root); while (!queue.isEmpty()) { List<Integer> level = new ArrayList <Integer>(); int currentLevelSize = queue.size(); for (int i = 1 ; i <= currentLevelSize; ++i) { TreeNode node = queue.poll(); level.add(node.val); if (node.left != null ) { queue.offer(node.left); } if (node.right != null ) { queue.offer(node.right); } } res.add(0 , level); } return res; } }
给定一个非空二叉树的根节点 root , 以数组的形式返回每一层节点的平均值。
示例 1:
1 2 输入:root = [3,9,20,null,null,15,7] 输出:[3.00000,14.50000,11.00000]
示例 2:
1 2 输入:root = [3,9,20,15,7] 输出:[3.00000,14.50000,11.00000]
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 class Solution { public List<Double> averageOfLevels (TreeNode root) { List<Double> res = new ArrayList <>(); if (root == null ) return res; Queue<TreeNode> queue = new LinkedList <>(); queue.offer(root); while (!queue.isEmpty()){ int n = queue.size(); double sum = 0 ; for (int i = 0 ; i < n; i++){ TreeNode node = queue.poll(); sum += node.val; if (node.left != null ) queue.offer(node.left); if (node.right != null ) queue.offer(node.right); } res.add(sum / n); } return res; } }
给定一个 N 叉树,返回其节点值的层序遍历 。(即从左到右,逐层遍历)。
树的序列化输入是用层序遍历,每组子节点都由 null 值分隔(参见示例)。
示例 1:
示例 2:
1 2 输入:root = [1 ,null ,2 ,3 ,4 ,5 ,null ,null ,6 ,7 ,null ,8 ,null ,9 ,10 ,null ,null ,11 ,null ,12 ,null ,13 ,null ,null ,14 ] 输出:[[1 ],[2 ,3 ,4 ,5 ],[6 ,7 ,8 ,9 ,10 ],[11 ,12 ,13 ],[14 ]]
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 class Solution { public List<List<Integer>> levelOrder (Node root) { List<List<Integer>> res = new ArrayList <>(); if (root == null ) return res; Queue<Node> queue = new LinkedList <>(); queue.offer(root); while (!queue.isEmpty()){ int n = queue.size(); List<Integer> level = new ArrayList <>(); for (int i = 0 ; i < n; i++){ Node node = queue.poll(); level.add(node.val); for (Node child : node.children){ queue.offer(child); } } res.add(level); } return res; } }
给定一棵二叉树的根节点 root ,请找出该二叉树中每一层的最大值。
示例1:
1 2 输入 : root = [1,3,2,5,3,null,9] 输出 : [1,3,9]
示例2:
1 2 输入 : root = [1,2,3] 输出 : [1,3]
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 class Solution { public List<Integer> largestValues (TreeNode root) { List<Integer> res = new ArrayList <>(); if (root ==null ) return res; Queue<TreeNode> queue = new LinkedList <>(); queue.offer(root); while (!queue.isEmpty()){ int n = queue.size(); int levelMax = Integer.MIN_VALUE; for (int i = 0 ; i < n; i++){ TreeNode cur = queue.poll(); levelMax = Math.max(levelMax, cur.val); if (cur.left != null ) queue.offer(cur.left); if (cur.right != null ) queue.offer(cur.right); } res.add(levelMax); } return res; } }
给定一个 完美二叉树 ,其所有叶子节点都在同一层,每个父节点都有两个子节点。二叉树定义如下:
1 2 3 4 5 6 struct Node { int val; Node *left; Node *right; Node *next; }
填充它的每个 next 指针,让这个指针指向其下一个右侧节点。如果找不到下一个右侧节点,则将 next 指针设置为 NULL。初始状态下,所有 next 指针都被设置为 NULL。
示例 1:
1 2 3 输入:root = [1,2,3,4,5,6,7] 输出:[1,#,2,3,#,4,5,6,7,#] 解释:给定二叉树如图 A 所示,你的函数应该填充它的每个 next 指针,以指向其下一个右侧节点,如图 B 所示。序列化的输出按层序遍历排列,同一层节点由 next 指针连接,'#' 标志着每一层的结束。
示例 2:
进阶:
你只能使用常量级额外空间。
使用递归解题也符合要求,本题中递归程序占用的栈空间不算做额外的空间复杂度。
方法一:层序遍历
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 class Solution { public Node connect (Node root) { if (root == null ){ return root; } Queue<Node> queue = new LinkedList <>(); queue.offer(root); while (!queue.isEmpty()){ int n = queue.size(); for (int i = 0 ; i < n; i++){ Node node = queue.poll(); if (i < n - 1 ){ node.next = queue.peek(); } if (node.left != null ) queue.offer(node.left); if (node.right != null ) queue.offer(node.right); } } return root; } }
方法二:使用已建立的 next 指针
一棵树中,存在两种类型的 next 指针。
第一种情况是连接同一个父节点的两个子节点。可以通过同一个节点直接访问到,执行下面操作即可完成连接。
1 node.left.next = node.right
第二种情况在不同父亲的子节点之间建立连接,这种情况不能直接连接。如果我们能将这一层的上一层串联好。那么可以通过父节点的next找到邻居,完成串联。
1 root.right.next == root.next.left
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 class Solution { public Node connect (Node root) { if (root == null ) { return root; } Node leftmost = root; while (leftmost.left != null ) { Node head = leftmost; while (head != null ) { head.left.next = head.right; if (head.next != null ) { head.right.next = head.next.left; } head = head.next; } leftmost = leftmost.left; } return root; } }
给定一个 完美二叉树 ,其所有叶子节点都在同一层,每个父节点都有两个子节点。二叉树定义如下:
1 2 3 4 5 6 struct Node { int val; Node *left; Node *right; Node *next; }
填充它的每个 next 指针,让这个指针指向其下一个右侧节点。如果找不到下一个右侧节点,则将 next 指针设置为 NULL。
初始状态下,所有 next 指针都被设置为 NULL。
示例 1:
1 2 3 输入:root = [1,2,3,4,5,6,7] 输出:[1,#,2,3,#,4,5,6,7,#] 解释:给定二叉树如图 A 所示,你的函数应该填充它的每个 next 指针,以指向其下一个右侧节点,如图 B 所示。序列化的输出按层序遍历排列,同一层节点由 next 指针连接,'#' 标志着每一层的结束。
示例 2:
方法1:层序遍历
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 class Solution { public Node connect (Node root) { if (root == null ){ return root; } Queue<Node> queue = new LinkedList <>(); queue.offer(root); while (!queue.isEmpty()){ int n = queue.size(); for (int i = 0 ; i < n; i++){ Node node = queue.poll(); if (i < n - 1 ){ node.next = queue.peek(); } if (node.left != null ) queue.offer(node.left); if (node.right != null ) queue.offer(node.right); } } return root; } }
方法二:使用已建立的 next 指针
1 2 cur.left.next = cur.right; cur.right.next = cur.next.left;
。。。
给你一个二叉树的根节点 root。设根节点位于二叉树的第 1 层,而根节点的子节点位于第 2 层,依此类推。
请返回层内元素之和 最大 的那几层(可能只有一层)的层号,并返回其中 最小 的那个。
示例 1:
1 2 3 4 5 6 7 输入:root = [1,7,0,7,-8,null,null] 输出:2 解释: 第 1 层各元素之和为 1, 第 2 层各元素之和为 7 + 0 = 7, 第 3 层各元素之和为 7 + -8 = -1, 所以我们返回第 2 层的层号,它的层内元素之和最大。
示例 2:
1 2 输入:root = [989,null,10250,98693,-89388,null,null,null,-32127] 输出:2
使用BFS广搜来遍历树的每层,计算每层的节点总和并维护遍历层级过程中的节点总和最大值和深度。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 class Solution { public int maxLevelSum (TreeNode root) { int maxValue = Integer.MIN_VALUE; int maxDeep = 1 ; int deep = 1 ; Queue<TreeNode> queue = new LinkedList <>(); queue.offer(root); while (!queue.isEmpty()){ int n = queue.size(); int levelSum = 0 ; for (int i = 0 ; i < n; i++){ TreeNode node = queue.poll(); levelSum += node.val; if (node.left != null ){ queue.offer(node.left); } if (node.right != null ){ queue.offer(node.right); } } if (levelSum > maxValue){ maxValue = levelSum; maxDeep = deep; } deep++; } return maxDeep; } }
⑧图
图这种数据结构有一些比较特殊的算法,比如二分图判断,有环图无环图的判断,拓扑排序,以及最经典的最小生成树,单源最短路径问题,更难的就是类似网络流这样的问题。
参考:图论基础及遍历算法 、二分图判定算法 、环检测和拓扑排序 、图遍历算法 、名流问题 、并查集算法计算连通分量 、Dijkstra 最短路径算法
图论基础
「图」的两种表示方法,邻接表 (链表),邻接矩阵 (二维数组)。
邻接矩阵判断连通性迅速,并可以进行矩阵运算解决一些问题,但是如果图比较稀疏的话很耗费空间。
邻接表比较节省空间,但是很多操作的效率上肯定比不过邻接矩阵。
邻接表 把每个节点 x 的邻居都存到一个列表里,然后把 x 和这个列表关联起来,这样就可以通过一个节点 x 找到它的所有相邻节点。
邻接矩阵 则是一个二维布尔数组,我们权且称为 matrix,如果节点 x 和 y 是相连的,那么就把 matrix[x][y] 设为 true(上图中绿色的方格代表 true)。如果想找节点 x 的邻居,去扫一圈 matrix[x][..] 就行了。
如果用代码的形式来表现,邻接表和邻接矩阵大概长这样:
1 2 3 4 5 6 7 List<Integer>[] graph; boolean [][] matrix;
邻接表建立
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 List<Integer>[] buildGraph(int x, int [][] edges) { List<Integer>[] graph = new LinkedList [x]; for (int i = 0 ; i < x; i++) { graph[i] = new LinkedList <>(); } for (int [] edge : edges) { int from = edge[1 ], to = edge[0 ]; graph[from].add(to); } return graph; }
图遍历
图和多叉树最大的区别是,图是可能包含环的,你从图的某一个节点开始遍历,有可能走了一圈又回到这个节点,而树不会出现这种情况,从某个节点出发必然走到叶子节点,绝不可能回到它自身。
所以,如果图包含环,遍历框架就要一个 visited 数组进行辅助:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 boolean [] visited;boolean [] onPath;void traverse (Graph graph, int s) { if (visited[s]) return ; visited[s] = true ; onPath[s] = true ; for (int neighbor : graph[s] { traverse(graph, neighbor); } onPath[s] = false ; }
环检测
类比贪吃蛇游戏,visited 记录蛇经过过的格子,而 onPath 仅仅记录蛇身。onPath 用于判断是否成环,类比当贪吃蛇自己咬到自己(成环)的场景。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 boolean [] onPath;boolean [] visited;boolean hasCycle = false ;void traverse (List<Integer>[] graph, int s) { if (onPath[s]) { hasCycle = true ; } if (visited[s] || hasCycle) { return ; } visited[s] = true ; onPath[s] = true ; for (int neighbor : graph[s]) { traverse(graph, neighbor); } onPath[s] = false ; }
给你一个有 n 个节点的 有向无环图(DAG) ,请你找出所有从节点 0 到节点 n-1 的路径并输出(不要求按特定顺序 )
graph[i] 是一个从节点 i 可以访问的所有节点的列表(即从节点 i 到节点 graph[i][j]存在一条有向边)。
示例 1:
1 2 3 输入:graph = [[1,2],[3],[3],[]] 输出:[[0,1,3],[0,2,3]] 解释:有两条路径 0 -> 1 -> 3 和 0 -> 2 -> 3
示例 2:
1 2 输入:graph = [[4,3,1],[3,2,4],[3],[4],[]] 输出:[[0,4],[0,3,4],[0,1,3,4],[0,1,2,3,4],[0,1,4]]
以 0 为起点遍历图,同时记录遍历过的路径,当遍历到终点时将路径记录下来即可 。
既然输入的图是无环的,就不需要 visited 数组辅助了,直接套用图的遍历框架:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 class Solution { List<List<Integer>> res = new LinkedList <>(); public List<List<Integer>> allPathsSourceTarget (int [][] graph) { LinkedList<Integer> path = new LinkedList <>(); traverse(graph, 0 , path); return res; } void traverse (int [][] graph, int s, LinkedList<Integer> path) { path.addLast(s); int n = graph.length; if (s == n - 1 ) { res.add(new LinkedList <>(path)); } for (int v : graph[s]) { traverse(graph, v, path); } path.removeLast(); } }
你这个学期必须选修 numCourses 门课程,记为 0 到 numCourses - 1 。
在选修某些课程之前需要一些先修课程。 先修课程按数组 prerequisites 给出,其中 prerequisites[i] = [ai, bi] ,表示如果要学习课程 ai 则 必须 先学习课程 bi 。
例如,先修课程对 [0, 1] 表示:想要学习课程 0 ,你需要先完成课程 1 。
请你判断是否可能完成所有课程的学习?如果可以,返回 true ;否则,返回 false 。
示例 1:
1 2 3 输入:numCourses = 2, prerequisites = [[1,0]] 输出:true 解释:总共有 2 门课程。学习课程 1 之前,你需要完成课程 0 。这是可能的。
示例 2:
1 2 3 输入:numCourses = 2, prerequisites = [[1,0],[0,1]] 输出:false 解释:总共有 2 门课程。学习课程 1 之前,你需要先完成课程 0 ;并且学习课程 0 之前,你还应先完成课程 1 。这是不可能的。
什么时候无法修完所有课程?当存在循环依赖的时候。参考:环检测及拓扑排序算法
看到依赖问题,首先把问题转化成「有向图」这种数据结构,只要图中存在环,那就说明存在循环依赖 。
具体来说,我们首先可以把课程看成「有向图」中的节点,节点编号分别是 0, 1, ..., numCourses-1,把课程之间的依赖关系看做节点之间的有向边。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 class Solution { boolean [] onPath; boolean [] visited; boolean hasCycle = false ; boolean canFinish (int numCourses, int [][] prerequisites) { List<Integer>[] graph = buildGraph(numCourses, prerequisites); visited = new boolean [numCourses]; onPath = new boolean [numCourses]; for (int i = 0 ; i < numCourses; i++) { traverse(graph, i); } return !hasCycle; } void traverse (List<Integer>[] graph, int s) { if (onPath[s]) { hasCycle = true ; } if (visited[s] || hasCycle) { return ; } visited[s] = true ; onPath[s] = true ; for (int neighbor : graph[s]) { traverse(graph, neighbor); } onPath[s] = false ; } List<Integer>[] buildGraph(int numCourses, int [][] prerequisites) { List<Integer>[] graph = new LinkedList [numCourses]; for (int i = 0 ; i < numCourses; i++) { graph[i] = new LinkedList <>(); } for (int [] edge : prerequisites) { int from = edge[1 ], to = edge[0 ]; graph[from].add(to); } return graph; } }
猴子爬树-最短路径-华为 2023 暑期实习
给定一棵树,这个树有n个节点,节点编号从0开始依次递增,0固定为根节点。在这棵树上有一个小猴子,初始时该猴子位于根节点(0号) 上,小猴子一次可以沿着树上的边从一个节点挪到另一个节点,但这棵树上有一些节点设置有障碍物,如果某个节点上设置了障碍物,小猴子就不能通过连接该节点的边挪动到该节点上。问小猴子是否能跑到树的叶子节点(叶子节点定义为只有一条边连接的节点),如果可以,请输出小猴子跑到叶子节点的最短路径(通过的边最少),否则输出字符串NULL。
输入
第一行给出数字n,表示这个树有n个节点,节点编号从0开始依次递增,0固定为根节点,1<=n<10000
第二行给出数字edge,表示接下来有edge行,每行是一条边
接下来的edge行是边: x y,表示x和y节点有一条边连接
边信息结束后接下来的一行给出数字block,表示接下来有block行,每行是个障碍物
接下来的block行是障碍物: X,表示节点x上存在障碍物
输出
如果小猴子能跑到树的叶子节点,请输出小猴子跑到叶子节点的最短路径(通过的边最少),比如小猴子从0经过1到达2 (叶子节点) ,那么输出“0->1->2”,否则输出“NULL”。注意如果存在多条最短路径,请按照节点序号排序输出,比如0->1和0->3两条路径,第一个节点0一样,则比较第二个节点1和3,1比3小,因此输出0->1这条路径。再如 0->5->2->3 和0->5->1->4,则输出 0->5-31->4
样例1
1 2 3 4 5 6 7 8 9 10 11 输入 : 4 节点 3 边数 0 1 边 0 2 边 0 3 边 2 障碍个数 2 障碍 3 障碍 输出 : 0->1 解释 : n=4,edge=[[0,1],[0,2],[0,3]],block=[2,3]表示一个有4个节点、3条边的树,其中节点2和节点3上有障碍物,小猴子能从0到达叶子节点1 (节点1只有一条边[1,0]和它连接,因此是叶子节点) ,即可以跑出这个树,所以输出为0->1。
样例2
1 2 3 4 5 6 7 8 9 10 11 输入 : 7 6 0 1 0 3 1 2 3 4 1 5 5 6 1 输出 : 0->1->2 解释 : 节点4上有障碍物,因此0-3-4这条路不通,节点2和节点6都是叶子节点,但0->1->2比0->1->5->6路径短(通过的边最少) ,因此输出为0->1->2
样例3
1 2 3 4 5 6 7 输入 : 2 1 0 1 1 1 输出 : NULL 解释 :节点1是叶子节点,但存在障碍物,因此小猴子无法到达叶子节点,输出NULL
样例4
1 2 3 4 5 6 7 8 9 输入 :4 3 0 1 0 2 0 3 1 2 输出 : 0->1 解释 : n=4,edge=[[0,1],[0,2],[0,3]],block=[2] 表示一个有4个节点、3条边的树,其中节点2上有障碍物,小猴子能从0到达叶子节点1 (节点1只有一条边[0,1]和它连接,因此是叶子节点) ,路径是0->1,也能从0到达叶子节点3(节点3只有一条边[0,3]和它连接,因此是叶子节点) ,路径是0->3,因此按通过节点的顺序及序号比较选择 0->1。
华为0419暑期实习笔试算法解析 (qq.com)
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 public class Main { public static void main (String[] args) { Scanner scanner = new Scanner (System.in); int n = scanner.nextInt(); int m = scanner.nextInt(); ArrayList<Integer>[] edge = new ArrayList [n]; boolean [] visited = new boolean [n]; int [] barriers = new int [n]; for (int i = 0 ; i < n; i++) { edge[i] = new ArrayList <>(); } for (int i = 0 ; i < m; i++) { int u = scanner.nextInt(); int v = scanner.nextInt(); edge[u].add(v); edge[v].add(u); } int k = scanner.nextInt(); for (int i = 0 ; i < k; i++) { int node = scanner.nextInt(); barriers[node] = 1 ; } String path = shortPath(0 ,edge,visited,barriers); System.out.println(path == null ? "NULL" :path); } public static String shortPath (int node, ArrayList<Integer>[] edge, boolean [] visited, int [] barriers) { if (barriers[node] == 1 ){ return null ; } visited[node] = true ; if (edge[node].size() == 1 && node != 0 ){ return Integer.toString(node); } String shortPath = null ; for (int neighbor: edge[node]) { if (!visited[neighbor]){ String path = shortPath(neighbor, edge, visited, barriers); if (path != null ){ String fullPath = node + "->" + path; if (shortPath == null || fullPath.length() < shortPath.length()){ shortPath = fullPath; } } } } return shortPath; } }